6727-109858-02 MODIFIED INTERFERON-GAMMA (IFN-G) RECEPTORS (IFNGR) TO ENHANCE CELL-BASED IMMUNOTHERAPY CROSS REFERENCE TO RELATED APPLICATIONS This application claims the benefit of U.S. Provisional Application No.63/542,833, filed October 6, 2023, which is herein incorporated by reference in its entirety. FIELD This disclosure concerns chimeric polypeptides that include an interferon-gamma receptor (IFNGR) extracellular domain, a transmembrane domain and a heterologous intracellular signaling domain, immune cells expressing such chimeric polypeptides, and their use for cancer immunotherapy. INCORPORATION OF ELECTRONIC SEQUENCE LISTING The electronic sequence listing, submitted herewith as an XML file named Sequence.xml (362,052 bytes), created on September 25, 2024, is herein incorporated by reference in its entirety. BACKGROUND Interferon-gamma (IFN-γ) is a key cytokine involved with antitumor responses. A major source of IFN-γ is T cells, which produce and secrete IFN-γ upon recognition of antigen. Natural killer (NK) and NKT cells can also produce IFN-γ. This cytokine can directly act on tumor cells to inhibit cell proliferation and induce cell death upon binding its cognate receptor which is comprised of IFN-γ receptor 1 (IFNGR1) and IFNGR2. IFN-γ can also upregulate major histocompatibility complex (MHC) molecules on tumor cells and antigen presenting cells (APCs) to enhance antitumor T-cell responses. However, IFNGR signaling in T cells can also inhibit their proliferation and promote cell death. SUMMARY Described herein are modified IFNGRs (e.g., IFNG chimeric receptors) that can be engineered into immune cells, such as T cells, to enhance their activity. In some aspects, the IFNG chimeric receptors include the extracellular domain of IFNGR1 and/or IFNGR2 fused to the intracellular domains of other cytokine receptors, such as the interleukin-2 receptor, which promotes T cell activity. Upon activation, immune cells expressing the IFNG chimeric receptors secrete IFN-γ, which binds to the IFNG chimeric receptors and transmits signals that enhance the proliferation and/or function of the engineered immune cells. Such engineered immune cells can be used, for example, to enhance cancer immunotherapy. Provided herein are nucleic acid molecules that encode a first chimeric polypeptide that includes an interferon gamma receptor 1 (IFNGR1) extracellular domain, a first transmembrane domain, and a first intracellular signaling domain. In some aspects, the first intracellular signaling domain is a heterologous
6727-109858-02 signaling domain of a cytokine receptor. In other aspects, the first intracellular signaling domain is a modified IFNGR1 intracellular signaling domain. Also provided are nucleic acid molecules that encode a first chimeric polypeptide as described above and further encode a second chimeric polypeptide that includes an interferon gamma receptor 2 (IFNGR2) extracellular domain, a second transmembrane domain, and a second intracellular signaling domain. In some aspects, the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor. In other aspects, the second intracellular signaling domain is an IFNGR2 intracellular signaling domain, such as a wild-type IFNGR2 intracellular signaling domain. In some aspects the first chimeric polypeptide and the second chimeric polypeptide are encoded by a single nucleic acid molecule and the coding sequence for the first chimeric polypeptide and the coding sequence for the second chimeric polypeptide are separated by a nucleic acid sequence encoding a self-cleaving peptide. In other aspects, the first chimeric polypeptide is encoded by a first nucleic acid molecule and the second chimeric polypeptide is encoded by a second nucleic acid molecule. In some examples, the first and/or second intracellular signaling domains are heterologous intracellular signaling domains from a cytokine receptor. Exemplary cytokine receptors include, but are not limited to, erythropoietin receptor (EPOR), growth hormone receptor (GHR), thrombopoietin receptor (TPOR), prolactin receptor (PRLR), leptin receptor (LEPR), thymic stromal lymphopoietin receptor (TSLPR), colony stimulating factor 2 receptor subunit beta (CSF2RB), interleukin 3 receptor subunit alpha (IL3RA), interleukin 2 receptor subunit beta (IL2RB), interleukin 7 receptor (IL7R), interleukin 9 receptor (IL9R), insulin receptor (INSR), membrane glycoprotein 130 (GP130), CD28, 4-1BB, inducible T cell costimulator (ICOS), CD2, toll-like receptor 1 (TLR1), toll-like receptor 2 (TLR2), toll-like receptor 4 (TLR4), toll-like receptor 6 (TLR6), epidermal growth factor receptor (EGFR), insulin-like growth factor 1 receptor (IGF1R), MET proto-oncogene receptor tyrosine kinase (MET), ROS1 proto-oncogene 1 receptor tyrosine kinase (ROS1), granulocyte-macrophage colony stimulating factor receptor alpha (GMCSFRA), interleukin 2 receptor subunit gamma (IL2RG), interleukin 6 receptor (IL6R), interleukin 11 receptor subunit alpha (IL11RA), oncostatin M receptor (OSMRB), interleukin 10 receptor subunit alpha (IL10RA), interleukin 10 receptor subunit beta (IL10RB), interleukin 22 receptor (IL22R), interleukin 20 receptor subunit alpha (IL20RA), and interleukin 20 receptor subunit beta (IL20RB). In other examples, the first intracellular signaling domain is a modified IFNGR1 signaling domain and/or the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. In some examples, the transmembrane domain of the first chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR1), such as a transmembrane domain from the same cytokine receptor as the first intracellular signaling domain and/or the transmembrane domain of the second chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR2), such as a transmembrane domain from the same cytokine receptor as the second intracellular signaling domain. In other examples, the transmembrane domain of the first chimeric
6727-109858-02 polypeptide is an IFNGR1 transmembrane domain and/or the transmembrane domain of the second chimeric polypeptide is an IFNGR2 transmembrane domain. In some examples, the nucleic acid molecules are codon-optimized for expression in mammalian cells, such as human cells. Also provided herein are vectors that include a disclosed nucleic acid molecule or molecules and modified immune cells that include a nucleic acid molecule(s) or vector disclosed herein. Further provided herein are modified immune cells that express a first chimeric polypeptide that includes an IFNGR1 extracellular domain, a first transmembrane domain, and a first intracellular signaling domain. In some aspects, the first intracellular signaling domain is a heterologous signaling domain of a cytokine receptor, such as signaling domain of any of the cytokine receptors listed above. In other aspects, the first intracellular signaling domain is a modified IFNGR1 intracellular signaling domain. Also provided are modified immune cells that express a first chimeric polypeptide as described above and further express a second chimeric polypeptide that includes an IFNGR2 extracellular domain, a second transmembrane domain, and a second intracellular signaling domain. In some aspects, the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor, such as signaling domain of any of the cytokine receptors listed above. In other aspects, the second intracellular signaling domain is an IFNGR2 intracellular signaling domain, for example a wild-type IFNGR2 intracellular signaling domain. In some examples, the transmembrane domain of the first chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR1), such as a transmembrane domain from the same cytokine receptor as the first intracellular signaling domain and/or the transmembrane domain of the second chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR2), such as a transmembrane domain from the same cytokine receptor as the second intracellular signaling domain. In other examples, the transmembrane domain of the first chimeric polypeptide is an IFNGR1 transmembrane domain and/or the transmembrane domain of the second chimeric polypeptide is an IFNGR2 transmembrane domain. Also provided are pharmaceutical compositions that include a modified immune cell disclosed herein and a pharmaceutically acceptable carrier. Further provided are methods of treating cancer in a subject. In some aspects, the method includes administering to the subject a therapeutically effective amount of a modified immune cell or pharmaceutical composition disclosed herein. In some examples, the method further includes administering one or more additional anti-cancer therapies to the subject. The foregoing and other features of this disclosure will become more apparent from the following detailed description of several aspects which proceeds with reference to the accompanying figures.
6727-109858-02 BRIEF DESCRIPTION OF THE DRAWINGS FIG.1: General schematic of wild-type (i) and exemplary chimeric IFNGRs (ii-v). The IFNGR is comprised of two homodimers of IFNGR1 (R1) and IFNGR2 (R2) that are activated upon binding to IFN-γ. Chimeric IFNGRs include extracellular domains from the IFNGR fused to cytoplasmic signaling domains from other receptors that can activate pathways that enhance T-cell activity. Entire cytoplasmic domains (e.g., ii, iii, iv) or parts of cytoplasmic domains (e.g., v) from other receptors can be used. The transmembrane domain (TMD) can be derived from any receptor (e.g., from the IFNGR or the signaling receptor). FIGS.2A-2C: Biochemical signaling of IFNG chimeric receptors. T cells were transduced with a retroviral vector encoding the KRAS G12D-reactive TCR alone (FIG.2A), and co-transduced with either a retroviral vector encoding an IFNG chimeric receptor containing the IFNGR1 extracellular domain fused to the IL-2 receptor beta chain transmembrane and cytoplasmic domains and the IFNGR2 extracellular domain fused to the common gamma chain transmembrane and cytoplasmic domains (IFNGR/IL2R) (FIG.2B), or a retroviral vector encoding an IFNG receptor containing the IFNGR1 extracellular domain fused to the common beta chain cytoplasmic and transmembrane domains and the IFNGR2 extracellular domain fused to the GMCSF receptor alpha transmembrane and cytoplasmic domains (IFNGR/GMCSFR) (FIG.2C). To evaluate whether these cells could activate STAT5, which is a key transcription factor involved in IL2R and GMCSFR signaling, cells were washed, and rested overnight in media without exogenous cytokines. Cells were then stimulated with nothing (no stim), 300 IU/ml IL-2 (positive control), or titrating doses of IFNG. Thirty minutes after stimulation, cells were fixed and permeabilized with cold methanol and stained with antibodies specific for phosphorylated STAT5 (P-STAT5). Cells were washed and analyzed by flow cytometry. Data were gated on CD8+mTCRb+ transduced T cells. FIGS.3A-3C: In vitro cytotoxicity of chimeric IFNG receptors against a pancreatic cancer cell line. T cells were transduced to express the KRAS G12D-reactive TCR alone (FIG.3A), and co-transduced to express either an IFNG chimeric receptor containing the IFNGR1 extracellular domain fused to the IL-2 receptor beta chain transmembrane and cytoplasmic domains and the IFNGR2 extracellular domain fused to the common gamma chain transmembrane and cytoplasmic domains (IFNGR/IL2R) (FIG.3B), or an IFNG receptor containing the IFNGR1 extracellular domain fused to the common beta chain cytoplasmic and transmembrane domains and the IFNGR2 extracellular domain fused to the GMCSF receptor alpha transmembrane and cytoplasmic domains (IFNGR/GMCSFR) (FIG.3C). These cells then underwent a “serial kill” assay in which the T cells were initially cocultured at 5:1 E:T (50,000 T cells, 10,000 tumor cells) with the HPAC pancreatic cancer cell line that was genetically engineered to express GFP. An additional 10,000 HPAC-GFP cells were added about every 2 days, 5 times total, until the end of the assay. (FIG.3A) GFP fluorescence (as a measure of tumor cell growth) of the KRAS-G12D-positive and HLA- C*08:02-positive HPAC-GFP pancreatic cancer cell line in the presence of T cells transduced to express the HLA-C*08:02-restricted KRAS-G12D reactive TCR without (circles) or with 300 IU/ml IL-2 (squares). (FIGS.3B-3C) GFP fluorescence of the KRAS-G12D-positive and HLA-C*08:02-positive HPAC-GFP
6727-109858-02 pancreatic cancer cell line in the presence of T cells co-transduced to express the HLA-C*08:02-restricted KRAS-G12D reactive TCR and IFNGR/IL2R chimeric receptors (FIG.3B, triangles) or IFNGR/GMCSFR chimeric receptors (FIG.3C, triangles). No exogenous cytokines were added to the coculture. The data from FIG.3A are incorporated into FIG.3B and FIG.3C to facilitate comparison against the control TCR alone without or with 300 IU/ml IL-2. SEQUENCE LISTING The nucleic acid and amino acid sequences listed in the accompanying sequence listing are shown using standard letter abbreviations for nucleotide bases, and single letter code for amino acids. Only one strand of each nucleic acid sequence is shown, but the complementary strand is understood as included by any reference to the displayed strand. In the accompanying sequence listing: SEQ ID NOs: 1-73 are amino acid sequences of chimeric IFNG receptors. SEQ ID NOs: 74-146 are codon-optimized nucleic acid sequences encoding chimeric IFNG receptors. SEQ ID NO: 147 is an exemplary amino acid sequence of wild-type human IFNGR1 (GENBANK Accession No. NP_000407.1). 1 MALLFLLPLV MQGVSRAEMG TADLGPSSVP TPTNVTIESY NMNPIVYWEY QIMPQVPVFT 61 VEVKNYGVKN SEWIDACINI SHHYCNISDH VGDPSNSLWV RVKARVGQKE SAYAKSEEFA 121 VCRDGKIGPP KLDIRKEEKQ IMIDIFHPSV FVNGDEQEVD YDPETTCYIR VYNVYVRMNG 1
81 SEIQYKILTQ KEDDCDEIQC QLAIPVSSLN SQYCVSAEGV LHVWGVTTEK SKEVCITIFN 241 SSIKGSLWIP VVAALLLFLV LSLVFICFYI KKINPLKEKS IILPKSLISV VRSATLETKP 301 ESKYVSLITS YQPFSLEKEV VCEEPLSPAT VPGMHTEDNP GKVEHTEELS SITEVVTTEE 361 NIPDVVPGSH LTPIERESSS PLSSNQSEPG SIALNSYHSR NCSESDHSRN GFDTDSSCLE 421 SHSSLSDSEF PPNNKGEIKT EGQELITVIK APTSFGYDKP HVLVDLLVDD SGKESLIGYR 481 PTEDSKEFS SEQ ID NO: 148 is an exemplary amino acid sequence of wild-type human IFNGR2 (GENBANK Accession No. NP_001316057.1). 1 MRPTLLWSLL LLLGVFAAAA AAPPAQLTLE TYQEWCNDSA ATHDPLSQLP APQHPKIRLY 61 NAEQVLSWEP VALSNSTRPV VYQVQFKYTD SKWFTADIMS IGVNCTQITA TECDFTAASP 121 SAGFPMDFNV TLRLRAELGA LHSAWVTMPW FQHYRNVTVG PPENIEVTPG EGSLIIRFSS 181 PFDIADTSTA FFCYYVHYWE KGGIQQVKGP FRSNSISLDN LKPSRVYCLQ VQAQLLWNKS 241 NIFRVGHLSN ISCYETMADA STELQQVILI SVGTFSLLSV LAGACFFLVL KYRGLIKYWF 301 HTPPSIPLQI EEYLKDPTQP ILEALDKDSS PKDDVWDSVS IISFPEKEQE DVLQTL SEQ ID NOs: 149-152 are amino acid sequences of exemplary 2A peptides. DETAILED DESCRIPTION I. Abbreviations APC antigen presenting cell CSF2RB colony stimulating factor 2 receptor subunit beta EGFR epidermal growth factor receptor EPOR erythropoietin receptor
6727-109858-02 GHR growth hormone receptor GMCSFRA granulocyte-macrophage colony stimulating factor receptor alpha GP130 membrane glycoprotein 130 ICOS inducible T cell costimulator IFN interferon IFNGR interferon gamma receptor IGF1R insulin-like growth factor 1 receptor IL interleukin IL2RB interleukin 2 receptor subunit beta IL2RG interleukin 2 receptor subunit gamma IL3RA interleukin 3 receptor subunit alpha IL6RA interleukin 6 receptor IL7RA interleukin 7 receptor IL9R interleukin 9 receptor IL10RA interleukin 10 receptor subunit alpha IL10RB interleukin 10 receptor subunit beta IL11RA interleukin 11 receptor subunit alpha IL20RA interleukin 20 receptor subunit alpha IL20RB interleukin 20 receptor subunit beta IL22R interleukin 22 receptor INSR insulin receptor LEPR leptin receptor MET MET proto-oncogene receptor tyrosine kinase MHC major histocompatibility complex NK cell natural killer cell NKT cell natural killer T cell PRLR prolactin receptor ROS1 ROS1 proto-oncogene 1 receptor tyrosine kinase TLR toll-like receptor TM transmembrane TPOR thrombopoietin receptor TSLPR thymic stromal lymphopoietin receptor II. Summary of Terms Unless otherwise noted, technical terms are used according to conventional usage. Definitions of many common terms in molecular biology may be found in Krebs et al. (eds.), Lewin’s genes XII, published by Jones & Bartlett Learning, 2017. As used herein, the singular forms “a,” “an,” and “the,” refer to both
6727-109858-02 the singular as well as plural, unless the context clearly indicates otherwise. For example, the term “a polypeptide” includes singular or plural polypeptides and can be considered equivalent to the phrase “at least one polypeptide.” As used herein, the term “comprises” means “includes.” It is further to be understood that any and all base sizes or amino acid sizes, and all molecular weight or molecular mass values, given for nucleic acids or polypeptides are approximate, and are provided for descriptive purposes, unless otherwise indicated. Although many methods and materials similar or equivalent to those described herein can be used, particular suitable methods and materials are described herein. In case of conflict, the present specification, including explanations of terms, will control. In addition, the materials, methods, and examples are illustrative only and not intended to be limiting. To facilitate review of the various aspects, the following explanations of terms are provided: 2A peptide: A type of self-cleaving peptide encoded by some RNA viruses, such as picornaviruses. 2A peptides function by making the ribosome skip the synthesis of a peptide bond at the C-terminus of a 2A element, leading to separation between the end of the 2A sequence and the downstream peptide (Kim et al., PLoS One 6(4):e18556, 2011). The "cleavage" occurs between the glycine and proline residues found on the C-terminus of the 2A peptide. Exemplary 2A peptides include, but are not limited to, the 2A peptides encoded by Thosea asigna virus (TaV), equine rhinitis A virus (ERAV), porcine teschovirus-1 (PTV1) and foot and mouth disease virus (FMDV), which are set forth herein as SEQ ID NOs: 149-152 and listed below: P2A: ATNFSLLKQAGDVEENPGP (SEQ ID NO: 149) F2A: VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 150) E2A: QCTNYALLKLAGDVESNPGP (SEQ ID NO: 151) T2A: EGRGSLLTCGDVEENPGP (SEQ ID NO: 152) 4-1BB: A member of the TNF-receptor family.4-1BB is involved in T cell clonal expansion, survival, and development. This protein can also induce proliferation in peripheral monocytes, enhance T cell apoptosis, and regulate Th1 cell responses.4-1BB is also known as TNFRSF9, ILA, and CD137. Nucleic acid and amino acid sequences for human 4-1BB (and homologs thereof) are publicly available, such as under NCBI Gene ID 3604. Autologous: Refers to tissues, cells or nucleic acids taken from an individual’s own tissues. For example, in an autologous transfer or transplantation of modified T cells described herein, the donor and recipient are the same person. Therapies utilizing engineered autologous T cells are patient-specific, as the therapeutic T cells are created from a patient’s own cells. Typically, to produce an autologous T cell for a therapeutic formulation or use, an individual’s peripheral blood mononuclear cells (PBMCs) are collected, and then subjected to ex vivo genetic modification. CD8+ T cells are isolated from the collected PBMCs, activated, and transduced with a nucleic acid encoding a chimeric IFNGR polypeptide(s) to produce the autologous T cells, which may then be culture-expanded, formulated, and optionally cryopreserved. Cancer: A malignant tumor characterized by abnormal or uncontrolled cell growth. Other features often associated with cancer include metastasis, interference with the normal functioning of neighboring cells, release of cytokines or other secretory products at abnormal levels and suppression or aggravation of
6727-109858-02 inflammatory or immunological response, invasion of surrounding or distant tissues or organs, such as lymph nodes, etc. “Metastatic disease” refers to cancer cells that have left the original tumor site and migrated to other parts of the body, for example via the bloodstream or lymph system. CD2: A surface antigen found on peripheral blood T-cells. This protein optimizes immune recognition. CD2 is also known as LFA-2. Nucleic acid and amino acid sequences for human CD2 (and homologs thereof) are publicly available, such as under NCBI Gene ID 914. CD28: A protein important for T-cell proliferation and survival, cytokine production, and T-helper type-2 development. Nucleic acid and amino acid sequences for human CD28 (and homologs thereof) are publicly available, such as under NCBI Gene ID 940. As used herein, “CD28_YMFM” refers to a modified CD28 reported to be more active than WT CD28 (the sequence of the CD28_YMFM intracellular signaling domain is set forth herein as residues 273-313 of SEQ ID NO: 16). Colony stimulating factor 2 receptor subunit beta (CSF2RB): The common beta chain of the high affinity receptor for IL-3, IL-5, and colony stimulating factor (CSF). CSF2RB is also known as CD131, IL3RB, and IL5RB. Nucleic acid and amino acid sequences for human CSF2RB (and homologs thereof) are publicly available, such as under NCBI Gene ID 1439. Ectopic: The term “ectopic,” as applied to molecules herein (for example, IFNGR proteins, TCRs, and polynucleotides encoding the same), refers to a polypeptide/protein or polynucleotide in a specific environment or context in which it is not normally present. For example, if a host cell is transformed with a polynucleotide that does not occur in the untransformed host cell in nature, then that polynucleotide is ectopic to the host cell. By way of further example, if a modified host cell expresses a protein (e.g., IFNGR proteins and/or TCRs) that does not occur in the wild-type host cell, or that occurs in the wild-type host cell under a different set of conditions, the protein is ectopic to the host cell. Accordingly, ectopic proteins (such as IFNGR or TCRs) herein specifically include proteins that are identical in amino acid sequence to a protein already present in a host cell, but that are expressed in a different cellular context than the protein with the same sequence already present in the host cell; for example, wherein the ectopic protein is constitutively expressed or expressed under different conditions. Similarly, ectopic polynucleotides encoding the proteins herein specifically include polynucleotides that are identical in sequence to those already present in a host cell, but that are located in a different cellular or genomic context than the polynucleotide with the same sequence already present in the host cell. For example, a polynucleotide that is located in a different location in the host cell than a polynucleotide with the same sequence is normally integrated in the of the host cell (for example, as a component of an expression construct integrated at a different genomic locus than the polynucleotide of the same sequence is normally found) is ectopic to the host cell. Furthermore, a polynucleotide that is present in a plasmid or vector in the host cell is ectopic to the host cell when a polynucleotide with the same sequence is only normally present in the genome of the host cell. Epidermal growth factor receptor (EGFR): A member of the protein kinase superfamily. EGFR is a transmembrane glycoprotein that binds to epidermal growth factor (EGF), causing a tyrosine
6727-109858-02 autophosphorylation cascade and cell proliferation. EGFR is also known as ERBB, ERBB1 and HER1. Nucleic acid and amino acid sequences for human EGFR (and homologs thereof) are publicly available, such as under NCBI Gene ID 1956. Erythropoietin receptor (EPOR): A member of the cytokine receptor family. Upon erythropoietin binding, EPOR activates Jak2 tyrosine kinase which activates different intracellular pathways including Ras/MAP kinase, phosphatidylinositol 3-kinase and STAT transcription factors. Nucleic acid and amino acid sequences for human EPOR (and homologs thereof) are publicly available, such as under NCBI Gene ID 2057. As used herein, “EPORtr” refers to a truncated EPOR lacking the C-terminal 70 amino acids. EPORtr has been reported to be more active than WT EPOR. The amino acid sequence of EPORtr intracellular domain is set forth herein as residues 269-433 of SEQ ID NO: 2. Expression: As used herein, “expression” of a polynucleotide refers to the process by which the coded information of a transcriptional unit is converted into a polypeptide. The expression of a coding sequence can be influenced by external signals; for example, exposure of a cell, tissue, or organism to a signal (for example, an agonist or antigen that binds a cellular receptor) that increases or decreases gene expression. When used herein with regard to a polypeptide, “expression” refers to the synthesis of the polypeptide by a cell from a polynucleotide that encodes the polypeptide, for example, under the control of a regulatory element such as a promoter that is functional in the cell. Glycoprotein 130 (GP130): A signal transducer shared by many cytokines, including interleukin 6 (IL6), ciliary neurotrophic factor (CNTF), leukemia inhibitory factor (LIF), and oncostatin M (OSM). This protein functions as a part of the cytokine receptor complex. The activation of GP130 is dependent upon the binding of cytokines to their receptors. GP130 is also known as interleukin 6 cytokine family signal transducer (IL6ST) and CD130. Nucleic acid and amino acid sequences for human GP130 (and homologs thereof) are publicly available, such as under NCBI Gene ID 3572. Granulocyte-macrophage colony stimulating factor receptor alpha (GMCSFRA): The alpha subunit of the heterodimeric receptor for colony stimulating factor 2, a cytokine which controls the production, differentiation, and function of granulocytes and macrophages. This protein is a member of the cytokine family of receptors. GMCSFRA is also known as colony stimulating factor 2 receptor subunit alpha (CSF2RA) and CD116. Nucleic acid and amino acid sequences for human GMCSFRA (and homologs thereof) are publicly available, such as under NCBI Gene ID 1438. Growth hormone receptor (GHR): A member of the type I cytokine receptor family, which is a transmembrane receptor for growth hormone. Binding of growth hormone to the receptor leads to activation of an intra- and intercellular signal transduction pathway leading to growth. GHR is also known as GHBP and GHIP. Nucleic acid and amino acid sequences for human GHR (and homologs thereof) are publicly available, such as under NCBI Gene ID 2690. Heterologous: The term “heterologous,” as applied to polypeptides and/or polynucleotides herein, means of different origin. For example, if a host cell is transformed with a polynucleotide that does not occur in the untransformed host cell in nature, then that polynucleotide is heterologous (and ectopic) to the
6727-109858-02 host cell. Similarly, if a host cell expresses a polypeptide (e.g., IFNGR chimeric polypeptides) that does not occur in the host cell in nature, then that polypeptide is heterologous (and ectopic) to the host cell. In addition, chimeric polypeptides comprised of two or more components can include heterologous sequences, for example a transmembrane domain or intracellular signaling domain are heterologous to an IFNGR1 extracellular domain if they are from proteins other than IFNGR1. Furthermore, different elements (e.g., promoters, enhancers, coding sequences, and terminators) of an expression cassette may be heterologous to one another and/or to the transformed host cell. Heterologous polynucleotides herein also specifically include a polynucleotide that is identical in sequence to a polynucleotide already present in a host cell, but that is linked to a different regulatory sequence and/or is present at a different copy number in the host cell. Inducible T cell costimulator (ICOS): A member of the CD28 and CTLA-4 cell surface receptor family. The ICOS protein forms homodimers which are involved in cell-cell signaling, immune response, and regulation of cell proliferation. ICOS is also known as CD278. Nucleic acid and amino acid sequences for human ICOS (and homologs thereof) are publicly available, such as under NCBI Gene ID 29851. Inhibiting, ameliorating, or treating a disease: “Inhibiting” a condition refers to inhibiting the full development of a condition or disease, for example, cancer or a tumor. Inhibition of a condition occurs within the spectrum from partial inhibition to substantially complete inhibition of the disease. In some examples, the term “inhibiting” refers to reducing or delaying the onset or progression of a condition. “Ameliorating” refers to the reduction in the number or severity of signs or symptoms of a disease, such as cancer. “Treating” refers to a therapeutic intervention that decreases or inhibits a sign or symptom of a disease or pathological condition after it has begun to develop, such as a reduction in tumor size or tumor burden. A subject to be administered an effective amount of the disclosed modified immune cells can be identified by standard diagnosing techniques for such a disorder, for example, presence of the disease or disorder or risk factors to develop the disease or disorder. Insulin-like growth factor 1 receptor (IGF1R): This receptor binds insulin-like growth factor and has tyrosine kinase activity. IGF1R is also known as IGFR, CD221 and JTK13. Nucleic acid and amino acid sequences for human IGF1R (and homologs thereof) are publicly available, such as under NCBI Gene ID 3480. Insulin receptor (INSR): A member of the receptor tyrosine kinase family of proteins. Binding of insulin or other ligands to this receptor activates the insulin signaling pathway, which regulates glucose uptake and release, as well as the synthesis and storage of carbohydrates, lipids and protein. INSR is also known as CD220. Nucleic acid and amino acid sequences for human INSR (and homologs thereof) are publicly available, such as under NCBI Gene ID 3643. Interferon gamma receptor 1 (IFNGR1): The ligand binding chain (alpha) of the gamma interferon receptor. The human interferon gamma receptor is a heterodimer of IFNGR1 and IFNGR2. IFNGR1 is also known as CD119. Nucleic acid and amino acid sequences for human IFNGR1 (and homologs thereof) are publicly available, such as under NCBI Gene ID 3459. An exemplary wild-type
6727-109858-02 human IFNGR1 amino acid sequence is set forth herein as SEQ ID NO: 147. Several versions of IFNGR1 with a modified intracellular domain are disclosed herein as follows: Modified IFNGR1 Descriptor IFNGR1-2RB-S5 The IFNGR1 STAT1 binding site (FGYDKPH; residues 455-461 of m s h of 34

Interferon gamma receptor 2 (IFNGR2): The non-ligand binding chain (beta) of the gamma interferon receptor. The human interferon gamma receptor is a heterodimer of IFNGR1 and IFNGR2. Nucleic acid and amino acid sequences for human IFNGR2 (and homologs thereof) are publicly available, such as under NCBI Gene ID 3460. An exemplary wild-type human IFNGR2 amino acid sequence is set forth herein as SEQ ID NO: 148. Interleukin 2 receptor subunit beta (IL2RB): The beta subunit of the interleukin 2 receptor. IL2RB is a type I membrane protein. The interleukin 2 receptor, which is involved in T cell-mediated immune responses, is present in 3 forms with respect to ability to bind interleukin 2. The low affinity form is a monomer of the alpha subunit, the intermediate affinity form consists of an alpha/beta subunit heterodimer, and the high affinity form consists of an alpha/beta/gamma subunit heterotrimer. Both the intermediate and high affinity forms of the receptor are involved in receptor-mediated endocytosis and
6727-109858-02 transduction of mitogenic signals from interleukin 2. IL2RB is also known as CD122 and IL15RB. Nucleic acid and amino acid sequences for human IL2RB (and homologs thereof) are publicly available, such as under NCBI Gene ID 3560. Interleukin 2 receptor subunit gamma (IL2RG): A protein that is the signaling component of many interleukin receptors, including the receptors for IL-2, -4, -7 and -21, and is thus referred to as the common gamma chain. IL2RG is also known as CD132. Nucleic acid and amino acid sequences for human IL2RG (and homologs thereof) are publicly available, such as under NCBI Gene ID 3561. Interleukin 3 receptor subunit alpha (IL3RA): The ligand-binding subunit of the IL-3 receptor complex. IL3RA heterodimerizes with the common beta chain. Nucleic acid and amino acid sequences for human IL3RA (and homologs thereof) are publicly available, such as under NCBI Gene ID 3563. Interleukin 6 receptor (IL6R or IL6RA): A subunit of the interleukin 6 (IL6) receptor complex. Interleukin 6 is a pleiotropic cytokine that regulates cell growth and differentiation and plays an important role in immune response. Nucleic acid and amino acid sequences for human IL6R (and homologs thereof) are publicly available, such as under NCBI Gene ID 3570. Interleukin 7 receptor (IL7R or IL7RA): A receptor for interleukin 7 (IL7), which heterodimerizes with the common gamma chain to bind IL-7. IL7R is also known as CD127, IL7RA, and IL-7R-alpha. Nucleic acid and amino acid sequences for human IL7R (and homologs thereof) are publicly available, such as under NCBI Gene ID 3575. Interleukin 9 receptor (IL9R): A cytokine receptor that mediates the effects of interleukin 9 (IL9). The IL9 receptor complex requires this protein as well as the interleukin 2 receptor, gamma (IL2RG), a common gamma subunit shared by the receptors of many different cytokines. IL9 binding to the receptor leads to the activation of various JAK-STAT pathways. IL9R is also known as CD129. Nucleic acid and amino acid sequences for human IL9R (and homologs thereof) are publicly available, such as under NCBI Gene ID 3581. Interleukin 10 receptor subunit alpha (IL10RA): A receptor for interleukin 10. IL10RA mediates the immunosuppressive signal of interleukin 10, and thus inhibits the synthesis of proinflammatory cytokines. IL10RA is also known as CD210, IL10R and IL-10R1. Nucleic acid and amino acid sequences for human IL10RA (and homologs thereof) are publicly available, such as under NCBI Gene ID 3587. Interleukin 10 receptor subunit beta (IL10RB): A member of the cytokine receptor family. This subunit is an accessory chain essential for the activation of the interleukin 10 receptor complex. Nucleic acid and amino acid sequences for human IL10RB (and homologs thereof) are publicly available, such as under NCBI Gene ID 3588. Interleukin 11 receptor subunit alpha (IL11RA): A receptor for IL11 and a member of the hematopoietic cytokine receptor family. Contains an extracellular region with a 2-domain structure composed of an immunoglobulin-like domain and a cytokine receptor-like domain. Nucleic acid and amino acid sequences for human IL11RA (and homologs thereof) are publicly available, such as under NCBI Gene ID 3590.
6727-109858-02 Interleukin 20 receptor subunit alpha (IL20RA): A member of the type II cytokine receptor family. IL20RA is a subunit for the interleukin 20 receptor. IL20RA and IL20RB form a heterodimeric receptor for IL20. Nucleic acid and amino acid sequences for human IL10RA (and homologs thereof) are publicly available, such as under NCBI Gene ID 53832. Interleukin 20 receptor subunit beta (IL20RB): A subunit of the IL20 receptor. IL20RA and IL20RB form a heterodimeric receptor for IL20. Nucleic acid and amino acid sequences for human IL20RB (and homologs thereof) are publicly available, such as under NCBI Gene ID 53833. Interleukin 22 receptor (IL22R or IL22RA1): A receptor for IL22 that belongs to the class II cytokine receptor family. The IL22 receptor is a protein complex that consists of IL22RA1 and IL10 receptor beta, a subunit that is also shared by the receptor complex for IL10. Nucleic acid and amino acid sequences for human IL22RA1 (and homologs thereof) are publicly available, such as under NCBI Gene ID 58985. Isolated: An “isolated” biological component (such as a polynucleotide, protein, or cell) has been substantially separated, produced apart from, or purified away from other biological components (e.g., other cells, chromosomal and extra-chromosomal DNA and RNA, and proteins). Cells, polynucleotides, and proteins that have been isolated specifically include cells, nucleic acid molecules, and proteins purified by standard purification methods. The term also embraces nucleic acid molecules and proteins prepared by recombinant expression or production in a host organism, as well as chemically-synthesized nucleic acid molecules. Leptin receptor (LEPR): A member of the gp130 family of cytokine receptors that stimulate gene transcription via activation of STAT proteins. This protein is a receptor for leptin (an adipocyte-specific hormone that regulates body weight) and is involved in the regulation of fat metabolism and lymphopoiesis. Nucleic acid and amino acid sequences for human LEPR (and homologs thereof) are publicly available, such as under NCBI Gene ID 3953. MET proto-oncogene receptor tyrosine kinase (MET): A member of the receptor tyrosine kinase family of proteins. Binding of its ligand, hepatocyte growth factor, induces dimerization and activation of the receptor, which plays a role in cell survival, embryogenesis, and cellular migration and invasion. MET is also known as HGFR and c-Met. Nucleic acid and amino acid sequences for human MET (and homologs thereof) are publicly available, such as under NCBI Gene ID 4233. Oncostatin M receptor (OSMRB): A member of the type I cytokine receptor family. The OSMRB protein heterodimerizes with interleukin 6 signal transducer (IL6ST) and transduces oncostatin M signaling events. OSMRB is also known as OSMR, IL-3RB and PLCA1. Nucleic acid and amino acid sequences for human OSMRB (and homologs thereof) are publicly available, such as under NCBI Gene ID 9180. Pharmaceutically acceptable carriers: The pharmaceutically acceptable carriers of use are known to those of ordinary skill in the art. Remington: The Science and Practice of Pharmacy, 22
nd ed., London, UK: Pharmaceutical Press, 2013, describes compositions and formulations suitable for pharmaceutical delivery of the disclosed agents. In general, the nature of the carrier will depend on the particular mode of
6727-109858-02 administration being employed. For example, parenteral formulations usually include injectable fluids that include pharmaceutically and physiologically acceptable fluids such as water, physiological saline, balanced salt solutions, aqueous dextrose, glycerol or the like as a vehicle. In addition to biologically neutral carriers, pharmaceutical compositions to be administered can contain minor amounts of non-toxic auxiliary substances, such as wetting or emulsifying agents, added preservatives (such as non-natural preservatives), and pH buffering agents and the like, for example sodium acetate or sorbitan monolaurate. In particular examples, the pharmaceutically acceptable carrier is sterile and suitable for parenteral administration to a subject for example, by injection. In some embodiments, the active agent and pharmaceutically acceptable carrier are provided in a unit dosage form such as in a selected quantity in a vial. Unit dosage forms can include one dosage or multiple dosages (for example, in a vial from which metered dosages of the agent can selectively be dispensed). Prolactin receptor (PRLR): A receptor for the anterior pituitary hormone, prolactin, and belongs to the type I cytokine receptor family. Nucleic acid and amino acid sequences for human PRLR (and homologs thereof) are publicly available, such as under NCBI Gene ID 5618. Purified: The term purified does not require absolute purity; rather, it is intended as a relative term. Thus, for example, a purified nucleic acid, protein or cell preparation is one in which the nucleic acid, protein, or cell is more enriched than in its original environment. In one embodiment, a preparation is purified such that the nucleic acid, protein, or cells represent at least 50% of the total nucleic acid, protein, or cell content of the preparation. Recombinant: A recombinant nucleic acid is one that has a sequence that is not naturally occurring or has a sequence that is made by an artificial combination of two otherwise separated segments of sequence (such as a chimeric nucleic acid). This artificial combination can be accomplished by chemical synthesis or by the manipulation of isolated segments of nucleic acids, for example, by genetic engineering techniques. In some examples, a chimeric protein is encoded by a recombinant nucleic acid. In several embodiments, a recombinant protein is encoded by a heterologous (for example, recombinant) nucleic acid that has been introduced into a host cell, such as a bacterial or eukaryotic cell. The nucleic acid can be introduced, for example, on an expression vector having signals capable of expressing the protein encoded by the introduced nucleic acid, or the nucleic acid can be integrated into the host cell chromosome. Regulatory element: “Regulatory elements,” and “regulatory sequences” refer to nucleic acid elements that influence the timing and level/amount of transcription (or RNA processing or stability) of an operably linked polynucleotide. Particular regulatory elements may be located upstream and/or downstream of a polynucleotide operably linked thereto. Also, particular regulatory elements operably linked to a polynucleotide may be located on the associated complementary strand of a double-stranded nucleic acid molecule. Regulatory elements include, for example and without limitation, promoters, translation leaders, introns, enhancers, stem-loop structures, repressor binding sequences, termination sequences, and polyadenylation recognition sequences. In examples herein, a polynucleotide is operably linked to a promoter, such that the polynucleotide is expressed in a host cell. Specific promoters herein utilized include
6727-109858-02 “constitutive” promoters, which refers to a promoter that is active under most or all conditions in a host cell. In other examples, a polynucleotide is operably linked to an “inducible” promoter, which refers to a promoter wherein the rate of transcription increases in response to an inducing agent (for example, a signal molecule). ROS1 proto-oncogene 1 receptor tyrosine kinase (ROS1): A protein belonging to the subfamily of tyrosine kinase insulin receptor genes. ROS1 is a type I integral membrane protein that functions as a growth and differentiation factor receptor. Nucleic acid and amino acid sequences for human ROS1 (and homologs thereof) are publicly available, such as under NCBI Gene ID 6098. Subject: Living multi-cellular vertebrate organisms, a category that includes human and non- human mammals, such as non-human primates, pigs, sheep, cows, dogs, cats, rodents, and the like. In some examples, the subject is a human. T cell: A white blood cell (lymphocyte) that is an important mediator of the immune response. T cells include, but are not limited to, CD4
+ T cells and CD8
+ T cells. A CD4
+ T lymphocyte is an immune cell that carries a marker on its surface known as “cluster of differentiation 4” (CD4). These cells, also known as helper T cells, help orchestrate the immune response, including antibody responses as well as killer T cell responses. CD8
+ T cells carry the “cluster of differentiation 8” (CD8) marker. Activated T cells can be detected by an increase in cell proliferation and/or expression of or secretion of one or more cytokines (such as IL-2, IL-4, IL-6, IFNγ, or TNFα). Activation of CD8+ T cells can also be detected by an increase in cytolytic activity in response to an antigen. In some examples, a “modified T cell” is a T cell transduced or transfected with a heterologous nucleic acid (such as one or more of the nucleic acids or vectors disclosed herein) or expressing one or more heterologous proteins (such as a chimeric IFNGR polypeptide). The terms “modified T cell” and “transduced T cell” are used interchangeably in some examples herein. Thrombopoietin receptor (TPOR): A protein encoded by the MPL proto-oncogene, thrombopoietin receptor (MPL) gene. The TPOR protein is 635 amino acids in length and includes a transmembrane domain, two extracellular cytokine receptor domains and two intracellular cytokine receptor box motifs. Upon binding of thrombopoietin, TPOR dimerizes and leads to tyrosine phosphorylation of multiple proteins, including those in the JAK, STAT and MAPK families. TPOR is also known as CD110, myeloproliferative leukemia protein, MPLV, C-MPL, THPOR and THCYT2. Nucleic acid and amino acid sequences for human TPOR (and homologs thereof) are publicly available, such as under NCBI Gene ID 4352. Thymic stromal lymphopoietin receptor (TSLPR): A member of the type I cytokine receptor family that functions as a receptor for thymic stromal lymphopoietin (TSLP). TSLP binding activates STAT3, STAT5, and JAK2 pathways, which control processes such as cell proliferation and development of the hematopoietic system. TSLPR is also known as cytokine receptor like factor 2 (CRLF2). Nucleic acid and amino acid sequences for human TSLPR (and homologs thereof) are publicly available, such as under NCBI Gene ID 64109.
6727-109858-02 Toll-like receptor 1 (TLR1): A member of the toll-like receptor family, which plays a role in pathogen recognition and innate immunity. Infectious agents express pathogen-associated molecular patterns (PAMPs) that TLRs recognize and respond to by producing cytokines. TLR1 is also known as CD281. Nucleic acid and amino acid sequences for human TLR1 (and homologs thereof) are publicly available, such as under NCBI Gene ID 7096. Toll-like receptor 2 (TLR2): A member of the toll-like receptor family which is involved in pathogen recognition and activation of innate immunity. TLR2 is also known as CD282. Nucleic acid and amino acid sequences for human TLR2 (and homologs thereof) are publicly available, such as under NCBI Gene ID 7097. Toll-like receptor 4 (TLR4): A member of the toll-like receptor family which is involved in pathogen recognition and activation of innate immunity. This receptor has been implicated in signal transduction events induced by lipopolysaccharide. TLR4 is also known as CD284. Nucleic acid and amino acid sequences for human TLR4 (and homologs thereof) are publicly available, such as under NCBI Gene ID 7099. Toll-like receptor 6 (TLR6): A member of the toll-like receptor family which is involved in pathogen recognition and activation of innate immunity. This receptor interacts with TLR2 to mediate cellular responses to bacterial lipoproteins. TLR6 is also known as CD286. Nucleic acid and amino acid sequences for human TLR6 (and homologs thereof) are publicly available, such as under NCBI Gene ID 10333. Transformation/Transduction: As used herein, the terms “transformation” and “transduction” are used interchangeably to refer to the transfer of one or more polynucleotide(s) into a cell. A cell is “transformed” or “transduced” by a polynucleotide when a nucleic acid molecule comprising the polynucleotide is introduced into the cell, and the polynucleotide becomes stably replicated by the cell, either by incorporation of the polynucleotide into the cellular genome, or by episomal replication. As used herein, the transformation and transduction encompass all techniques by which a nucleic acid molecule can be introduced into such a cell. Examples include, but are not limited to, transduction with viral vectors, electroporation, microinjection, direct DNA uptake, and microprojectile bombardment. Vector: Nucleic acid molecules as introduced into a cell, for example, to produce a transformed cell. A vector may include genetic elements that permit it to replicate in the host cell. Examples of vectors include but are not limited to plasmids, viruses, and linear DNA molecules that carry ectopic nucleic acids into a cell under suitable conditions. In some aspects herein, the vector is a virus vector, such as a lentivirus vector. III. Chimeric Interferon Gamma Receptors The present disclosure describes chimeric interferon gamma receptors (IFNGRs) that include an extracellular domain from IFNGR1, a transmembrane domain (from IFNGR1 or a heterologous protein), and an intracellular signaling domain. The intracellular signaling domain can be from a heterologous cytokine
6727-109858-02 receptor or can be a modified IFNGR1 intracellular signaling domain. Also described are chimeric IFNGRs that include an extracellular domain from IFNGR2, a transmembrane domain (from IFNGR2 or a heterologous protein), and an intracellular signaling domain from a heterologous cytokine receptor (or in some instances, from wild-type IFNGR2). The present disclosure also describes nucleic acid molecules that encode a chimeric IFNGR1 polypeptide. In some aspects, the nucleic acid molecule encodes both a chimeric IFNGR1 polypeptide and a chimeric IFNGR2 polypeptide. In other aspects, a first nucleic acid molecule encodes a chimeric IFNGR1 polypeptide and a second nucleic acid molecule encodes a chimeric IFNGR2 polypeptide. Further described herein are modified immune cells (such as T cells) that include a nucleic acid molecule or molecules disclosed herein, as well as modified immune cells that express a chimeric IFNGR1 polypeptide and/or a chimeric IFNGR2 polypeptide. Use of the modified immune cells, such as for the treatment of cancer, is also described. The modified immune cells can also be used to enhance the effectiveness of other immunotherapies or anti-cancer treatments in a subject in need thereof. Provided herein are nucleic acid molecules that encode a first chimeric polypeptide that includes an interferon gamma receptor 1 (IFNGR1) extracellular domain, a first transmembrane domain, and a first intracellular signaling domain. In some aspects, the first intracellular signaling domain is a heterologous signaling domain of a cytokine receptor. In other aspects, the first intracellular signaling domain is a modified IFNGR1 intracellular signaling domain. Also provided are nucleic acid molecules that encode a first chimeric polypeptide as described above and further encode a second chimeric polypeptide that includes an interferon gamma receptor 2 (IFNGR2) extracellular domain, a second transmembrane domain, and a second intracellular signaling domain. In some aspects, the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor. In other aspects, the second intracellular signaling domain is an IFNGR2 intracellular signaling domain. In some aspects, the first chimeric polypeptide and the second chimeric polypeptide are encoded by a single nucleic acid molecule and the coding sequence for the first chimeric polypeptide and the coding sequence for the second chimeric polypeptide are separated by a nucleic acid sequence encoding a self-cleaving peptide. In other aspects, the first chimeric polypeptide is encoded by a first nucleic acid molecule and the second chimeric polypeptide is encoded by a second nucleic acid molecule. In some aspects, the first intracellular signaling domain is a heterologous intracellular signaling domain of a first cytokine receptor and/or the second intracellular signaling domain is a heterologous intracellular signaling domain of a second cytokine receptor. In some examples, the first cytokine receptor and the second cytokine receptor are individually selected from the group consisting of: erythropoietin receptor (EPOR), growth hormone receptor (GHR), thrombopoietin receptor (TPOR), prolactin receptor (PRLR), leptin receptor (LEPR), thymic stromal lymphopoietin receptor (TSLPR), colony stimulating factor 2 receptor subunit beta (CSF2RB), interleukin 3 receptor subunit alpha (IL3RA), interleukin 2 receptor subunit beta (IL2RB), interleukin 7 receptor (IL7R), interleukin 9 receptor (IL9R), insulin receptor (INSR), membrane glycoprotein 130 (GP130), CD28, 4-1BB, inducible T cell costimulator (ICOS), CD2, toll-like receptor 1 (TLR1), toll-like receptor 2 (TLR2), toll-like receptor 4 (TLR4), toll-like receptor 6(TLR6),
6727-109858-02 epidermal growth factor receptor (EGFR), insulin-like growth factor 1 receptor (IGF1R), MET proto- oncogene receptor tyrosine kinase (MET), ROS1 proto-oncogene 1 receptor tyrosine kinase (ROS1), granulocyte-macrophage colony stimulating factor receptor alpha (GMCSFRA), interleukin 2 receptor subunit gamma (IL2RG), interleukin 6 receptor (IL6R), interleukin 11 receptor subunit alpha (IL11RA), oncostatin M receptor (OSMRB), interleukin 10 receptor subunit alpha (IL10RA), interleukin 10 receptor subunit beta (IL10RB), interleukin 22 receptor (IL22R), interleukin 20 receptor subunit alpha (IL20RA), and interleukin 20 receptor subunit beta (IL20RB). In some examples of the disclosed nucleic acid molecules, the amino acid sequence of the first intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271- 465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269- 433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272- 387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267- 297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. In specific non-limiting examples, the amino acid sequence of the first intracellular signaling domain comprises or consists of residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID
6727-109858-02 NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273- 314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266- 385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267- 703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. In some examples of the disclosed nucleic acid molecules, the amino acid sequence of the second intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 801-1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932- 1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761-846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615- 655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616-1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847- 932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62;
6727-109858-02 residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844-900 of SEQ ID NO: 67. In specific non-limiting examples, the amino acid sequence of the second intracellular signaling domain comprises or consists of residues 801-1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761-846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749- 935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616-1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617- 1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844-900 of SEQ ID NO: 67. In other examples of the disclosed nucleic acid molecules, the first intracellular signaling domain is a modified IFNGR1 signaling domain; and/or the first intracellular signaling domain is a modified IFNGR1 signaling domain and the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. In particular examples, the modified IFNGR1 signaling domain includes substitution of one or more amino acids that make up the IFNGR1 STAT1 binding site. Specific non-limiting examples include the modified IFNGR1 referred to herein as IFNGR1-2RB-S5 (residues 267-489 of SEQ ID NO: 68), IFNGR1-2RB-S5- SOCSYF (residues 267-489 of SEQ ID NO: 69), IFNGR1-2RB-Cterm20 (residues 267-472 of SEQ ID NO: 70), IFNGR1-GHR-S5x2 (residues 267-489 of SEQ ID NO: 71), IFNGR1-GHR-Cyt45 (residues 267-497 of SEQ ID NO: 72), or IFNGR1-EPOR-S5 (residues 267-489 of SEQ ID NO: 73). Thus, in some aspects, the amino acid sequence of the modified IFNGR1 intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. In some examples, the amino acid sequence of the modified IFNGR1 intracellular signaling domain comprises or consists of residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. In some examples, the wild-type IFNGR2 intracellular signaling domain includes or consists of residues 288-356 of SEQ ID NO: 148.
6727-109858-02 In some aspects of the disclosed nucleic acid molecules, the transmembrane domain of the first chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR1), such as a transmembrane domain from the same cytokine receptor as the first intracellular signaling domain and/or the transmembrane domain of the second chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR2), such as a transmembrane domain from the same cytokine receptor as the second intracellular signaling domain. In other examples, the transmembrane domain of the first chimeric polypeptide is an IFNGR1 transmembrane domain and/or the transmembrane domain of the second chimeric polypeptide is an IFNGR2 transmembrane domain. In some aspects in which the nucleic acid molecule encodes both the first and second chimeric polypeptides, the coding sequence for the first chimeric polypeptide and the coding sequence for the second chimeric polypeptide are separated by a nucleic acid sequence encoding a self-cleaving peptide. In some examples, the self-cleaving peptide is a 2A peptide. Sequences for self-cleaving peptides are well-known and an appropriate sequence can be selected by a skilled person. In some examples, the 2A peptide is a porcine teschovirus-12A peptide (P2A), a Thosea asigna virus 2A peptide (T2A), an equine rhinitis A virus 2A peptide (E2A), or a foot and mouth disease virus 2A peptide (F2A). In particular non-limiting examples, the amino acid sequence of the P2A peptide includes SEQ ID NO: 149, the amino acid sequence of the F2A peptide includes SEQ ID NO: 150, the amino acid sequence of the E2A peptide includes SEQ ID NO: 151, or the amino acid sequence of the T2A peptide includes SEQ ID NO: 152. In other specific examples, the amino acid sequence of the self-cleaving peptide includes residues 504-530 of SEQ ID NO: 28 (which includes a furin cleavage site and a spacer sequence) or residues 512-230 of SEQ ID NO: 28. In some aspects, the nucleic acid molecules are codon-optimized for expression in mammalian cells, such as human cells. In some examples in which the nucleic acid molecule encodes only a first chimeric polypeptide, the nucleic acid molecule includes the nucleotide sequence of any one of SEQ ID NOs: 74-100, or a degenerate variant thereof. In other examples in which the nucleic acid molecule encodes both the first and second chimeric polypeptides, the nucleic acid molecule includes the nucleotide sequence of any one of SEQ ID NOs: 101-146, or a degenerate variant thereof. In some examples, the nucleic acid molecule is operably linked to a promoter. Also provided herein are vectors that include a nucleic acid molecule or molecules disclosed herein. In some aspects, the vector is a viral vector, such as a gammaretroviral vector or a lentiviral vector. Further provided are modified immune cells that include a nucleic acid molecule or molecules or vector disclosed herein. In some aspects, the immune cell is a T cell. In some examples, the T cell is a tumor-reactive T cell or a tumor-infiltrating lymphocyte (TIL). In other examples, the immune cell is a B cell, NK cell, NKT cell, macrophage or dendritic cell. In some examples, the immune cell is a human immune cell. Also provided herein are modified immune cells that express a first chimeric polypeptide that includes an IFNGR1 extracellular domain, a first transmembrane domain, and a first intracellular signaling domain. In some aspects, the first intracellular signaling domain is a heterologous signaling domain of a
6727-109858-02 cytokine receptor. In other aspects, the first intracellular signaling domain is a modified IFNGR1 intracellular signaling domain. Also provided are modified immune cells that express a first chimeric polypeptide as described above and further express a second chimeric polypeptide that includes an IFNGR2 extracellular domain, a second transmembrane domain, and a second intracellular signaling domain. In some aspects, the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor. In other aspects, the second intracellular signaling domain is an IFNGR2 intracellular signaling domain, for example a wild-type IFNGR2 intracellular signaling domain. In some aspects of the modified immune cells, the first cytokine receptor and the second cytokine receptor are individually selected from the group consisting of EPOR, GHR, TPOR, PRLR, LEPR, TSLPR, CSF2RB, IL3RA, IL2RB, IL7R, IL9R, INSR, GP130, CD28, 4-1BB, ICOS, CD2, TLR1, TLR2, TLR4, TLR6, EGFR, IGF1R, MET, ROS1, GMCSFRA, IL2RG, IL6R, IL11RA, OSMRB, IL10RA, IL10RB, IL22R, IL20RA and IL20RB. In some examples, the amino acid sequence of the first intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270- 619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272- 387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271- 555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267- 319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67.
6727-109858-02 In particular examples of the modified immune cells, the amino acid sequence of the first intracellular signaling domain comprises or consists of residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270- 633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267- 453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267- 496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267- 551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. In some examples of the modified immune cells, the amino acid sequence of the second intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 801-1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761-846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749- 935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616-1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID
6727-109858-02 NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617- 1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844-900 of SEQ ID NO: 67. In specific examples, the amino acid sequence of the second intracellular signaling domain comprises or consists of residues 801- 1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761- 846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616- 1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844- 900 of SEQ ID NO: 67. In other aspects of the modified immune cells, the first intracellular signaling domain is a modified IFNGR1 signaling domain; and/or the first intracellular signaling domain is a modified IFNGR1 signaling domain and the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. In some examples, the amino acid sequence of the modified IFNGR1 intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. In specific examples, the amino acid sequence of the modified IFNGR1 intracellular signaling domain comprises or consists of residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. In some examples, the wild-type IFNGR2 intracellular signaling domain includes residues 288-356 of SEQ ID NO: 148. In some examples of the modified immune cells, the transmembrane domain of the first chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR1), such as a transmembrane domain from the same cytokine receptor as the first intracellular signaling domain, and/or the transmembrane domain of the second chimeric polypeptide is a heterologous transmembrane
6727-109858-02 domain (a transmembrane domain that is not from IFNGR2), such as a transmembrane domain from the same cytokine receptor as the second intracellular signaling domain. In other examples, the transmembrane domain of the first chimeric polypeptide is an IFNGR1 transmembrane domain and/or the transmembrane domain of the second chimeric polypeptide is an IFNGR2 transmembrane domain. In particular aspects of the modified immune cells, the amino acid sequence of the first chimeric polypeptide is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to SEQ ID NO: 1; SEQ ID NO: 2; SEQ ID NO: 3; SEQ ID NO: 4; SEQ ID NO: 5; SEQ ID NO: 6; SEQ ID NO: 7; SEQ ID NO: 8; SEQ ID NO: 9; SEQ ID NO: 10; SEQ ID NO: 11; SEQ ID NO: 12; SEQ ID NO: 13; SEQ ID NO: 14; SEQ ID NO: 15; SEQ ID NO: 16; SEQ ID NO: 17; SEQ ID NO: 18; SEQ ID NO: 19; SEQ ID NO: 20; SEQ ID NO: 21; SEQ ID NO: 21; SEQ ID NO: 22; SEQ ID NO: 23; SEQ ID NO: 24; SEQ ID NO: 25; SEQ ID NO: 26; SEQ ID NO: 27; residues 1-503 of SEQ ID NO: 28; residues 1-433 of SEQ ID NO: 29; residues 1-619 of SEQ ID NO: 30; residues 1-389 of SEQ ID NO: 31; residues 1-633 of SEQ ID NO: 32; residues 1-571 of SEQ ID NO: 33; residues 1-318 of SEQ ID NO: 34; residues 1-385 of SEQ ID NO: 35; residues 1-671 of SEQ ID NO: 36; residues 1-699 of SEQ ID NO: 37; residues 1-555 of SEQ ID NO: 38; residues 1-465 of SEQ ID NO: 39; residues 1-496 of SEQ ID NO: 40; residues 1-544 of SEQ ID NO: 41; residues 1-313 of SEQ ID NO: 42; residues 1-313 of SEQ ID NO: 43; residues 1-314 of SEQ ID NO: 44; residues 1-304 of SEQ ID NO: 45; residues 1-387 of SEQ ID NO: 46; residues 1-451 of SEQ ID NO: 47; residues 1-441 of SEQ ID NO: 48; residues 1-453 of SEQ ID NO: 49; residues 1-455 of SEQ ID NO: 50; residues 1-677 of SEQ ID NO: 51; residues 1-703 of SEQ ID NO: 52; residues 1-320 of SEQ ID NO: 53; residues 1-352 of SEQ ID NO: 54; residues 1-319 of SEQ ID NO: 55; residues 1-385 of SEQ ID NO: 56; residues 1-551 of SEQ ID NO: 57; residues 1-496 of SEQ ID NO: 58; residues 1-461 of SEQ ID NO: 59; residues 1-325 of SEQ ID NO: 60; residues 1-352 of SEQ ID NO: 61; residues 1-348 of SEQ ID NO: 62; residues 1-297 of SEQ ID NO: 63; residues 1-519 of SEQ ID NO: 64; residues 1-588 of SEQ ID NO: 65; residues 1-591 of SEQ ID NO: 66; residues 1-548 of SEQ ID NO: 67; residues 1-489 of SEQ ID NO: 68; residues 1-489 of SEQ ID NO: 69; residues 1-472 of SEQ ID NO: 70; residues 1-489 of SEQ ID NO: 71; residues 1-497 of SEQ ID NO: 72; or residues 1-489 of SEQ ID NO: 73. In particular examples, the amino acid sequence of the first chimeric polypeptide comprises or consists of SEQ ID NO: 1; SEQ ID NO: 2; SEQ ID NO: 3; SEQ ID NO: 4; SEQ ID NO: 5; SEQ ID NO: 6; SEQ ID NO: 7; SEQ ID NO: 8; SEQ ID NO: 9; SEQ ID NO: 10; SEQ ID NO: 11; SEQ ID NO: 12; SEQ ID NO: 13; SEQ ID NO: 14; SEQ ID NO: 15; SEQ ID NO: 16; SEQ ID NO: 17; SEQ ID NO: 18; SEQ ID NO: 19; SEQ ID NO: 20; SEQ ID NO: 21; SEQ ID NO: 21; SEQ ID NO: 22; SEQ ID NO: 23; SEQ ID NO: 24; SEQ ID NO: 25; SEQ ID NO: 26; SEQ ID NO: 27; residues 1-503 of SEQ ID NO: 28; residues 1-433 of SEQ ID NO: 29; residues 1-619 of SEQ ID NO: 30; residues 1-389 of SEQ ID NO: 31; residues 1-633 of SEQ ID NO: 32; residues 1-571 of SEQ ID NO: 33; residues 1-318 of SEQ ID NO: 34; residues 1-385 of SEQ ID NO: 35; residues 1-671 of SEQ ID NO: 36; residues 1-699 of SEQ ID NO: 37; residues 1-555 of SEQ ID NO: 38; residues 1-465 of SEQ ID NO: 39; residues 1-496 of SEQ ID NO: 40; residues 1-544 of SEQ ID NO: 41; residues 1-313 of SEQ ID NO: 42; residues 1-313 of SEQ ID NO: 43; residues 1-314 of
6727-109858-02 SEQ ID NO: 44; residues 1-304 of SEQ ID NO: 45; residues 1-387 of SEQ ID NO: 46; residues 1-451 of SEQ ID NO: 47; residues 1-441 of SEQ ID NO: 48; residues 1-453 of SEQ ID NO: 49; residues 1-455 of SEQ ID NO: 50; residues 1-677 of SEQ ID NO: 51; residues 1-703 of SEQ ID NO: 52; residues 1-320 of SEQ ID NO: 53; residues 1-352 of SEQ ID NO: 54; residues 1-319 of SEQ ID NO: 55; residues 1-385 of SEQ ID NO: 56; residues 1-551 of SEQ ID NO: 57; residues 1-496 of SEQ ID NO: 58; residues 1-461 of SEQ ID NO: 59; residues 1-325 of SEQ ID NO: 60; residues 1-352 of SEQ ID NO: 61; residues 1-348 of SEQ ID NO: 62; residues 1-297 of SEQ ID NO: 63; residues 1-519 of SEQ ID NO: 64; residues 1-588 of SEQ ID NO: 65; residues 1-591 of SEQ ID NO: 66; residues 1-548 of SEQ ID NO: 67; residues 1-489 of SEQ ID NO: 68; residues 1-489 of SEQ ID NO: 69; residues 1-472 of SEQ ID NO: 70; residues 1-489 of SEQ ID NO: 71; residues 1-497 of SEQ ID NO: 72; or residues 1-489 of SEQ ID NO: 73. In particular aspects of the modified immune cells, the amino acid sequence of the second chimeric polypeptide is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 531-1035 of SEQ ID NO: 28; residues 461-895 of SEQ ID NO: 29; residues 645-1297 of SEQ ID NO: 30; residues 417-807 of SEQ ID NO: 31; residues 661-1295 of SEQ ID NO: 32; residues 599-1171 of SEQ ID NO: 33; residues 346-1046 of SEQ ID NO: 34; residues 413-879 of SEQ ID NO: 35; residues 699-1371 of SEQ ID NO: 36; residues 727-1053 of SEQ ID NO: 37; residues 535- 936 of SEQ ID NO: 38; residues 493-846 of SEQ ID NO: 39; residues 524-877 of SEQ ID NO: 40; residues 572-1117 of SEQ ID NO: 41; residues 341-655 of SEQ ID NO: 42; residues 341-655 of SEQ ID NO: 43; residues 342-657 of SEQ ID NO: 44; residues 332-637 of SEQ ID NO: 45; residues 415-803 of SEQ ID NO: 46; residues 479-931 of SEQ ID NO: 47; residues 469-911 of SEQ ID NO: 48; residues 481-935 of SEQ ID NO: 49; residues 483-939 of SEQ ID NO: 50; residues 705-1383 of SEQ ID NO: 51; residues 731-1053 of SEQ ID NO: 52; residues 348-1052 of SEQ ID NO: 53; residues 380-932 of SEQ ID NO: 54; residues 347- 1051 of SEQ ID NO: 55; residues 413-875 of SEQ ID NO: 56; residues 579-932 of SEQ ID NO: 57; residues 524-877 of SEQ ID NO: 58; residues 489-842 of SEQ ID NO: 59; residues 353-1053 of SEQ ID NO: 60; residues 380-936 of SEQ ID NO: 61; residues 376-921 of SEQ ID NO: 62; residues 325-870 of SEQ ID NO: 63; residues 547-1092 of SEQ ID NO: 64; residues 616-967 of SEQ ID NO: 65; residues 619- 943 of SEQ ID NO: 66; residues 576-900 of SEQ ID NO: 67; residues 517-853 of SEQ ID NO: 68; residues 517-853 of SEQ ID NO: 69; residues 500-836 of SEQ ID NO: 70; residues 517-853 of SEQ ID NO: 71; residues 525-861 of SEQ ID NO: 72; or residues 517-853 of SEQ ID NO: 73. In particular examples, the amino acid sequence of the second chimeric polypeptide comprises or consists of residues 531-1035 of SEQ ID NO: 28; residues 461-895 of SEQ ID NO: 29; residues 645-1297 of SEQ ID NO: 30; residues 417-807 of SEQ ID NO: 31; residues 661-1295 of SEQ ID NO: 32; residues 599-1171 of SEQ ID NO: 33; residues 346-1046 of SEQ ID NO: 34; residues 413-879 of SEQ ID NO: 35; residues 699-1371 of SEQ ID NO: 36; residues 727-1053 of SEQ ID NO: 37; residues 535-936 of SEQ ID NO: 38; residues 493-846 of SEQ ID NO: 39; residues 524-877 of SEQ ID NO: 40; residues 572-1117 of SEQ ID NO: 41; residues 341-655 of SEQ ID NO: 42; residues 341-655 of SEQ ID NO: 43; residues 342- 657 of SEQ ID NO: 44; residues 332-637 of SEQ ID NO: 45; residues 415-803 of SEQ ID NO: 46; residues
6727-109858-02 479-931 of SEQ ID NO: 47; residues 469-911 of SEQ ID NO: 48; residues 481-935 of SEQ ID NO: 49; residues 483-939 of SEQ ID NO: 50; residues 705-1383 of SEQ ID NO: 51; residues 731-1053 of SEQ ID NO: 52; residues 348-1052 of SEQ ID NO: 53; residues 380-932 of SEQ ID NO: 54; residues 347-1051 of SEQ ID NO: 55; residues 413-875 of SEQ ID NO: 56; residues 579-932 of SEQ ID NO: 57; residues 524- 877 of SEQ ID NO: 58; residues 489-842 of SEQ ID NO: 59; residues 353-1053 of SEQ ID NO: 60; residues 380-936 of SEQ ID NO: 61; residues 376-921 of SEQ ID NO: 62; residues 325-870 of SEQ ID NO: 63; residues 547-1092 of SEQ ID NO: 64; residues 616-967 of SEQ ID NO: 65; residues 619-943 of SEQ ID NO: 66; residues 576-900 of SEQ ID NO: 67; residues 517-853 of SEQ ID NO: 68; residues 517-853 of SEQ ID NO: 69; residues 500-836 of SEQ ID NO: 70; residues 517-853 of SEQ ID NO: 71; residues 525- 861 of SEQ ID NO: 72; or residues 517-853 of SEQ ID NO: 73. Also provided herein are chimeric IFNG receptors. The chimeric IFNG receptors are comprised of a first chimeric polypeptide that includes an IFNGR1 extracellular domain, a first transmembrane domain, and a first intracellular signaling domain. In some aspects, the first intracellular signaling domain is a heterologous signaling domain of a cytokine receptor. In other aspects, the first intracellular signaling domain is a modified IFNGR1 intracellular signaling domain. Further provided are chimeric IFNG receptors that include a first chimeric polypeptide as described above and further include a second chimeric polypeptide that includes an IFNGR2 extracellular domain, a second transmembrane domain, and a second intracellular signaling domain. In some aspects, the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor. In other aspects, the second intracellular signaling domain is an IFNGR2 intracellular signaling domain, for example a wild-type IFNGR2 intracellular signaling domain. In some aspects of the chimeric IFNG receptors, the first cytokine receptor and the second cytokine receptor are individually selected from the group consisting of EPOR, GHR, TPOR, PRLR, LEPR, TSLPR, CSF2RB, IL3RA, IL2RB, IL7R, IL9R, INSR, GP130, CD28, 4-1BB, ICOS, CD2, TLR1, TLR2, TLR4, TLR6, EGFR, IGF1R, MET, ROS1, GMCSFRA, IL2RG, IL6R, IL11RA, OSMRB, IL10RA, IL10RB, IL22R, IL20RA and IL20RB. In some examples, the amino acid sequence of the first intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270- 619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272- 387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID
6727-109858-02 NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271- 555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267- 319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. In particular examples of the chimeric IFNG receptors, the amino acid sequence of the first intracellular signaling domain comprises or consists of residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270- 633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267- 453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267- 496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267- 551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues
6727-109858-02 residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. In some examples of the chimeric IFNG receptors, the amino acid sequence of the second intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 801-1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932- 1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761-846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615- 655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616-1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847- 932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844-900 of SEQ ID NO: 67. In specific examples, the amino acid sequence of the second intracellular signaling domain comprises or consists of residues 801- 1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761- 846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616- 1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844- 900 of SEQ ID NO: 67. In other aspects of the chimeric IFNG receptors, the first intracellular signaling domain is a modified IFNGR1 signaling domain; and/or the first intracellular signaling domain is a modified IFNGR1
6727-109858-02 signaling domain and the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. In some examples, the amino acid sequence of the modified IFNGR1 intracellular signaling domain is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. In specific examples, the amino acid sequence of the modified IFNGR1 intracellular signaling domain comprises or consists of residues 267-489 of SEQ ID NO: 68; residues 267- 489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. In some examples, the wild-type IFNGR2 intracellular signaling domain includes residues 288-356 of SEQ ID NO: 148. In some examples of the chimeric IFNG receptors, the transmembrane domain of the first chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR1), such as a transmembrane domain from the same cytokine receptor as the first intracellular signaling domain, and/or the transmembrane domain of the second chimeric polypeptide is a heterologous transmembrane domain (a transmembrane domain that is not from IFNGR2), such as a transmembrane domain from the same cytokine receptor as the second intracellular signaling domain. In other examples, the transmembrane domain of the first chimeric polypeptide is an IFNGR1 transmembrane domain and/or the transmembrane domain of the second chimeric polypeptide is an IFNGR2 transmembrane domain. In particular aspects of the chimeric IFNG receptors, the amino acid sequence of the first chimeric polypeptide is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to SEQ ID NO: 1; SEQ ID NO: 2; SEQ ID NO: 3; SEQ ID NO: 4; SEQ ID NO: 5; SEQ ID NO: 6; SEQ ID NO: 7; SEQ ID NO: 8; SEQ ID NO: 9; SEQ ID NO: 10; SEQ ID NO: 11; SEQ ID NO: 12; SEQ ID NO: 13; SEQ ID NO: 14; SEQ ID NO: 15; SEQ ID NO: 16; SEQ ID NO: 17; SEQ ID NO: 18; SEQ ID NO: 19; SEQ ID NO: 20; SEQ ID NO: 21; SEQ ID NO: 21; SEQ ID NO: 22; SEQ ID NO: 23; SEQ ID NO: 24; SEQ ID NO: 25; SEQ ID NO: 26; SEQ ID NO: 27; residues 1-503 of SEQ ID NO: 28; residues 1-433 of SEQ ID NO: 29; residues 1-619 of SEQ ID NO: 30; residues 1-389 of SEQ ID NO: 31; residues 1-633 of SEQ ID NO: 32; residues 1-571 of SEQ ID NO: 33; residues 1-318 of SEQ ID NO: 34; residues 1-385 of SEQ ID NO: 35; residues 1-671 of SEQ ID NO: 36; residues 1-699 of SEQ ID NO: 37; residues 1-555 of SEQ ID NO: 38; residues 1-465 of SEQ ID NO: 39; residues 1-496 of SEQ ID NO: 40; residues 1-544 of SEQ ID NO: 41; residues 1-313 of SEQ ID NO: 42; residues 1-313 of SEQ ID NO: 43; residues 1-314 of SEQ ID NO: 44; residues 1-304 of SEQ ID NO: 45; residues 1-387 of SEQ ID NO: 46; residues 1-451 of SEQ ID NO: 47; residues 1-441 of SEQ ID NO: 48; residues 1-453 of SEQ ID NO: 49; residues 1-455 of SEQ ID NO: 50; residues 1-677 of SEQ ID NO: 51; residues 1-703 of SEQ ID NO: 52; residues 1-320 of SEQ ID NO: 53; residues 1-352 of SEQ ID NO: 54; residues 1-319 of SEQ ID NO: 55; residues 1-385 of SEQ ID NO: 56; residues 1-551 of SEQ ID NO: 57; residues 1-496 of SEQ ID NO: 58; residues 1-461 of SEQ ID NO: 59; residues 1-325 of SEQ ID NO: 60; residues 1-352 of SEQ ID NO: 61; residues 1-348 of SEQ ID NO: 62; residues 1-297 of SEQ ID NO: 63; residues 1-519 of SEQ ID NO: 64;
6727-109858-02 residues 1-588 of SEQ ID NO: 65; residues 1-591 of SEQ ID NO: 66; residues 1-548 of SEQ ID NO: 67; residues 1-489 of SEQ ID NO: 68; residues 1-489 of SEQ ID NO: 69; residues 1-472 of SEQ ID NO: 70; residues 1-489 of SEQ ID NO: 71; residues 1-497 of SEQ ID NO: 72; or residues 1-489 of SEQ ID NO: 73. In particular examples, the amino acid sequence of the first chimeric polypeptide comprises or consists of SEQ ID NO: 1; SEQ ID NO: 2; SEQ ID NO: 3; SEQ ID NO: 4; SEQ ID NO: 5; SEQ ID NO: 6; SEQ ID NO: 7; SEQ ID NO: 8; SEQ ID NO: 9; SEQ ID NO: 10; SEQ ID NO: 11; SEQ ID NO: 12; SEQ ID NO: 13; SEQ ID NO: 14; SEQ ID NO: 15; SEQ ID NO: 16; SEQ ID NO: 17; SEQ ID NO: 18; SEQ ID NO: 19; SEQ ID NO: 20; SEQ ID NO: 21; SEQ ID NO: 21; SEQ ID NO: 22; SEQ ID NO: 23; SEQ ID NO: 24; SEQ ID NO: 25; SEQ ID NO: 26; SEQ ID NO: 27; residues 1-503 of SEQ ID NO: 28; residues 1-433 of SEQ ID NO: 29; residues 1-619 of SEQ ID NO: 30; residues 1-389 of SEQ ID NO: 31; residues 1-633 of SEQ ID NO: 32; residues 1-571 of SEQ ID NO: 33; residues 1-318 of SEQ ID NO: 34; residues 1-385 of SEQ ID NO: 35; residues 1-671 of SEQ ID NO: 36; residues 1-699 of SEQ ID NO: 37; residues 1-555 of SEQ ID NO: 38; residues 1-465 of SEQ ID NO: 39; residues 1-496 of SEQ ID NO: 40; residues 1-544 of SEQ ID NO: 41; residues 1-313 of SEQ ID NO: 42; residues 1-313 of SEQ ID NO: 43; residues 1-314 of SEQ ID NO: 44; residues 1-304 of SEQ ID NO: 45; residues 1-387 of SEQ ID NO: 46; residues 1-451 of SEQ ID NO: 47; residues 1-441 of SEQ ID NO: 48; residues 1-453 of SEQ ID NO: 49; residues 1-455 of SEQ ID NO: 50; residues 1-677 of SEQ ID NO: 51; residues 1-703 of SEQ ID NO: 52; residues 1-320 of SEQ ID NO: 53; residues 1-352 of SEQ ID NO: 54; residues 1-319 of SEQ ID NO: 55; residues 1-385 of SEQ ID NO: 56; residues 1-551 of SEQ ID NO: 57; residues 1-496 of SEQ ID NO: 58; residues 1-461 of SEQ ID NO: 59; residues 1-325 of SEQ ID NO: 60; residues 1-352 of SEQ ID NO: 61; residues 1-348 of SEQ ID NO: 62; residues 1-297 of SEQ ID NO: 63; residues 1-519 of SEQ ID NO: 64; residues 1-588 of SEQ ID NO: 65; residues 1-591 of SEQ ID NO: 66; residues 1-548 of SEQ ID NO: 67; residues 1-489 of SEQ ID NO: 68; residues 1-489 of SEQ ID NO: 69; residues 1-472 of SEQ ID NO: 70; residues 1-489 of SEQ ID NO: 71; residues 1-497 of SEQ ID NO: 72; or residues 1-489 of SEQ ID NO: 73. In particular aspects of the chimeric IFNG receptors, the amino acid sequence of the second chimeric polypeptide is at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical to residues 531-1035 of SEQ ID NO: 28; residues 461-895 of SEQ ID NO: 29; residues 645-1297 of SEQ ID NO: 30; residues 417-807 of SEQ ID NO: 31; residues 661-1295 of SEQ ID NO: 32; residues 599-1171 of SEQ ID NO: 33; residues 346-1046 of SEQ ID NO: 34; residues 413- 879 of SEQ ID NO: 35; residues 699-1371 of SEQ ID NO: 36; residues 727-1053 of SEQ ID NO: 37; residues 535-936 of SEQ ID NO: 38; residues 493-846 of SEQ ID NO: 39; residues 524-877 of SEQ ID NO: 40; residues 572-1117 of SEQ ID NO: 41; residues 341-655 of SEQ ID NO: 42; residues 341-655 of SEQ ID NO: 43; residues 342-657 of SEQ ID NO: 44; residues 332-637 of SEQ ID NO: 45; residues 415-803 of SEQ ID NO: 46; residues 479-931 of SEQ ID NO: 47; residues 469-911 of SEQ ID NO: 48; residues 481- 935 of SEQ ID NO: 49; residues 483-939 of SEQ ID NO: 50; residues 705-1383 of SEQ ID NO: 51; residues 731-1053 of SEQ ID NO: 52; residues 348-1052 of SEQ ID NO: 53; residues 380-932 of SEQ ID NO: 54; residues 347-1051 of SEQ ID NO: 55; residues 413-875 of SEQ ID NO: 56; residues 579-932 of
6727-109858-02 SEQ ID NO: 57; residues 524-877 of SEQ ID NO: 58; residues 489-842 of SEQ ID NO: 59; residues 353- 1053 of SEQ ID NO: 60; residues 380-936 of SEQ ID NO: 61; residues 376-921 of SEQ ID NO: 62; residues 325-870 of SEQ ID NO: 63; residues 547-1092 of SEQ ID NO: 64; residues 616-967 of SEQ ID NO: 65; residues 619-943 of SEQ ID NO: 66; residues 576-900 of SEQ ID NO: 67; residues 517-853 of SEQ ID NO: 68; residues 517-853 of SEQ ID NO: 69; residues 500-836 of SEQ ID NO: 70; residues 517- 853 of SEQ ID NO: 71; residues 525-861 of SEQ ID NO: 72; or residues 517-853 of SEQ ID NO: 73. In particular examples, the amino acid sequence of the second chimeric polypeptide comprises or consists of residues 531-1035 of SEQ ID NO: 28; residues 461-895 of SEQ ID NO: 29; residues 645-1297 of SEQ ID NO: 30; residues 417-807 of SEQ ID NO: 31; residues 661-1295 of SEQ ID NO: 32; residues 599-1171 of SEQ ID NO: 33; residues 346-1046 of SEQ ID NO: 34; residues 413-879 of SEQ ID NO: 35; residues 699-1371 of SEQ ID NO: 36; residues 727-1053 of SEQ ID NO: 37; residues 535-936 of SEQ ID NO: 38; residues 493-846 of SEQ ID NO: 39; residues 524-877 of SEQ ID NO: 40; residues 572-1117 of SEQ ID NO: 41; residues 341-655 of SEQ ID NO: 42; residues 341-655 of SEQ ID NO: 43; residues 342- 657 of SEQ ID NO: 44; residues 332-637 of SEQ ID NO: 45; residues 415-803 of SEQ ID NO: 46; residues 479-931 of SEQ ID NO: 47; residues 469-911 of SEQ ID NO: 48; residues 481-935 of SEQ ID NO: 49; residues 483-939 of SEQ ID NO: 50; residues 705-1383 of SEQ ID NO: 51; residues 731-1053 of SEQ ID NO: 52; residues 348-1052 of SEQ ID NO: 53; residues 380-932 of SEQ ID NO: 54; residues 347-1051 of SEQ ID NO: 55; residues 413-875 of SEQ ID NO: 56; residues 579-932 of SEQ ID NO: 57; residues 524- 877 of SEQ ID NO: 58; residues 489-842 of SEQ ID NO: 59; residues 353-1053 of SEQ ID NO: 60; residues 380-936 of SEQ ID NO: 61; residues 376-921 of SEQ ID NO: 62; residues 325-870 of SEQ ID NO: 63; residues 547-1092 of SEQ ID NO: 64; residues 616-967 of SEQ ID NO: 65; residues 619-943 of SEQ ID NO: 66; residues 576-900 of SEQ ID NO: 67; residues 517-853 of SEQ ID NO: 68; residues 517-853 of SEQ ID NO: 69; residues 500-836 of SEQ ID NO: 70; residues 517-853 of SEQ ID NO: 71; residues 525- 861 of SEQ ID NO: 72; or residues 517-853 of SEQ ID NO: 73. Also provided are pharmaceutical compositions that include a nucleic acid molecule(s), modified immune cell or chimeric IFNG receptor disclosed herein and a pharmaceutically acceptable carrier. Further provided are methods of treating cancer in a subject. In some aspects, the method includes administering to the subject a therapeutically effective amount of a nucleic acid molecule(s), modified immune cell, chimeric IFNG receptor, or pharmaceutical composition disclosed herein. In some examples, the method further includes administering one or more additional anti-cancer therapies to the subject. IV. IFNGR1 Chimeric Polypeptide Sequences Provided below are the amino acid sequences of exemplary chimeric polypeptides that include, in the N-terminal to C-terminal direction, an extracellular domain from IFNGR1, a transmembrane domain (from IFNGR1 or another cytokine receptor), and an intracellular signaling domain from a heterologous cytokine receptor (or a modified IFNGR1 signaling domain). In the amino acid sequences of the chimeric IFNGR1 polypeptides listed below, the underlined portion of each sequence indicates the transmembrane
6727-109858-02 domain. The tables below each sequence specify the amino acid residues that correspond to each domain of the chimeric polypeptide. IFNGR1-EPORtm (SEQ ID NO: 1)
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTE DPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASS CSSALASKPSPEGASAASFEYTILDPSSQLLRPWTLCPELPPTPPHLKYLYLVVSDSGISTDYSSGDSQGAQGGLSDGPY SNPYENSLIPAAEPLPPSYVACS Domain Source Residues of SEQ ID NO: 1
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTE DPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASS
CSSALASKPSPEGASAASFEYTILDPSSQLLRP Domain Source Residues of 2
IFNGR1-GHRtm (SEQ ID NO: 3) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFPWLLIIIFGIFGLTVMLFVFLFSKQQRIKMLILPPVPVPKIKGIDPDLLKEGKLEEVNTILAIHDSYKPEFHSD DSWVEFIELDIDEPDEKTEESDTDRLLSSDHEKSHSNLGVKDGDSGRTSCCEPDILETDFNANDIHEGTSEVAQPQRLKG EADLLCLDQKNQNNSPYHDACPATQQPSVIQAEKNKPQPLPTEGAESTHQAAHIQLSNPSSLSNIDFYAQVSDITPAGSV VLSPGQKNKAGMSQCDMHPEMVSLCQENFLMDNAYFCEADAKKCIPVAPHIKVESHIQPSLNQEDIYITTESLTTAAGRP GTGEHVPGSEMPVPDYTSIHIVQSPQGLILNATALPLPDKEFLSSCGYVSTDQLNKIMP Domain Source Residues of
6727-109858-02 Transmembrane GHR 246-269 Intracellular GHR 270-619
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPS LLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQP Domain Source Residues of SEQ ID NO: 4
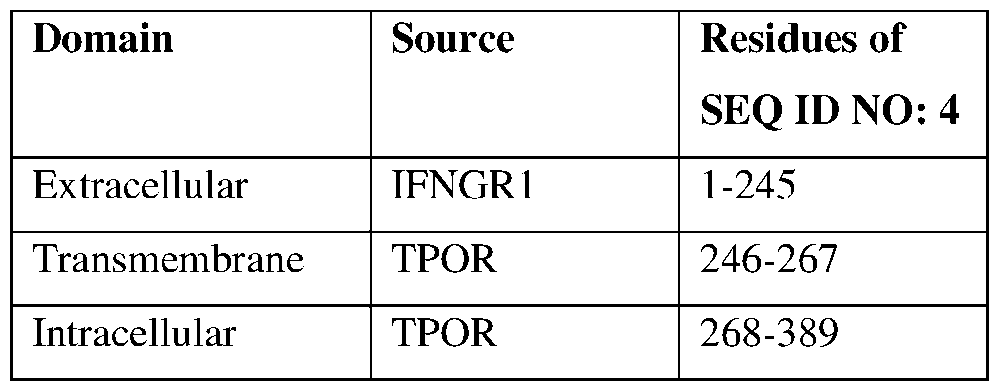
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKGKSEELLSALGCQDFPPTSDYED LLVEYLEVDDSEDQHLMSVHSKEHPSQGMKPTYLDPDTDSGRGSCDSPSLLSEKCEEPQANPSTFYDPEVIEKPENPETT HTWDPQCISMEGKIPYFHAGGSKCSTWPLPQPSQHNPRSSYHNITDVCELAVGPAGAPATLLNEAGKDALKSSQTIKSRE EGKATQQREVESFHSETDQDTPWLLPQEKTPFGSAKPLDYVEIHKVNKDGALSLLPKQRENSGKPKKPGTPENNKEYAKV SGVMDNNILVLVPDPHAKNVACFEESAKEAPPSLEQNQAEKALANFTATSSKCRLQLGGLDYLDPACFTHSFH Domain Source Residues of 5
IFNGR1-LEPRtm (SEQ ID NO: 6) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN
SSIKGAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWEDVPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLE PETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVCISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSK PSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQAFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDK KSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIRVLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHK IMENKMCDLTV Domain Source Residues of
6727-109858-02 Transmembrane LEPR 246-268 Intracellular LEPR 269-571
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFILISSLAILLMVSLLLLSLWKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVAL Domain Source Residues of SEQ ID NO: 7

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGVLALIVIFLTIAVLLALRFCGIYGYRLRRKWEEKIPNPSKSHLFQNGSAELWPPGSMSAFTSGSPPHQGPWGSRF PELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQPPSPQPGPPAASHTPEKQASSFDFNGPYLGPPH SRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAMGPGQAVEVERRPSQGAAGSPSLESGGGPAPPA LGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGASSVSLVPSLGLPSDQTPSLCPGLASGPPGAPGP VKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPTSPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSK PSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLPPWEVNKPGEVC Domain Source Residues of
IFNGR1-IL3Ratm (SEQ ID NO: 9) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTSLLIALGTLLALVCVFVICRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKT Domain Source Residues of
6727-109858-02 IFNGR1-IL2Rbtm (SEQ ID NO: 10) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIPWLGHLLVGLSGAFGFIILVYLLINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSP GGLAPEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEG VAGAPTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPP TPGVPDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHL Domain Source Residues of SEQ ID NO: 10

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGPILLTISILSFFSVALLVILACVLWKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFLDCQIHRVDDI QARDEVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSSSRSLDCRESG KNGPHVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQ Domain Source Residues of SE ID NO 11

IFNGR1-IL9Rtm (SEQ ID NO: 12) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGGNTLVAVSIFLLLTGPTYLLFKLSPRVKRIFYQNVPSPAMFFQPLYSVHNGNFQTWMGAHGAGVLLSQDCAGTPQ GALEPCVQEATALLTCGPARPWKSVALEEEQEGPGTRLPGNLSSEDVLPAGCTEWRVQTLAYLPQEDWAPTSLTRPAPPD SEGSRSSSSSSSSNNNNYCALGCYGGWHLSALPGNTQSSGPIPALACGLSCDHQGLETQQGVAWVLAGHCQRPGLHEDLQ GMLLPSVLSKARSWTF Domain Source Residues of

6727-109858-02 IFNGR1-INSRtm (SEQ ID NO: 13) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIIGPLIFVFLFSVVIGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQ GSFGMVYEGNARDIIKGEAETRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDL KSYLRSLRPEAENNPGRPPPTLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYR KGGKGLLPVRWMAPESLKDGVFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRM CWQFNPKMRPTFLEIVNLLKDDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGF KRSYEEHIPYTHMNGGKKNGRILTLPRSNPS Domain Source Residues of SEQ ID NO: 13

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAIVVPVCLAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNFTDVSVV EIEANDKKPFPEDLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYRHQVPSV QVFSRSESTQPLLDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRLKQQISD HISQSCGSGQMKMFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of 4
IFNGR1-CD28 (SEQ ID NO: 15) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS Domain Source Residues of
6727-109858-02 IFNGR1-CD28_YMFM (SEQ ID NO: 16) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMFMTPRRPGPTRKHYQPYAPPRDFAAYRS Domain Source Residues of SEQ ID NO: 16
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI
SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL Domain Source Residues of SEQ ID NO: 17
- Q : MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL Domain Source Residues of 8
IFNGR1-CD2 (SEQ ID NO: 19) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIYLIIGICGGGSLLMVFVALLVFYITKRKKQRSRRNDEELETRAHRVATEERGRKPHQIPASTPQNPATSQHPPP PPGHRSQAPSHRPPPPGHRVQHQPQKRPPAPSGTQVHQQKGPPLPRPRVQPKPPHGAAENSLSPSSN
6727-109858-02 Domain Source Residues of SEQ ID NO: 19
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLLIVTIVATMLVLAVTVTSLCSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNEL LPNLEKEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNSLILILLEPIP QYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKLTEQAKK Domain Source Residues of SEQ ID NO: 20
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGALVSGMCCALFLLILLTGVLCHRFHGLWYMKMMWAWLQAKRKPRKAPSRNICYDAFVSYSERDAYWVENLMVQEL ENFNPPFKLCLHKRDFIPGKWIIDNIIDSIEKSHKTVFVLSENFVKSEWCKYELDFSHFRLFDENNDAAILILLEPIEKK AIPQRFCKLRKIMNTKTYLEWPMDEAQREGFWVNLRAAIKS Domain Source Residues of 1
IFNGR1-TLR4 (SEQ ID NO: 22) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLC LHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELY RLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI Domain Source Residues of 2
6727-109858-02 Extracellular IFNGR1 1-245 Transmembrane TLR4 246-266
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIVTIGATMLVLAVTVTSLCIYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSEHDSAWVKSELV PYLEKEDIQICLHERNFVPGKSIVENIINCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLEPIPQ NSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKS Domain Source Residues of SEQ ID NO: 23
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIATGMVGALLLLLVVALGIGLFMRRRHIVRKRTLRRLLQERELVEPLTPSGEAPNQALLRILKETEFKKIKVLGS GAFGTVYKGLWIPEGEKVKIPVAIKELREATSPKANKEILDEAYVMASVDNPHVCRLLGICLTSTVQLITQLMPFGCLLD YVREHKDNIGSQYLLNWCVQIAKGMNYLEDRRLVHRDLAARNVLVKTPQHVKITDFGLAKLLGAEEKEYHAEGGKVPIKW MALESILHRIYTHQSDVWSYGVTVWELMTFGSKPYDGIPASEISSILEKGERLPQPPICTIDVYMIMVKCWMIDADSRPK FRELIIEFSKMARDPQRYLVIQGDERMHLPSPTDSNFYRALMDEEDMDDVVDADEYLIPQQGFFSSPSTSRTPLLSSLSA
TSNNSTVACIDRNGLQSCPIKEDSFLQRYSSDPTGALTEDSIDDTFLPVPEYINQSVPKRPAGSVQNPVYHNQPLNPAPS RDPHYQDPHSTAVGNPEYLNTVQPTCVNSTFDSPAHWAQKGSHQISLDNPDYQQDFFPKEAKPNGIFKGSTAENAEYLRV APQSSEFIGA Domain Source Residues of SEQ
IFNGR1-IGF1R (SEQ ID NO: 25) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIIALPVAVLLIVGGLVIMLYVFHRKRNNSRLGNGVLYASVNPEYFSAADVYVPDEWEVAREKITMSRELGQGSF GMVYEGVAKGVVKDEPETRVAIKTVNEAASMRERIEFLNEASVMKEFNCHHVVRLLGVVSQGQPTLVIMELMTRGDLKSY LRSLRPEMENNPVLAPPSLSKMIQMAGEIADGMAYLNANKFVHRDLAARNCMVAEDFTVKIGDFGMTRDIYETDYYRKGG KGLLPVRWMSPESLKDGVFTTYSDVWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQ YNPKMRPSFLEIISSIKEEMEPGFREVSFYYSEENKLPEPEELDLEPENMESVPLDPSASSSSLPLPDRHSGHKAENGPG PGVLVLRASFDERQPYAHMNGGRKNERALPLPQSSTC
6727-109858-02 Domain Source Residues of SEQ ID NO: 25

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGGLIAGVVSISTALLLLLGFFLWLKKRKQIKDLGSELVRYDARVHTPHLDRLVSARSVSPTTEMVSNESVDYRATF PEDQFPNSSQNGSCRQVQYPLTDMSPILTSGDSDISSPLLQNTVHIDLSALNPELVQAVQHVVIGPSSLIVHFNEVIGRG HFGCVYHGTLLDNDGKKIHCAVKSLNRITDIGEVSQFLTEGIIMKDFSHPNVLSLLGICLRSEGSPLVVLPYMKHGDLRN FIRNETHNPTVKDLIGFGLQVAKGMKYLASKKFVHRDLAARNCMLDEKFTVKVADFGLARDMYDKEYYSVHNKTGAKLPV KWMALESLQTQKFTTKSDVWSFGVLLWELMTRGAPPYPDVNTFDITVYLLQGRRLLQPEYCPDPLYEVMLKCWHPKAEMR PSFSELVSRISAIFSTFIGEHYVHVNATYVNVKCVAPYPSLLSSEDNADDEVDTRPASFWETS Domain Source Residues of SEQ ID NO: 26

- MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTSFILTIIVGIFLVVTIPLTFVWHRRLKNQKSAKEGVTVLINEDKELAELRGLAAGVGLANACYAIHTLPTQEEI ENLPAFPREKLTLRLLLGSGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLG VCLLNEPQYIILELMEGGDLLTYLRKARMATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTS PRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPESLMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYV QTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFFLNSIYKSRDEANNSGVINESFEGEDGDVICLN SDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHADKDFCQEKQVAYCPSGKPEGLNY ACLTHSGYGDGSD Domain Source Residues of 7

V. IFNGR1-IFNGR2 Chimeric Polypeptide Sequences Provided below are the amino acid sequences of exemplary chimeric polypeptides that include, in the N-terminal to C-terminal direction, a first extracellular domain from IFNGR1, a first transmembrane
6727-109858-02 domain (from IFNGR1 or another cytokine receptor), a first intracellular signaling domain from a heterologous cytokine receptor (or a modified IFNGR1 signaling domain), a 2A peptide sequence, a second extracellular domain from IFNGR2, a second transmembrane domain (from IFNGR2 or another cytokine receptor), and a second intracellular signaling domain from a heterologous cytokine receptor (or from IFNGR2). Due to the inclusion of the 2A peptide sequence, upon expression of the chimeric polypeptide in a host cell, two polypeptide chains are produced – one that includes the first extracellular domain, the first transmembrane domain, and the first intracellular signaling domain, and another that includes the second extracellular domain, the second transmembrane domain, and the second intracellular signaling domain. In the amino acid sequences of the IFNGR1-IFNGR2 chimeric polypeptides listed below, the underlined portions of each sequence indicate the transmembrane domains and italicized residues indicate a 2A sequence. The 2A sequence includes, in the N-terminal to C-terminal direction, a furin cleavage site (RAKR), a spacer (SGSG), and the P2A sequence (ATNFSLLKQAGDVEENPGP). The tables below each sequence specify the amino acid residues that correspond to each domain of the chimeric polypeptide. IFNGR1-2-EPORtm (SEQ ID NO: 28) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTE DPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASS CSSALASKPSPEGASAASFEYTILDPSSQLLRPWTLCPELPPTPPHLKYLYLVVSDSGISTDYSSGDSQGAQGGLSDGPY SNPYENSLIPAAEPLPPSYVACSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQL PAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFN VTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKG PFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQLILTLSLILVVILVLLTVLALLS HRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTEDPPASLEVLSERCWGTMQAVEPGTDDEG PLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASSCSSALASKPSPEGASAASFEYTILDPSS QLLRPWTLCPELPPTPPHLKYLYLVVSDSGISTDYSSGDSQGAQGGLSDGPYSNPYENSLIPAAEPLPPSYVACS Domain Source Residues of 8

IFNGR1-2-EPORtrtm (SEQ ID NO: 29) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
6727-109858-02 YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTE DPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASS CSSALASKPSPEGASAASFEYTILDPSSQLLRPRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAA AAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAAS PSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYW EKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQLILTLSLILVVIL VLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTEDPPASLEVLSERCWGTMQ AVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASSCSSALASKPSPEGASAAS FEYTILDPSSQLLRP Domain Source Residues of SEQ ID NO: 29

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFPWLLIIIFGIFGLTVMLFVFLFSKQQRIKMLILPPVPVPKIKGIDPDLLKEGKLEEVNTILAIHDSYKPEFHSD DSWVEFIELDIDEPDEKTEESDTDRLLSSDHEKSHSNLGVKDGDSGRTSCCEPDILETDFNANDIHEGTSEVAQPQRLKG EADLLCLDQKNQNNSPYHDACPATQQPSVIQAEKNKPQPLPTEGAESTHQAAHIQLSNPSSLSNIDFYAQVSDITPAGSV VLSPGQKNKAGMSQCDMHPEMVSLCQENFLMDNAYFCEADAKKCIPVAPHIKVESHIQPSLNQEDIYITTESLTTAAGRP GTGEHVPGSEMPVPDYTSIHIVQSPQGLILNATALPLPDKEFLSSCGYVSTDQLNKIMPRAKRSGSGATNFSLLKQAGDV EENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKW FTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGS LIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISC YETMADASTELQQFPWLLIIIFGIFGLTVMLFVFLFSKQQRIKMLILPPVPVPKIKGIDPDLLKEGKLEEVNTILAIHDS YKPEFHSDDSWVEFIELDIDEPDEKTEESDTDRLLSSDHEKSHSNLGVKDGDSGRTSCCEPDILETDFNANDIHEGTSEV AQPQRLKGEADLLCLDQKNQNNSPYHDACPATQQPSVIQAEKNKPQPLPTEGAESTHQAAHIQLSNPSSLSNIDFYAQVS DITPAGSVVLSPGQKNKAGMSQCDMHPEMVSLCQENFLMDNAYFCEADAKKCIPVAPHIKVESHIQPSLNQEDIYITTES LTTAAGRPGTGEHVPGSEMPVPDYTSIHIVQSPQGLILNATALPLPDKEFLSSCGYVSTDQLNKIMP Domain Source Residues of 0

6727-109858-02 Transmembrane-2 GHR 894-917 Intracellular-2 GHR 918-1267
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPS LLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQPRAKRSGSGATN FSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQ VQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPE NIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIF RVGHLSNISCYETMADASTELQQISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAA LSPPKATVSDTCEEVEPSLLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLP LSYWQQP Domain Source Residues of SEQ ID NO: 31

G - - m (S Q O: 3 ) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKGKSEELLSALGCQDFPPTSDYED LLVEYLEVDDSEDQHLMSVHSKEHPSQGMKPTYLDPDTDSGRGSCDSPSLLSEKCEEPQANPSTFYDPEVIEKPENPETT HTWDPQCISMEGKIPYFHAGGSKCSTWPLPQPSQHNPRSSYHNITDVCELAVGPAGAPATLLNEAGKDALKSSQTIKSRE EGKATQQREVESFHSETDQDTPWLLPQEKTPFGSAKPLDYVEIHKVNKDGALSLLPKQRENSGKPKKPGTPENNKEYAKV SGVMDNNILVLVPDPHAKNVACFEESAKEAPPSLEQNQAEKALANFTATSSKCRLQLGGLDYLDPACFTHSFHRAKRSGS
GATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRP VVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTV GPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNK SNIFRVGHLSNISCYETMADASTELQQTTVWISVAVLSAVICLIIVWAVALKGYSMVTCIFPPVPGPKIKGFDAHLLEKG KSEELLSALGCQDFPPTSDYEDLLVEYLEVDDSEDQHLMSVHSKEHPSQGMKPTYLDPDTDSGRGSCDSPSLLSEKCEEP QANPSTFYDPEVIEKPENPETTHTWDPQCISMEGKIPYFHAGGSKCSTWPLPQPSQHNPRSSYHNITDVCELAVGPAGAP ATLLNEAGKDALKSSQTIKSREEGKATQQREVESFHSETDQDTPWLLPQEKTPFGSAKPLDYVEIHKVNKDGALSLLPKQ RENSGKPKKPGTPENNKEYAKVSGVMDNNILVLVPDPHAKNVACFEESAKEAPPSLEQNQAEKALANFTATSSKCRLQLG GLDYLDPACFTHSFH Domain Source Residues of 2
6727-109858-02 Transmembrane-1 PRLR 246-269 Intracellular-1 PRLR 270-633
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWEDVPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLE PETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVCISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSK PSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQAFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDK KSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIRVLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHK IMENKMCDLTVRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYN AEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGAL HSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNL KPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWED VPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLEPETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVC ISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSKPSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQ AFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDKKSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIR VLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHKIMENKMCDLTV Domain Source Residues of E ID N 3

IFNGR1-IL3Ratm-IFNGR2-CSF2RBtm (SEQ ID NO: 34) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTSLLIALGTLLALVCVFVICRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKTRA KRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALS NSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHY RNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQ LLWNKSNIFRVGHLSNISCYETMADASTELQQVLALIVIFLTIAVLLALRFCGIYGYRLRRKWEEKIPNPSKSHLFQNGS AELWPPGSMSAFTSGSPPHQGPWGSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQPPSPQP GPPAASHTPEKQASSFDFNGPYLGPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAMGPGQA VEVERRPSQGAAGSPSLESGGGPAPPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGASSVSLV PSLGLPSDQTPSLCPGLASGPPGAPGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPTSPQPE
6727-109858-02 GLLVLQQVGDYCFLPGLGPGPLSLRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLPPWEVN KPGEVC Domain Source Residues of SEQ ID NO: 34
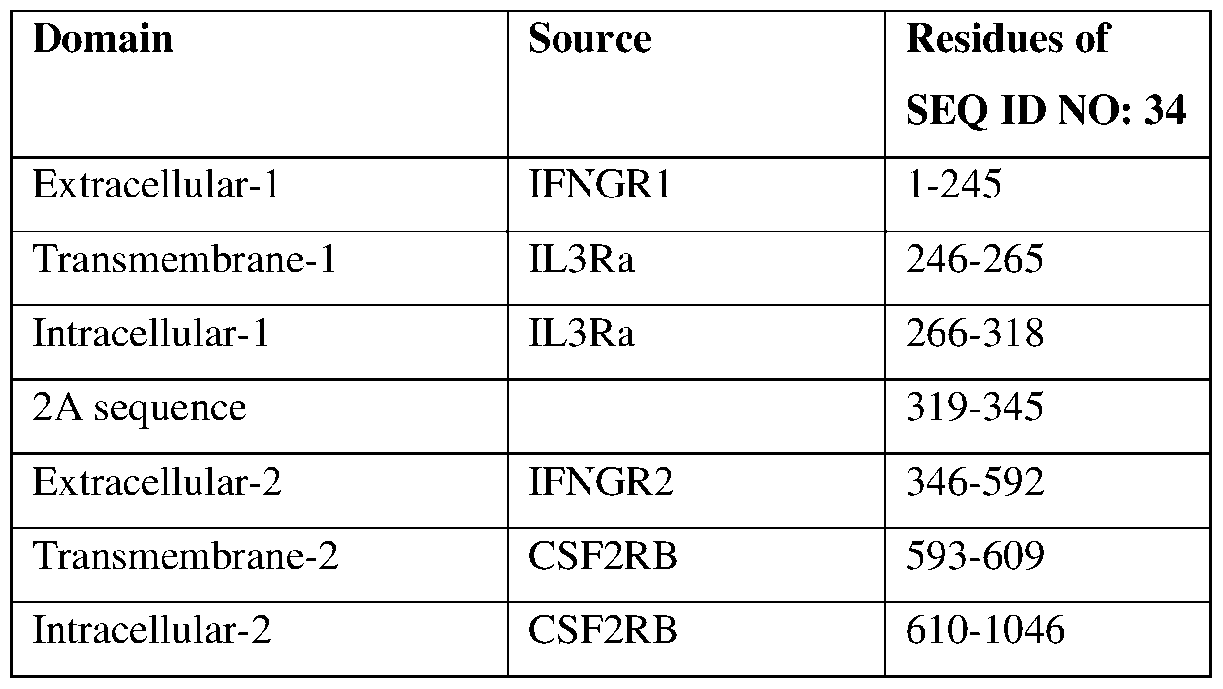
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFILISSLAILLMVSLLLLSLWKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES
GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVALRAKRSGSGATNFSLL KQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFK YTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEV TPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGH LSNISCYETMADASTELQQPILLTISILSFFSVALLVILACVLWKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNP ESFLDCQIHRVDDIQARDEVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAP ILSSSRSLDCRESGKNGPHVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQ Domain Source Residues of 5
IFNGR1-2-INSRtm (SEQ ID NO: 36) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIIGPLIFVFLFSVVIGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQ GSFGMVYEGNARDIIKGEAETRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDL
KSYLRSLRPEAENNPGRPPPTLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYR KGGKGLLPVRWMAPESLKDGVFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRM CWQFNPKMRPTFLEIVNLLKDDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGF
6727-109858-02 KRSYEEHIPYTHMNGGKKNGRILTLPRSNPSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAA PPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPS AGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEK GGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQIIIGPLIFVFLFSVV IGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQGSFGMVYEGNARDIIKGEAE TRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDLKSYLRSLRPEAENNPGRPPP TLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYRKGGKGLLPVRWMAPESLKDG VFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRMCWQFNPKMRPTFLEIVNLLK DDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGFKRSYEEHIPYTHMNGGKKNG RILTLPRSNPS Domain Source Residues of SEQ ID NO: 36

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGVLALIVIFLTIAVLLALRFCGIYGYRLRRKWEEKIPNPSKSHLFQNGSAELWPPGSMSAFTSGSPPHQGPWGSRF PELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQPPSPQPGPPAASHTPEKQASSFDFNGPYLGPPH SRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAMGPGQAVEVERRPSQGAAGSPSLESGGGPAPPA LGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGASSVSLVPSLGLPSDQTPSLCPGLASGPPGAPGP VKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPTSPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSK PSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLPPWEVNKPGEVCRAKRSGSGATNFSLLKQAGDV EENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKW FTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGS LIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISC YETMADASTELQQNLGSVYIYVLLIVGTLVCGIVLGFLFKRFLRIQRLFPPVPQIKDKLNDNHEVEDEIIWEEFTPEEGK GYREEVLTVKEIT Domain Source Residues of 7

6727-109858-02 IFNGR1-IL2Rbtm-IFNGR2-IL2Rgtm (SEQ ID NO: 38) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIPWLGHLLVGLSGAFGFIILVYLLINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSP GGLAPEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEG VAGAPTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPP TPGVPDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHLRAKRS GSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNST RPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNV TVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLW NKSNIFRVGHLSNISCYETMADASTELQQVVISVGSMGLIISLLCVYFWLERTMPRIPTLKNLEDLVTEYHGNFSAWSGV SKGLAESLQPDYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 38

g MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGPILLTISILSFFSVALLVILACVLWKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFLDCQIHRVDDI QARDEVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSSSRSLDCRESG KNGPHVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQRAKRSGSGATNFSLL KQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFK YTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEV TPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGH LSNISCYETMADASTELQQVVISVGSMGLIISLLCVYFWLERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGLAESLQP DYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of 9

6727-109858-02 IFNGR1-IL9Rtm-IFNGR2-IL2Rgtm (SEQ ID NO: 40) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGGNTLVAVSIFLLLTGPTYLLFKLSPRVKRIFYQNVPSPAMFFQPLYSVHNGNFQTWMGAHGAGVLLSQDCAGTPQ GALEPCVQEATALLTCGPARPWKSVALEEEQEGPGTRLPGNLSSEDVLPAGCTEWRVQTLAYLPQEDWAPTSLTRPAPPD SEGSRSSSSSSSSNNNNYCALGCYGGWHLSALPGNTQSSGPIPALACGLSCDHQGLETQQGVAWVLAGHCQRPGLHEDLQ GMLLPSVLSKARSWTFRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPK IRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRA ELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSI SLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVVISVGSMGLIISLLCVYFWLERTMPRIPT LKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 40

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAIVVPVCLAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNFTDVSVV EIEANDKKPFPEDLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYRHQVPSV QVFSRSESTQPLLDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRLKQQISD HISQSCGSGQMKMFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQRAKRSGSGATNFSLLK QAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKY TDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVT PGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHL SNISCYETMADASTELQQAIVVPVCLAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQ MYSDGNFTDVSVVEIEANDKKPFPEDLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYST VVHSGYRHQVPSVQVFSRSESTQPLLDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVN EEDFVRLKQQISDHISQSCGSGQMKMFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of 1

6727-109858-02 Intracellular-2 GP130 841-1117 IFNGR1-2-
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRAKRSGS GATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRP VVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTV GPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNK SNIFRVGHLSNISCYETMADASTELQQFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKH YQPYAPPRDFAAYRS Domain Source Residues of SEQ ID NO: 42

_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMFMTPRRPGPTRKHYQPYAPPRDFAAYRSRAKRSGS GATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRP VVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTV GPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNK SNIFRVGHLSNISCYETMADASTELQQFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMFMTPRRPGPTRKH YQPYAPPRDFAAYRS Domain Source Residues of 3

6727-109858-02 IFNGR1-2-4-1BB (SEQ ID NO: 44) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRAKRSG SGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTR PVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVT VGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWN KSNIFRVGHLSNISCYETMADASTELQQIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEE DGCSCRFPEEEEGGCEL Domain Source Residues of SEQ ID NO: 44

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTLRAKRSGSGATNFSLLK QAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKY TDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVT PGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHL SNISCYETMADASTELQQFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL Domain Source Residues of 5

IFNGR1-2-CD2 (SEQ ID NO: 46) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN
6727-109858-02 SSIKGIYLIIGICGGGSLLMVFVALLVFYITKRKKQRSRRNDEELETRAHRVATEERGRKPHQIPASTPQNPATSQHPPP PPGHRSQAPSHRPPPPGHRVQHQPQKRPPAPSGTQVHQQKGPPLPRPRVQPKPPHGAAENSLSPSSNRAKRSGSGATNFS LLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQ FKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENI EVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRV GHLSNISCYETMADASTELQQIYLIIGICGGGSLLMVFVALLVFYITKRKKQRSRRNDEELETRAHRVATEERGRKPHQI PASTPQNPATSQHPPPPPGHRSQAPSHRPPPPGHRVQHQPQKRPPAPSGTQVHQQKGPPLPRPRVQPKPPHGAAENSLSP SSN Domain Source Residues of SEQ ID NO: 46

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLLIVTIVATMLVLAVTVTSLCSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNEL LPNLEKEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNSLILILLEPIP QYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKLTEQAKKRAKRSGSGATNFSLLKQAGDVEENPGPMR PTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSI GVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSP FDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADAS TELQQLLIVTIVATMLVLAVTVTSLCSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNEL LPNLEKEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNSLILILLEPIP QYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKLTEQAKK Domain Source Residues of 7

6727-109858-02 IFNGR1-2-TLR2 (SEQ ID NO: 48) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGALVSGMCCALFLLILLTGVLCHRFHGLWYMKMMWAWLQAKRKPRKAPSRNICYDAFVSYSERDAYWVENLMVQEL ENFNPPFKLCLHKRDFIPGKWIIDNIIDSIEKSHKTVFVLSENFVKSEWCKYELDFSHFRLFDENNDAAILILLEPIEKK AIPQRFCKLRKIMNTKTYLEWPMDEAQREGFWVNLRAAIKSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLL LGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITAT ECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAF FCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQALVSG MCCALFLLILLTGVLCHRFHGLWYMKMMWAWLQAKRKPRKAPSRNICYDAFVSYSERDAYWVENLMVQELENFNPPFKLC LHKRDFIPGKWIIDNIIDSIEKSHKTVFVLSENFVKSEWCKYELDFSHFRLFDENNDAAILILLEPIEKKAIPQRFCKLR KIMNTKTYLEWPMDEAQREGFWVNLRAAIKS Domain Source Residues of SEQ ID NO: 48

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLC LHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELY RLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSIRAKRSGSGATNFSLLKQAGDVEENPGP MRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIM SIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFS SPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMAD ASTELQQTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQ LCLHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVE LYRLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI Domain Source Residues of 9

6727-109858-02 Intracellular-2 TLR4 749-935

MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIVTIGATMLVLAVTVTSLCIYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSEHDSAWVKSELV PYLEKEDIQICLHERNFVPGKSIVENIINCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLEPIPQ NSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKSRAKRSGSGATNFSLLKQAGDVEENP GPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTAD IMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIR FSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETM ADASTELQQLIVTIGATMLVLAVTVTSLCIYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSEHDSAWVK SELVPYLEKEDIQICLHERNFVPGKSIVENIINCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLE PIPQNSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKS Domain Source Residues of SEQ ID NO: 50

- - Q : MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIIALPVAVLLIVGGLVIMLYVFHRKRNNSRLGNGVLYASVNPEYFSAADVYVPDEWEVAREKITMSRELGQGSF GMVYEGVAKGVVKDEPETRVAIKTVNEAASMRERIEFLNEASVMKEFNCHHVVRLLGVVSQGQPTLVIMELMTRGDLKSY LRSLRPEMENNPVLAPPSLSKMIQMAGEIADGMAYLNANKFVHRDLAARNCMVAEDFTVKIGDFGMTRDIYETDYYRKGG KGLLPVRWMSPESLKDGVFTTYSDVWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQ YNPKMRPSFLEIISSIKEEMEPGFREVSFYYSEENKLPEPEELDLEPENMESVPLDPSASSSSLPLPDRHSGHKAENGPG PGVLVLRASFDERQPYAHMNGGRKNERALPLPQSSTCRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVF AAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDF TAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYY VHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQLIIALPVAV
LLIVGGLVIMLYVFHRKRNNSRLGNGVLYASVNPEYFSAADVYVPDEWEVAREKITMSRELGQGSFGMVYEGVAKGVVKD EPETRVAIKTVNEAASMRERIEFLNEASVMKEFNCHHVVRLLGVVSQGQPTLVIMELMTRGDLKSYLRSLRPEMENNPVL APPSLSKMIQMAGEIADGMAYLNANKFVHRDLAARNCMVAEDFTVKIGDFGMTRDIYETDYYRKGGKGLLPVRWMSPESL KDGVFTTYSDVWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEIIS SIKEEMEPGFREVSFYYSEENKLPEPEELDLEPENMESVPLDPSASSSSLPLPDRHSGHKAENGPGPGVLVLRASFDERQ PYAHMNGGRKNERALPLPQSSTC Domain Source Residues of 1
6727-109858-02 Transmembrane-1 IGF1R 246-266 Intracellular-1 IGF1R 267-677
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIRFCGIYGYRLRRKWEEKIPNPSKSHLFQNGSAELWPPGSMSAFTSGSPPHQGPW GSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQPPSPQPGPPAASHTPEKQASSFDFNGPYL GPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAMGPGQAVEVERRPSQGAAGSPSLESGGGP APPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGASSVSLVPSLGLPSDQTPSLCPGLASGPPG APGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPTSPQPEGLLVLQQVGDYCFLPGLGPGPLS LRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLPPWEVNKPGEVCRAKRSGSGATNFSLLKQ AGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYT DSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTP GEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLS NISCYETMADASTELQQVILISVGTFSLLSVLAGACFFKRFLRIQRLFPPVPQIKDKLNDNHEVEDEIIWEEFTPEEGKG YREEVLTVKEIT Domain Source Residues of SE ID NO 52

IFNGR1tm-GMCSFRA_IFNGR2tm-CSF2RB (SEQ ID NO: 53) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIKRFLRIQRLFPPVPQIKDKLNDNHEVEDEIIWEEFTPEEGKGYREEVLTVKEIT RAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVA LSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQ HYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQ AQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFRFCGIYGYRLRRKWEEKIPNPSKSH LFQNGSAELWPPGSMSAFTSGSPPHQGPWGSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQ PPSPQPGPPAASHTPEKQASSFDFNGPYLGPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQA MGPGQAVEVERRPSQGAAGSPSLESGGGPAPPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGA SSVSLVPSLGLPSDQTPSLCPGLASGPPGAPGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSP TSPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSL PPWEVNKPGEVC
6727-109858-02 Domain Source Residues of SEQ ID NO: 53

_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSERLCLVSEIPP KGGALGEGPGASPCNQHSPYWAPPCYTLKPETRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAA APPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASP
SAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWE KGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSV LAGACFFNCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSPGGLAPEISPLEVLERDKVTQLLL QQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEGVAGAPTGSSPQPLQPLSGEDDAY CTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPPTPGVPDLVDFQPPPELVLREAGE EVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHL Domain Source Residues of 4
IFNGR1tm-IL3RA_IFNGR2tm-CSF2RB (SEQ ID NO: 55) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKTR AKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVAL SNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQH
YRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQA QLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFRFCGIYGYRLRRKWEEKIPNPSKSHL FQNGSAELWPPGSMSAFTSGSPPHQGPWGSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQP
6727-109858-02 PSPQPGPPAASHTPEKQASSFDFNGPYLGPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAM GPGQAVEVERRPSQGAAGSPSLESGGGPAPPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGAS SVSLVPSLGLPSDQTPSLCPGLASGPPGAPGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPT SPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLP PWEVNKPGEVC Domain Source Residues of SEQ ID NO: 55
_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI
SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVALRAKRSGSGATNFSLL KQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFK YTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEV TPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGH LSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFL DCQIHRVDDIQARDEVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSS SRSLDCRESGKNGPHVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQ Domain Source Residues of 6
IFNGR1tm-IL2RB_IFNGR2tm-IL2RG (SEQ ID NO: 57) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSPGGLA PEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEGVAGA
6727-109858-02 PTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPPTPGV PDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHLRAKRSGSGA TNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVV YQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGP PENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSN IFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGL AESLQPDYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 57

_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIKLSPRVKRIFYQNVPSPAMFFQPLYSVHNGNFQTWMGAHGAGVLLSQDCAGTPQ GALEPCVQEATALLTCGPARPWKSVALEEEQEGPGTRLPGNLSSEDVLPAGCTEWRVQTLAYLPQEDWAPTSLTRPAPPD SEGSRSSSSSSSSNNNNYCALGCYGGWHLSALPGNTQSSGPIPALACGLSCDHQGLETQQGVAWVLAGHCQRPGLHEDLQ GMLLPSVLSKARSWTFRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPK IRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRA ELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSI SLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPT LKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of 8
IFNGR1tm-IL7RA_IFNGR2tm-IL2RG (SEQ ID NO: 59)
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN
6727-109858-02 SSIKGSLWIPVVAALLLFLVLSLVFIKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFLDCQIHRVDDIQARD EVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSSSRSLDCRESGKNGP HVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQRAKRSGSGATNFSLLKQAG DVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDS KWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGE GSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNI SCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSE RLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 59

_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGNLGSVYIYVLLIVGTLVCGIVLGFLFKRFLRIQRLFPPVPQIKDKLNDNHEVEDEIIWEEFTPEEGKGYREEVLT VKEITRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLS WEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVT MPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVY CLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVLALIVIFLTIAVLLALRFCGIYGYRLRRKWEEKIPNPSKS HLFQNGSAELWPPGSMSAFTSGSPPHQGPWGSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTE QPPSPQPGPPAASHTPEKQASSFDFNGPYLGPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQ AMGPGQAVEVERRPSQGAAGSPSLESGGGPAPPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSG ASSVSLVPSLGLPSDQTPSLCPGLASGPPGAPGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVS PTSPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLS LPPWEVNKPGEVC Domain Source Residues of 0

6727-109858-02 IFNGR1-IL2RG_IFNGR2-IL2RB (SEQ ID NO: 61) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGVVISVGSMGLIISLLCVYFWLERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSERLCLVSEIPP KGGALGEGPGASPCNQHSPYWAPPCYTLKPETRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAA APPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASP SAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWE KGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQIPWLGHLLVGLSGA FGFIILVYLLINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSPGGLAPEISPLEVLERDKVT QLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEGVAGAPTGSSPQPLQPLSGE DDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPPTPGVPDLVDFQPPPELVLR EAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHL Domain Source Residues of SEQ ID NO: 61

_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTFLVAGGSLAFGTLLCIAIVLRFKKTWKLRALKEGKTSMHPPYSLGQLVPERPRPTPVLVPLISPPVSPSSLGSD NTSSHNRPDARDPRSPYDISNTDYFFPRRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPD PLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGF PMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGI QQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQAIVVPVCLAFLLTTLLGV LFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNFTDVSVVEIEANDKKPFPEDLKSLDLFKKE KINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYRHQVPSVQVFSRSESTQPLLDSEERPEDLQ LVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRLKQQISDHISQSCGSGQMKMFQEVSAADAF GPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of 2

6727-109858-02 Intracellular-2 GP130 645-921
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLGILSFLGLVAGALALGLWLRLRRGGKDGSPKPGFLASVIPVDRRPGAPNLRAKRSGSGATNFSLLKQAGDVEE NPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFT ADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLI IRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYE TMADASTELQQAIVVPVCLAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNF TDVSVVEIEANDKKPFPEDLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYR HQVPSVQVFSRSESTQPLLDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRL KQQISDHISQSCGSGQMKMFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of SEQ ID NO: 63

- _ - Q : MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLLLGMIVFAVMLSILSLIGIFNRSFRTGIKRRILLLIPKWLYEDIPNMKNSNVVKMLQENSELMNNNSSEQVLYV DPMITEIKEIFIPEHKPTDYKKENTGPLETRDYPQNSLFDNTTVVYIPDLNTGYKPQISNFLPEGSHLSNNNEITSLTLK PPVDSLDSGNNPRLQKHPNFAFSVSSVNSLSNTIFLGELSLILNQGECSSPDIQNSVEEETTMLLENDSPSETIPEQTLL PDEFVSCLGIVNEELPSINTYFPQNILESHFNRISLLEKRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLG VFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATEC DFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFC YYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQAIVVPVC LAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNFTDVSVVEIEANDKKPFPE DLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYRHQVPSVQVFSRSESTQPL LDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRLKQQISDHISQSCGSGQMK
MFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of 4
6727-109858-02 Extracellular-2 IFNGR2 547-793 Transmembrane-2 GP130 794-815
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGVIIFFAFVLLLSGALAYCLALQLYVRRRKKLPSVLLFKKPSPFIFISQRPSPETQDTIHPLDEEAFLKVSPELKN LDLHGSTDSGFGSTKPSLQTEEPQFLLPDPHPQADRTLGNREPPVLGDSCSSGSSNSTDSGICLQEPSLSPSTGPTWEQQ VGSNSRGQDDSGIDLVQNSEGRAGDTQGGSALGHHSPPEPEVPGEEDPAAVAFQGYLRQTRCAEEKATKTGCLEEESPLT DGLGPKFGRCLVDEAGLHPPALAKGYLKQDPLEMTLASSGAPTGQWNQPTEEWSLLALSSCSDLGISDWSFAHDLAPLGC VAAPGGLLGSFNSDLVTLPLISSLQSSERAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPD PLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGF PMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGI QQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQWMVAVILMASVFMVCLAL LGCFALLWCVYKKTKYAFSPRNSLPQHLKEFLGHPHHNTLLFFSFPLSDENDVFDKLSVIAEDSESGKQNPGDSCSLGTP PGQGPQS Domain Source Residues of SEQ ID NO: 65

IFNGR1-IL22R_IFNGR2-IL20RB (SEQ ID NO: 66) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGYSFSGAFLFSMGFLVAVLCYLSYRYVTKPPAPPNSLNVQRVLTFQPLRFIQEHVLIPVFDLSGPSSLAQPVQYSQ IRVSGPREPAGAPQRHSLSEITYLGQPDISILQPSNVPPPQILSPLSYAPNAAPEVGPPSYAPQVTPEAQFPFYAPQAIS KVQPSSYAPQATPDSWPPSYGVCMEGSGKDSPTGTLSSPKHLRPKGQLQKEPPAGSCMLGGLSLQEVTSLAMEESQEAKS LHQPLGICTDRTSDPNVLHSGEEGTPQYLKGQLPLLSSVQIEGHPMSLPLQPPSRPCSPSDQGPSPWGLLESLVCPKDEA KSPAPETSDLEQPTELDSLFRGLALTVQWESRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAA PPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPS AGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEK GGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVLALFAFVGFMLILV VVPLFVWKMGRLLQYSCCPVVVLPDTLKITNSPQKLISCRREEVDACATAVMSPEELLRAWIS Domain Source Residues of 6

6727-109858-02 Intracellular-1 IL22R 267-591 2A sequence 592-618
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIFWYVLPVSITVFLFSVMGYSIYRYIHVGKEKHPANLILIYGNEFDKRFFVPAEKIVINFITLNISDDSKISHQ DMSLLGKSSDVSSLNDPQPSGNLRPPQEEEEVKHLGYASHLMEIFCDSEENTEGTSLTQQESLSRTIPPDKTVIEYEYDV RTTDICAGPEEQELSLQEEVSTQGTLLESQAALAVLGPQTLQYSYTPQLQDLDPLAQEHTDSEEGPEEEPSTTLVDWDPQ TGRLCIPSLSSFDQDSEGCEPSEGDGLGEEGLLSRLYEEPAPDRPPGENETYLMQFMEEWGLYVQMENRAKRSGSGATNF
SLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQV QFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPEN IEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFR VGHLSNISCYETMADASTELQQVLALFAFVGFMLILVVVPLFVWKMGRLLQYSCCPVVVLPDTLKITNSPQKLISCRREE VDACATAVMSPEELLRAWIS Domain Source Residues of SEQ ID NO: 67
IFNGR1-2RB-S5_IFNGR2 (SEQ ID NO: 68) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDAYLSLDVLVDLLVDDSGKESLIGYR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE
QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of 8
6727-109858-02 Transmembrane-1 IFNGR1 246-266 Intracellular-1 IFNGR1-2RB-S5 267-489
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDAYLSLDVLVDLLVDDSGKESLIGFR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 69

IFNGR1-2RB-Cterm20_IFNGR2 (SEQ ID NO: 70) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPNTDAYLSLQELQGQDPTHLVRAKRSGSG ATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPV VYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVG PPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKS NIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTPPSIPLQIEEYLKDPTQP ILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of 0

6727-109858-02 Transmembrane-1 IFNGR1 246-266 Intracellular-1 IFNGR1-2RB-Cterm20 267-472
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD
YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPMDNAYFCEAVLVDLLVDDSGKEQEDIYI TTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 71

IFNGR1-GHR-Cyt45_IFNGR2 (SEQ ID NO: 72) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPMDNAYFCEADAKKCIPVAPHIKVESHIQ PSLNQEDIYITTESLTTRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHP KIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLR AELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNS ISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGL IKYWFHTPPSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of 2

6727-109858-02 Extracellular-1 IFNGR1 1-245 Transmembrane-1 IFNGR1 246-266
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDTYLVLDVLVDLLVDDSGKESLIGYR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 73

VI. Nucleic Acid Sequences Encoding IFNGR Chimeric Polypeptides Provided below are exemplary codon-optimized nucleic acid sequences encoding chimeric IFNGR1 polypeptides that include, in the N-terminal to C-terminal direction, an extracellular domain from IFNGR1, a transmembrane domain (from IFNGR1 or another cytokine receptor), and an intracellular signaling domain from a heterologous cytokine receptor (or a modified IFNGR1 signaling domain). IFNGR1-EPORtm (SEQ ID NO: 74) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC
6727-109858-02 TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCCTGATCCTGACCCTGTCCCTGATCCTGGTTGTGATCCTGGTCCTGCTGACAGTGCTGGCCCTGCT GAGCCACCGGAGAGCCCTGAAACAGAAGATCTGGCCTGGCATCCCTTCTCCTGAGAGCGAGTTCGAGGGACTGTTTACCA CCCACAAGGGCAATTTCCAGCTGTGGCTTTATCAGAACGACGGCTGCCTGTGGTGGAGCCCCTGCACCCCGTTCACAGAG GATCCCCCCGCTAGCCTGGAAGTGCTGTCTGAACGGTGCTGGGGAACAATGCAGGCCGTGGAACCTGGTACAGACGACGA GGGCCCCCTGCTCGAACCCGTGGGCAGCGAGCACGCCCAGGACACCTACCTGGTGCTGGACAAGTGGCTGCTGCCTAGAA ACCCCCCCAGCGAGGACCTGCCTGGCCCTGGAGGCAGCGTGGACATCGTGGCTATGGACGAGGGCTCTGAGGCCTCTTCT TGTAGCAGCGCCCTGGCCTCAAAGCCTAGCCCTGAGGGCGCCTCTGCCGCCTCCTTCGAGTACACCATCCTGGATCCTAG CAGCCAGCTGCTGAGACCTTGGACCCTGTGCCCCGAACTGCCACCTACCCCTCCCCATCTGAAGTACCTGTACCTGGTGG TGTCCGATAGCGGCATCAGCACCGATTACAGCTCCGGCGACAGCCAAGGCGCTCAGGGCGGCCTGTCTGATGGACCATAC AGCAACCCTTACGAGAACAGCCTCATTCCTGCCGCTGAACCACTGCCTCCAAGCTACGTGGCCTGTAGCTGATAA
IFNGR1-EPORtrtm (SEQ ID NO: 75) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG
CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCCTGATTCTGACCCTGTCTCTGATCCTGGTCGTGATCCTGGTTCTGCTTACAGTGCTGGCTCTGCT GAGCCACAGACGGGCCCTGAAGCAGAAAATCTGGCCTGGCATCCCCAGCCCCGAGAGCGAGTTCGAGGGCCTGTTCACCA CCCACAAGGGCAATTTCCAACTGTGGCTGTACCAGAACGACGGCTGTCTGTGGTGGTCCCCGTGCACCCCTTTCACAGAG GACCCTCCAGCTAGCCTGGAAGTGCTGAGCGAACGGTGCTGGGGCACAATGCAGGCCGTGGAACCTGGAACAGACGATGA GGGCCCTCTGCTCGAGCCTGTGGGCAGCGAGCACGCCCAGGACACCTACCTGGTGCTGGACAAGTGGCTGCTGCCTAGAA ACCCCCCCAGCGAAGATCTGCCCGGACCTGGCGGCAGCGTGGACATCGTGGCTATGGACGAGGGATCTGAAGCCAGCAGC TGCAGCAGCGCCCTGGCCAGCAAGCCTTCTCCAGAAGGCGCCTCCGCCGCTTCTTTTGAGTACACCATCCTGGATCCTAG CTCCCAGCTGCTGAGACCTTGATAA IFNGR1-GHRtm (SEQ ID NO: 76) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA
TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCTTTCCTTGGCTGCTGATCATCATCTTTGGCATCTTCGGCCTGACAGTGATGCTGTTCGTGTTCCT GTTCAGCAAGCAGCAGAGAATCAAGATGCTGATCCTGCCACCTGTTCCTGTGCCCAAGATCAAGGGAATCGATCCTGATC TGCTGAAGGAAGGCAAGCTGGAAGAAGTGAACACCATCCTGGCCATCCACGATAGCTATAAGCCCGAGTTTCACAGCGAC GACAGCTGGGTGGAGTTCATCGAGCTGGATATCGACGAGCCTGATGAGAAGACCGAGGAATCTGACACCGACCGGCTGCT GAGCAGCGACCACGAGAAAAGCCACTCCAACCTGGGCGTGAAGGACGGCGACAGCGGCCGGACCTCTTGTTGTGAACCCG ATATTCTCGAGACAGACTTCAACGCCAACGACATCCATGAGGGCACCAGCGAGGTGGCTCAGCCCCAAAGACTCAAAGGA GAAGCCGATCTGCTGTGCCTGGACCAGAAGAACCAGAACAACAGCCCCTACCACGACGCCTGCCCCGCCACCCAGCAACC TTCCGTGATCCAGGCTGAAAAAAACAAGCCTCAGCCTCTGCCCACCGAGGGCGCCGAGAGCACCCACCAGGCCGCCCACA TCCAACTGAGCAATCCTAGCAGCCTGTCTAATATCGACTTCTACGCCCAGGTGTCCGACATTACACCTGCCGGCAGCGTG GTGCTGTCCCCGGGACAGAAAAACAAGGCCGGCATGAGCCAGTGCGACATGCACCCTGAGATGGTCTCCCTATGTCAGGA GAACTTCCTGATGGACAACGCTTACTTCTGCGAGGCCGACGCCAAGAAGTGCATCCCCGTGGCCCCTCACATCAAGGTGG AAAGCCACATCCAGCCAAGCCTGAATCAGGAGGACATCTACATCACCACAGAGTCTCTGACCACCGCTGCTGGCAGACCT GGAACAGGCGAGCACGTGCCAGGCTCTGAGATGCCTGTCCCTGACTACACCAGCATCCATATTGTGCAGAGCCCTCAGGG CCTGATCCTGAATGCCACAGCCCTGCCTCTGCCTGATAAGGAGTTCCTGTCTAGCTGCGGCTACGTGTCTACAGATCAGC TGAACAAAATCATGCCCTGATAA
IFNGR1-TPORtm (SEQ ID NO: 77) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC
6727-109858-02 CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCATCAGCCTGGTGACCGCCCTGCACCTGGTCCTGGGACTGTCCGCCGTGCTGGGCCTGCTGCTGCT GAGATGGCAGTTCCCCGCTCACTACCGGAGACTGCGGCACGCCCTGTGGCCTAGCCTGCCCGACCTGCATAGAGTGCTGG GCCAGTACCTGAGAGATACAGCCGCTCTGTCTCCTCCTAAGGCCACAGTGTCCGACACCTGCGAGGAAGTGGAACCTTCT CTGCTCGAGATCCTGCCCAAGTCCAGCGAGCGGACACCTCTGCCTCTTTGTAGCAGCCAGGCCCAGATGGACTACAGAAG GCTGCAGCCTAGCTGTCTGGGCACCATGCCTCTGAGCGTGTGCCCTCCAATGGCCGAGAGCGGCAGCTGCTGCACCACCC ACATCGCCAACCACAGCTACCTGCCACTGTCTTATTGGCAACAGCCCTGATAA
IFNGR1-PRLRtm (SEQ ID NO: 78) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG
CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCACAACCGTGTGGATCAGCGTTGCTGTGCTGTCTGCTGTGATCTGCCTGATCATCGTGTGGGCCGT GGCCCTGAAGGGATATAGCATGGTGACCTGTATCTTCCCCCCCGTGCCCGGCCCCAAGATTAAGGGCTTCGACGCCCACC TGCTTGAGAAGGGAAAATCTGAGGAACTGCTGAGCGCCCTGGGCTGCCAGGATTTCCCTCCAACCAGTGATTACGAGGAC CTGCTGGTGGAGTACCTGGAAGTGGACGACTCCGAAGATCAGCATCTGATGAGCGTGCACAGCAAGGAACACCCCTCCCA GGGCATGAAGCCTACATACCTGGATCCTGATACCGATTCTGGCAGAGGCAGCTGCGACAGCCCCAGCCTGCTGAGCGAGA AGTGTGAAGAGCCTCAAGCTAATCCTAGCACCTTCTACGACCCTGAGGTGATCGAGAAACCTGAGAATCCTGAAACCACA CACACCTGGGACCCTCAGTGCATCAGCATGGAGGGCAAAATCCCCTACTTCCATGCCGGCGGCTCTAAGTGCAGCACATG GCCTCTGCCTCAACCTAGCCAGCACAACCCCAGATCTAGCTACCACAATATCACCGACGTGTGCGAGCTGGCCGTGGGCC CTGCTGGAGCCCCTGCCACCCTGCTCAACGAGGCCGGAAAAGATGCCCTGAAGAGCTCCCAGACCATCAAGAGCAGAGAG GAGGGCAAGGCCACACAGCAGCGGGAAGTCGAGAGCTTCCACTCTGAGACAGACCAGGACACCCCTTGGCTGCTGCCACA AGAGAAGACCCCCTTCGGCAGCGCTAAACCTCTGGACTACGTGGAAATCCACAAGGTGAACAAGGACGGCGCCCTGAGCC TGCTGCCTAAGCAGCGGGAAAACAGCGGCAAGCCGAAAAAGCCAGGCACACCTGAGAACAACAAGGAATACGCCAAGGTG TCCGGCGTGATGGACAACAACATCCTGGTCCTGGTGCCTGACCCCCACGCCAAGAACGTGGCCTGTTTTGAGGAAAGCGC CAAGGAAGCCCCTCCTAGCCTCGAGCAGAACCAGGCCGAGAAGGCCCTGGCTAACTTCACCGCCACATCTAGCAAATGCA GACTGCAGCTGGGCGGACTGGACTACCTGGACCCCGCCTGCTTCACCCACAGCTTTCACTGATAA IFNGR1-LEPRtm (SEQ ID NO: 79) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCGCTGGCCTCTACGTGATCGTGCCTGTGATCATCTCTAGCAGCATTCTGCTGCTGGGAACCCTGCT TATTTCTCACCAGCGGATGAAAAAACTGTTCTGGGAAGATGTGCCCAATCCTAAGAATTGCAGCTGGGCCCAGGGCCTGA ACTTCCAAAAGCCTGAGACATTTGAGCACCTGTTCATCAAGCACACCGCCAGCGTCACATGCGGCCCTCTGCTGCTGGAA CCTGAGACAATCAGCGAGGATATCTCCGTCGACACCAGCTGGAAGAACAAGGACGAGATGATGCCCACCACCGTGGTGTC TCTGCTGTCTACAACAGATCTGGAGAAGGGCAGCGTGTGCATCAGCGATCAGTTCAACTCTGTGAACTTCAGCGAAGCCG AGGGCACCGAGGTGACCTACGAGGATGAGTCTCAGAGACAGCCTTTCGTTAAGTACGCCACACTGATCAGTAATTCTAAG CCCTCCGAAACCGGAGAGGAACAGGGCCTGATCAACTCCAGCGTGACCAAGTGCTTCAGCAGCAAGAACAGCCCCCTGAA AGACAGCTTCTCTAATAGCAGCTGGGAGATCGAGGCTCAGGCCTTCTTCATCCTGAGCGACCAGCATCCTAACATCATCT CCCCTCACCTGACCTTCAGCGAGGGACTCGACGAGCTGCTGAAGCTGGAAGGCAACTTTCCAGAAGAGAACAACGACAAG
AAGAGCATCTATTACCTGGGCGTGACATCTATCAAAAAGCGGGAAAGCGGCGTGCTGCTGACCGACAAGTCTAGAGTGTC CTGCCCCTTCCCAGCCCCTTGTCTGTTTACAGACATCAGAGTGCTGCAGGACAGCTGTAGCCACTTCGTGGAAAACAACA
6727-109858-02 TCAACCTGGGCACCAGCAGCAAGAAAACCTTCGCCAGCTACATGCCTCAATTTCAGACCTGTAGCACTCAGACACACAAG ATCATGGAAAACAAGATGTGCGACCTGACCGTGTGATAA IFNGR1-TSLPRtm (SEQ ID NO: 80) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCTTTATCCTGATTAGCAGCCTGGCTATCCTGCTGATGGTGTCCCTCCTGCTGCTTTCTCTGTGGAA
GCTGTGGCGGGTGAAGAAATTCCTGATCCCCAGCGTGCCAGATCCTAAGTCCATCTTCCCCGGCCTGTTCGAGATCCACC AGGGCAATTTCCAGGAGTGGATCACCGACACCCAGAACGTGGCCCACCTGCACAAAATGGCCGGCGCCGAGCAGGAGAGC GGCCCTGAGGAACCTCTGGTGGTCCAGCTGGCCAAGACCGAGGCTGAAAGCCCTAGAATGCTGGACCCCCAGACAGAAGA GAAGGAAGCCAGCGGCGGATCTCTGCAGCTGCCTCATCAGCCTCTGCAAGGCGGAGATGTGGTGACAATCGGCGGCTTCA CCTTTGTGATGAACGACAGAAGCTACGTGGCCCTGTGATAA IFNGR1-CSF2RBtm (SEQ ID NO: 81) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCGTGCTGGCCCTGATCGTGATCTTCTTGACCATCGCTGTGCTGCTGGCCCTGCGCTTCTGCGGCAT CTACGGCTATAGACTGCGGAGAAAGTGGGAGGAAAAGATCCCCAATCCCAGCAAGAGCCACCTGTTTCAGAACGGCTCTG CCGAGCTGTGGCCTCCTGGCTCTATGAGCGCCTTTACAAGCGGCAGCCCTCCACATCAGGGACCTTGGGGCTCCAGATTC CCTGAGCTGGAAGGCGTGTTCCCCGTCGGCTTCGGCGACTCCGAGGTGTCCCCTCTGACAATTGAGGATCCGAAGCACGT GTGCGACCCTCCAAGCGGCCCTGATACCACCCCTGCTGCCAGCGACCTGCCTACCGAGCAGCCCCCCAGCCCACAACCTG GCCCTCCTGCCGCTTCTCACACCCCTGAGAAGCAGGCCTCCTCATTCGACTTCAACGGCCCTTACCTGGGCCCTCCTCAC AGCAGGAGCCTCCCTGATATCCTGGGCCAGCCTGAGCCTCCTCAGGAGGGCGGAAGCCAGAAGAGCCCCCCTCCAGGCAG CCTGGAGTACCTGTGCCTGCCTGCCGGAGGACAGGTGCAGCTGGTGCCCCTGGCCCAGGCTATGGGCCCTGGACAGGCCG TGGAAGTGGAAAGACGGCCTTCTCAGGGCGCCGCCGGCAGCCCCAGCCTGGAAAGCGGCGGCGGACCTGCCCCTCCTGCT
CTGGGCCCCAGAGTGGGCGGCCAAGATCAGAAAGACAGCCCTGTGGCCATCCCTATGAGCAGCGGCGACACCGAGGACCC CGGAGTGGCCTCTGGATACGTGTCTTCTGCCGACCTGGTGTTCACCCCTAATAGCGGCGCCAGCAGCGTGTCCCTGGTGC CTAGCCTCGGTCTCCCTTCCGACCAAACACCTTCTCTGTGTCCTGGCCTGGCTAGTGGCCCTCCTGGAGCCCCCGGCCCC GTGAAAAGCGGTTTTGAGGGCTACGTGGAACTGCCACCCATCGAAGGCAGATCTCCTAGAAGCCCGCGGAACAACCCAGT GCCCCCAGAGGCCAAGAGCCCTGTGCTGAACCCTGGAGAGAGACCTGCTGATGTGTCCCCCACAAGCCCACAGCCTGAAG GTCTGCTGGTCCTGCAGCAAGTTGGCGACTACTGCTTCCTGCCTGGCCTGGGCCCTGGCCCCCTGAGCCTGCGGAGCAAG CCCTCTAGCCCTGGCCCCGGCCCTGAAATCAAGAACCTGGACCAGGCCTTCCAGGTCAAGAAACCTCCCGGACAGGCAGT GCCACAGGTGCCTGTCATCCAGCTGTTCAAGGCCCTGAAGCAGCAGGACTACCTGAGCCTGCCTCCTTGGGAGGTGAACA AGCCCGGCGAGGTGTGTTGATAA IFNGR1-IL3Ratm (SEQ ID NO: 82) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC
AGCTCTATCAAGGGCACCAGCCTGCTGATCGCCCTGGGCACCCTCCTGGCCCTGGTCTGCGTGTTCGTGATCTGCAGACG GTACCTGGTGATGCAGAGACTGTTCCCTAGAATCCCCCACATGAAAGACCCTATCGGAGATTCTTTTCAGAACGACAAGC TGGTTGTGTGGGAGGCTGGCAAGGCCGGCCTGGAAGAATGTCTGGTGACCGAGGTGCAAGTGGTGCAGAAGACATGATAA
6727-109858-02 IFNGR1-IL2Rbtm (SEQ ID NO: 83) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCATTCCTTGGCTGGGTCACCTGCTGGTGGGCCTGTCCGGCGCCTTCGGCTTCATCATCCTGGTCTA CCTGCTGATCAACTGCAGAAACACCGGCCCTTGGCTGAAAAAGGTGCTGAAGTGCAACACCCCTGATCCTAGCAAGTTCT TCAGCCAGCTGAGCAGCGAGCACGGCGGCGACGTGCAGAAGTGGCTGAGCAGCCCGTTCCCCAGCTCTTCTTTTTCTCCT
GGCGGACTGGCCCCTGAGATCAGCCCCCTGGAAGTGCTGGAACGGGACAAAGTGACCCAACTGCTGCTGCAGCAGGATAA GGTGCCCGAGCCTGCCAGCCTCAGCAGCAATCACAGCCTGACATCATGCTTCACCAACCAGGGCTACTTCTTTTTTCACC TGCCCGACGCCCTGGAAATCGAGGCTTGTCAGGTGTATTTCACCTACGACCCCTACAGCGAGGAAGATCCCGACGAGGGC GTTGCCGGCGCCCCTACCGGCAGCAGCCCCCAGCCCCTGCAACCACTGTCCGGCGAGGACGACGCCTACTGCACCTTCCC TAGCAGAGATGATCTGCTGCTCTTCAGCCCCTCCCTGCTGGGCGGCCCCTCTCCTCCCAGCACCGCCCCTGGAGGAAGCG
GCGCTGGAGAGGAAAGAATGCCTCCTTCTCTTCAAGAGAGAGTGCCAAGAGACTGGGACCCCCAGCCTCTGGGCCCTCCA ACACCCGGCGTGCCTGACCTGGTCGACTTCCAGCCTCCTCCAGAACTGGTGCTGAGGGAAGCCGGCGAAGAGGTGCCAGA CGCCGGACCTAGAGAGGGCGTGTCCTTTCCTTGGAGCCGGCCTCCTGGCCAGGGCGAGTTCCGGGCCCTAAACGCCAGAC TGCCTCTGAATACAGATGCTTACCTGTCTCTGCAGGAGCTGCAGGGACAGGACCCTACACATCTGTGATAA IFNGR1-IL7Ratm (SEQ ID NO: 84) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCCCCATTCTGCTGACCATCAGCATCCTGAGCTTTTTCAGCGTGGCTCTGCTGGTGATCCTGGCTTG TGTGCTGTGGAAGAAGCGGATCAAGCCCATCGTGTGGCCTAGCCTCCCCGACCACAAGAAGACACTGGAACATCTGTGCA AGAAACCTAGAAAGAACCTGAACGTGTCCTTCAACCCCGAGTCCTTTCTGGACTGCCAGATCCACAGAGTGGACGACATC CAGGCCAGAGACGAGGTGGAAGGCTTCCTGCAGGACACCTTCCCACAGCAGCTGGAGGAATCCGAGAAGCAGCGGCTGGG CGGCGACGTGCAGAGCCCTAATTGCCCTTCTGAAGATGTCGTTATCACCCCTGAGAGCTTCGGCAGAGATAGCAGCCTGA
CATGCCTGGCCGGCAACGTGTCTGCCTGTGACGCCCCTATCCTGAGCTCCTCTAGAAGCCTGGATTGCCGGGAATCTGGA AAAAACGGCCCCCACGTGTACCAAGATCTGCTGCTGTCTCTGGGAACCACCAACAGCACCCTGCCTCCTCCATTCAGCCT GCAAAGCGGCATCCTGACACTGAATCCTGTGGCCCAGGGCCAGCCTATCCTTACAAGCCTGGGCAGCAACCAGGAGGAGG CCTACGTGACCATGAGCAGCTTCTACCAGAACCAGTGATAA IFNGR1-IL9Rtm (SEQ ID NO: 85) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCGGAAACACCCTGGTGGCCGTGTCCATCTTTCTGCTGCTGACCGGCCCCACCTACCTGCTGTTCAA GCTGTCTCCAAGAGTGAAGCGGATCTTCTACCAGAACGTGCCTAGCCCCGCCATGTTCTTCCAACCTCTGTACTCTGTGC ACAACGGCAACTTCCAGACATGGATGGGCGCCCACGGCGCTGGCGTGCTGCTGAGCCAGGACTGCGCCGGCACCCCTCAG GGCGCCCTTGAACCCTGTGTGCAGGAGGCTACCGCCCTGCTGACATGCGGCCCTGCAAGACCCTGGAAAAGCGTGGCCCT GGAAGAAGAGCAGGAAGGCCCTGGCACAAGACTGCCCGGTAACCTGAGCTCCGAGGACGTGCTGCCAGCTGGATGTACCG
AGTGGCGGGTCCAGACCCTGGCCTATCTGCCACAAGAAGATTGGGCCCCTACCAGCCTGACAAGGCCTGCTCCTCCTGAT AGCGAGGGCAGCAGAAGCTCCAGCAGCTCTTCTTCTAGCAACAACAACAATTACTGCGCCCTGGGCTGCTACGGCGGATG GCATCTGTCCGCCCTGCCTGGCAATACCCAGAGCAGCGGCCCTATCCCCGCCCTGGCCTGTGGCCTGAGCTGCGACCACC
6727-109858-02 AGGGCCTCGAGACACAGCAGGGAGTGGCCTGGGTTCTGGCCGGCCACTGCCAGCGGCCTGGACTGCACGAGGACCTGCAG GGCATGCTGCTCCCTAGCGTGCTGAGCAAGGCCAGAAGCTGGACCTTT IFNGR1-INSRtm (SEQ ID NO: 86) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCATCATTATCGGCCCTCTGATCTTCGTGTTCCTGTTTAGCGTGGTGATCGGCTCTATCTACCTGTT
TCTTAGGAAGCGGCAGCCCGACGGCCCACTGGGCCCTCTGTACGCCAGCAGCAACCCCGAGTACCTGAGCGCATCTGATG TGTTTCCTTGTAGCGTATACGTGCCTGATGAGTGGGAGGTGTCTCGGGAGAAGATCACCCTGCTGAGAGAGCTGGGACAA GGCAGCTTCGGCATGGTTTACGAGGGCAACGCCAGAGACATCATCAAGGGCGAGGCCGAGACAAGAGTGGCTGTGAAGAC CGTGAACGAGAGCGCCAGCCTGCGGGAACGGATCGAGTTCCTGAACGAGGCCAGCGTGATGAAGGGCTTCACCTGTCACC ACGTGGTGCGCCTGCTGGGCGTGGTCTCCAAGGGCCAACCTACCCTGGTCGTCATGGAACTGATGGCCCACGGCGACCTG
AAAAGCTATCTGAGATCTCTGCGGCCTGAAGCTGAGAACAACCCAGGCAGACCCCCACCTACACTGCAGGAGATGATTCA GATGGCCGCCGAGATCGCCGACGGCATGGCCTACCTGAATGCCAAGAAGTTCGTTCACAGAGACCTGGCCGCTAGAAACT GCATGGTGGCCCATGATTTCACAGTGAAAATCGGCGATTTCGGCATGACCAGAGATATCTACGAGACAGACTACTACCGG AAGGGCGGCAAGGGACTGCTCCCTGTGCGGTGGATGGCTCCTGAGAGCCTGAAGGACGGCGTGTTCACCACAAGCTCCGA CATGTGGAGCTTTGGAGTGGTGCTCTGGGAAATCACTTCTCTGGCCGAACAGCCCTATCAGGGCCTGAGCAATGAACAGG TGCTGAAGTTCGTGATGGACGGCGGGTACCTGGACCAGCCTGACAATTGCCCGGAGAGAGTGACCGACCTGATGCGGATG TGCTGGCAGTTCAACCCTAAGATGAGACCCACCTTCCTGGAAATCGTGAATCTGCTGAAAGACGACCTGCACCCTAGCTT CCCCGAGGTGTCTTTCTTCCACAGCGAGGAAAACAAGGCCCCTGAGTCCGAAGAGCTGGAAATGGAGTTCGAGGACATGG AAAACGTGCCCCTGGATAGATCCTCCCACTGCCAGAGAGAAGAGGCCGGAGGTCGGGATGGCGGCAGCTCTCTTGGATTT AAGAGAAGCTACGAGGAACACATCCCTTACACCCACATGAACGGCGGAAAAAAAAACGGAAGAATCCTGACCCTGCCTAG AAGCAACCCCAGCTGATAA IFNGR1-GP130 (SEQ ID NO: 87) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT
TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCGCTATCGTGGTGCCCGTGTGCCTGGCCTTCCTGCTGACCACCCTGCTCGGCGTGCTGTTCTGCTT CAATAAGCGGGACCTGATCAAGAAGCACATCTGGCCTAACGTGCCCGACCCCAGCAAGAGCCACATCGCCCAGTGGAGCC CTCACACCCCTCCAAGACACAACTTCAACAGCAAGGACCAGATGTACAGCGATGGAAATTTCACCGACGTGTCCGTGGTG GAAATCGAGGCCAACGACAAGAAACCTTTCCCAGAGGACCTGAAGTCTCTGGATCTGTTTAAGAAAGAGAAGATCAACAC CGAAGGACATTCTAGCGGCATCGGAGGCTCTTCCTGTATGAGCAGCAGTAGACCTAGCATCAGCAGCTCTGACGAAAACG AGAGCAGCCAAAATACAAGCAGCACAGTGCAGTACAGCACCGTGGTCCACAGCGGCTACAGACACCAGGTGCCTTCTGTG CAGGTTTTCAGCAGAAGCGAAAGCACACAGCCTCTGCTGGACAGCGAAGAACGCCCTGAGGATCTGCAGCTGGTGGACCA CGTGGACGGCGGCGACGGCATCCTGCCCAGGCAGCAATACTTCAAGCAGAACTGCAGCCAGCACGAGAGCTCCCCTGACA TCAGCCACTTCGAGAGATCTAAACAGGTGTCTTCTGTGAACGAGGAAGATTTCGTGCGGCTGAAGCAACAGATCTCAGAT CACATTTCCCAAAGCTGCGGCAGCGGCCAGATGAAAATGTTCCAGGAGGTGTCTGCCGCTGATGCCTTTGGCCCTGGCAC CGAGGGCCAGGTCGAGCGGTTTGAGACAGTGGGCATGGAAGCCGCCACAGACGAGGGCATGCCCAAGTCCTACCTGCCCC AGACCGTGAGACAGGGCGGATATATGCCTCAG IFNGR1-CD28 (SEQ ID NO: 88) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG
CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT
6727-109858-02 TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCTTTTGGGTCCTGGTGGTGGTGGGCGGAGTGCTGGCCTGCTACAGCCTGCTGGTGACAGTGGCCTT CATCATCTTCTGGGTGCGGTCCAAGCGGTCTAGACTGCTGCACAGCGACTACATGAACATGACCCCTAGACGGCCCGGCC CCACCAGAAAGCACTACCAGCCTTACGCCCCTCCAAGAGATTTCGCCGCTTATAGAAGC IFNGR1-CD28_YMFM (SEQ ID NO: 89) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT
TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCTTTTGGGTCCTGGTGGTGGTGGGCGGCGTGCTGGCCTGCTACAGCCTGCTGGTGACCGTGGCCTT CATCATCTTCTGGGTGCGGTCCAAGCGGAGCAGACTGCTGCACTCTGATTACATGTTCATGACCCCTAGAAGACCCGGAC CTACAAGAAAGCACTACCAGCCCTACGCCCCTCCACGGGACTTCGCCGCTTATAGAAGC IFNGR1-4-1BB (SEQ ID NO: 90) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCATCATCTCCTTCTTCCTGGCCCTGACATCTACAGCCCTGCTCTTTCTGCTGTTTTTCCTGACCCT GAGATTCAGCGTGGTGAAGCGGGGAAGAAAGAAACTGCTGTACATCTTCAAGCAGCCTTTCATGCGGCCTGTGCAGACCA CCCAGGAGGAGGACGGCTGCAGCTGCAGATTCCCCGAGGAAGAGGAAGGCGGCTGTGAACTG IFNGR1-ICOS (SEQ ID NO: 91) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG
CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCTTCTGGCTGCCTATCGGCTGCGCCGCTTTTGTGGTGGTCTGCATCCTGGGATGTATCCTGATCTG CTGGCTGACAAAGAAAAAGTACAGCTCTAGCGTGCACGACCCCAACGGCGAGTACATGTTCATGCGGGCCGTGAACACCG CCAAGAAGTCCAGACTGACCGATGTGACCCTG IFNGR1-CD2 (SEQ ID NO: 92) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCATCTACCTGATTATCGGCATCTGCGGCGGCGGATCTCTGCTCATGGTGTTCGTGGCCCTGCTGGT
GTTCTACATCACCAAGCGGAAAAAGCAGAGAAGCAGACGGAACGACGAGGAACTGGAGACAAGAGCCCACCGCGTGGCCA CCGAGGAAAGAGGCAGAAAGCCCCACCAAATCCCCGCCAGCACCCCTCAGAACCCCGCTACAAGCCAACACCCCCCCCCT CCACCTGGACATAGGTCCCAGGCCCCTAGCCACCGGCCTCCACCTCCTGGCCACCGGGTCCAGCACCAGCCCCAGAAAAG
6727-109858-02 ACCTCCTGCTCCTTCTGGCACCCAGGTGCACCAGCAGAAGGGCCCTCCTCTGCCTAGACCCAGAGTGCAGCCTAAGCCTC CACACGGCGCCGCCGAGAACAGCCTGAGCCCCTCCAGCAAT IFNGR1-TLR1 (SEQ ID NO: 93) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCCTCCTGATCGTCACCATCGTGGCCACAATGCTGGTGCTGGCCGTGACCGTGACCAGCCTGTGCAG
CTACCTGGACCTGCCCTGGTACCTGCGGATGGTGTGCCAGTGGACCCAGACAAGAAGACGGGCTAGAAATATCCCCCTGG AAGAGCTGCAAAGAAACCTGCAGTTCCACGCCTTCATCAGCTACAGCGGCCACGATAGCTTTTGGGTTAAGAACGAGCTG CTGCCTAACCTGGAAAAGGAGGGAATGCAGATCTGCCTGCACGAGAGAAACTTCGTGCCCGGCAAGTCCATCGTGGAAAA CATCATCACATGTATCGAGAAAAGCTATAAGTCTATCTTCGTGTTGTCTCCTAATTTCGTGCAGAGCGAGTGGTGCCACT ACGAGCTGTACTTCGCCCACCACAACCTGTTCCATGAGGGCAGCAACAGCCTGATCCTGATTCTGCTGGAACCTATCCCT
CAGTACAGCATTCCATCTAGCTACCACAAGCTGAAGTCCCTGATGGCCAGAAGGACCTACCTGGAATGGCCTAAGGAAAA ATCCAAGCGGGGCCTGTTTTGGGCCAACCTGAGAGCCGCTATCAACATCAAGCTGACCGAGCAGGCCAAAAAG IFNGR1-TLR2 (SEQ ID NO: 94) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCGCCCTGGTGTCTGGCATGTGCTGCGCCCTGTTTCTGCTGATCCTGCTGACCGGCGTGCTGTGTCA CAGATTTCACGGACTGTGGTACATGAAGATGATGTGGGCCTGGCTGCAGGCCAAACGGAAACCTAGAAAGGCCCCTAGCA GAAACATCTGCTACGACGCCTTCGTGAGCTATAGCGAGAGGGACGCTTACTGGGTCGAGAATCTGATGGTGCAAGAGCTG GAGAACTTCAACCCCCCCTTCAAGCTCTGTCTGCACAAAAGAGATTTCATCCCTGGCAAGTGGATCATTGATAACATCAT CGACAGCATCGAGAAAAGCCACAAGACCGTGTTTGTGCTGAGCGAAAATTTCGTGAAGTCCGAGTGGTGCAAGTACGAGC TTGATTTCAGCCATTTCAGACTGTTCGACGAGAACAACGACGCCGCTATCCTGATCCTGCTGGAACCAATCGAAAAGAAG GCTATCCCTCAGAGATTCTGCAAGCTGAGAAAGATCATGAACACCAAGACATACCTGGAATGGCCTATGGACGAGGCCCA
GCGGGAAGGCTTCTGGGTGAACCTGCGGGCCGCCATCAAGTCT IFNGR1-TLR4 (SEQ ID NO: 95) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCACAATCATCGGAGTGTCCGTGCTGAGCGTGCTGGTGGTGTCTGTGGTGGCCGTGCTGGTCTACAA GTTCTACTTCCACCTGATGCTGCTGGCTGGCTGTATTAAGTACGGCCGCGGCGAGAACATCTACGACGCCTTCGTGATCT ATAGCAGCCAGGACGAGGATTGGGTGCGGAATGAGCTCGTGAAGAACCTGGAGGAAGGAGTGCCCCCATTTCAGCTGTGC CTGCACTACCGGGACTTCATCCCTGGCGTGGCCATCGCCGCCAACATCATTCACGAGGGCTTCCACAAAAGCCGGAAGGT GATCGTCGTGGTTTCCCAGCATTTCATCCAGAGCAGATGGTGCATCTTCGAGTACGAGATCGCTCAGACCTGGCAGTTCC TGTCTAGCAGAGCCGGAATCATCTTCATCGTGCTGCAAAAAGTGGAAAAGACCCTGCTTAGACAGCAAGTGGAACTGTAC AGACTGCTGAGCAGAAACACCTACCTGGAATGGGAAGATTCTGTGCTGGGCAGACACATCTTTTGGCGGAGACTGAGAAA GGCCCTGCTGGACGGCAAGAGCTGGAATCCTGAGGGCACAGTGGGCACCGGCTGCAACTGGCAGGAGGCCACCAGCATC
6727-109858-02 IFNGR1-TLR6 (SEQ ID NO: 96) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCCTCATTGTGACCATCGGCGCCACCATGCTGGTGCTGGCCGTGACCGTGACAAGCCTGTGTATCTA CCTGGACCTGCCTTGGTACCTGAGAATGGTGTGCCAGTGGACCCAGACCAGACGGCGGGCCAGAAATATCCCTCTGGAGG AACTGCAAAGAAATCTGCAGTTCCACGCCTTCATCAGCTACAGCGAACACGACAGCGCCTGGGTGAAGTCTGAGCTGGTG CCCTACCTTGAAAAAGAAGATATCCAGATCTGCCTGCACGAGCGGAATTTCGTGCCTGGAAAAAGCATCGTCGAGAACAT
CATCAACTGCATCGAGAAATCTTATAAGTCCATCTTCGTTCTGTCTCCTAACTTCGTGCAGAGCGAGTGGTGCCACTACG AGCTGTACTTCGCCCACCACAACCTGTTCCATGAGGGCAGCAACAACCTGATCCTGATTCTGCTGGAACCTATCCCACAG AACAGCATCCCCAACAAGTACCACAAGCTGAAGGCCCTGATGACCCAGAGAACATACCTGCAGTGGCCCAAGGAAAAGTC CAAGAGAGGCCTGTTTTGGGCCAACATCAGGGCTGCTTTTAACATGAAGCTGACACTGGTGACCGAGAACAACGACGTGA AGAGC IFNGR1-EGFR (SEQ ID NO: 97) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCATCGCAACAGGCATGGTGGGCGCTCTGCTGCTGCTACTCGTGGTGGCTCTGGGCATTGGACTGTT CATGAGACGGCGGCACATCGTGCGGAAGAGAACCCTGCGCAGACTGCTGCAGGAGAGAGAGCTCGTGGAACCTTTGACCC CATCTGGCGAGGCTCCTAATCAGGCCCTGCTGAGAATCCTGAAGGAAACCGAGTTCAAGAAGATCAAGGTTCTGGGTAGC GGCGCCTTTGGTACAGTGTATAAGGGACTGTGGATCCCTGAAGGAGAAAAGGTGAAGATCCCCGTTGCCATCAAAGAACT GAGAGAAGCCACAAGCCCTAAAGCCAACAAGGAAATTCTGGACGAAGCTTACGTGATGGCCTCCGTGGACAACCCGCACG TGTGCAGACTGCTGGGCATTTGCCTGACCTCCACCGTGCAGCTGATCACCCAGCTGATGCCTTTCGGCTGCCTGCTGGAC TACGTGAGAGAGCACAAGGACAATATCGGCAGCCAGTACCTCCTGAACTGGTGTGTGCAAATCGCTAAAGGCATGAACTA CCTGGAAGATAGACGCCTGGTGCATCGGGACCTGGCCGCCCGGAACGTGCTGGTGAAGACCCCTCAACACGTGAAGATTA CCGACTTCGGCCTGGCCAAGCTGCTGGGCGCCGAAGAAAAAGAGTACCACGCCGAGGGCGGAAAAGTGCCCATCAAGTGG
ATGGCCCTGGAGAGCATCCTGCACAGAATCTACACACACCAGAGCGACGTGTGGTCCTACGGCGTGACCGTCTGGGAGCT GATGACCTTTGGAAGCAAGCCTTACGACGGCATCCCTGCTTCTGAGATCAGCAGCATCCTGGAGAAGGGCGAGAGACTGC CACAACCCCCCATCTGCACCATCGACGTGTACATGATCATGGTCAAGTGCTGGATGATCGATGCCGATAGCAGACCTAAG TTCAGAGAACTGATCATCGAGTTCTCTAAGATGGCCAGAGATCCGCAGAGATACCTGGTGATCCAGGGCGACGAGCGGAT GCACCTGCCCAGCCCTACCGACTCCAACTTCTACCGGGCCCTGATGGATGAGGAAGACATGGACGACGTCGTCGACGCCG ACGAGTACCTTATCCCCCAACAGGGCTTCTTCAGCAGCCCTAGCACCAGCAGAACACCTCTGCTGTCTAGCCTGAGCGCC ACTAGCAACAACTCTACAGTTGCCTGTATCGACAGAAACGGCCTTCAGTCTTGTCCTATCAAGGAGGATTCTTTCCTGCA GCGGTACAGCTCCGATCCTACAGGAGCCCTGACCGAGGACTCTATCGATGACACATTTCTGCCTGTGCCTGAATACATCA ACCAGAGCGTGCCCAAGCGGCCTGCCGGCTCTGTGCAGAACCCTGTGTACCACAACCAGCCTCTGAATCCTGCTCCAAGC AGAGACCCTCATTACCAGGACCCCCACAGCACCGCCGTGGGCAACCCCGAGTATCTGAACACCGTGCAGCCCACCTGCGT GAACAGCACATTCGACAGCCCAGCTCACTGGGCCCAGAAAGGCAGCCACCAGATCAGCCTGGATAATCCTGACTACCAGC AGGATTTTTTCCCTAAGGAGGCCAAGCCCAATGGCATCTTCAAAGGATCTACCGCCGAGAACGCCGAGTATCTGAGAGTG GCCCCTCAGAGCTCCGAGTTCATCGGCGCC IFNGR1-IGF1R (SEQ ID NO: 98) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA
TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT
6727-109858-02 GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCCTCATCATCGCCCTGCCTGTGGCCGTGCTTCTGATCGTGGGCGGACTGGTGATCATGCTGTATGT GTTCCACAGAAAAAGAAACAACAGCCGGCTGGGCAACGGCGTTCTGTACGCCAGCGTGAACCCTGAGTACTTCAGCGCCG CTGATGTGTACGTGCCTGACGAGTGGGAAGTGGCCAGAGAGAAGATCACCATGTCTAGGGAGCTGGGACAGGGCAGCTTC GGCATGGTCTACGAGGGCGTGGCAAAGGGAGTGGTCAAGGACGAGCCCGAAACCCGAGTGGCTATCAAGACCGTGAACGA GGCCGCCAGCATGAGAGAAAGAATCGAGTTCCTGAACGAGGCCTCTGTGATGAAAGAGTTCAACTGCCACCACGTGGTGC GGCTGCTGGGCGTGGTGTCTCAGGGACAGCCCACCCTGGTCATCATGGAACTGATGACCAGAGGCGATCTGAAGAGCTAC CTGCGGAGCCTGAGACCAGAAATGGAAAACAATCCCGTGCTGGCCCCTCCATCTCTGAGCAAGATGATCCAAATGGCCGG CGAGATCGCCGACGGCATGGCTTACCTGAACGCCAACAAGTTCGTGCACCGGGACCTGGCTGCTAGAAATTGCATGGTGG CCGAAGATTTTACAGTGAAGATCGGCGACTTCGGTATGACACGGGACATCTACGAGACAGACTACTACCGGAAGGGCGGC AAGGGCCTGCTGCCTGTGCGGTGGATGAGCCCCGAGAGCCTGAAAGACGGCGTCTTTACCACCTACAGTGATGTGTGGTC CTTTGGAGTGGTGCTGTGGGAGATCGCTACACTGGCCGAGCAGCCTTACCAGGGCTTGTCTAATGAGCAAGTGCTGAGAT TCGTGATGGAAGGCGGACTGCTGGACAAGCCCGACAACTGTCCTGACATGCTGTTCGAGCTGATGAGAATGTGCTGGCAG TACAACCCCAAGATGCGGCCTTCTTTTCTGGAAATTATCAGCAGCATCAAGGAAGAAATGGAACCCGGCTTCAGAGAGGT
GTCCTTCTACTACAGCGAGGAAAACAAACTGCCTGAGCCTGAGGAACTGGACCTGGAACCTGAGAATATGGAAAGCGTGC CCCTGGATCCTAGCGCCTCCTCCAGCAGCCTGCCTCTGCCTGATAGACACAGCGGCCACAAGGCCGAGAACGGCCCTGGC CCAGGCGTTCTGGTGCTCAGAGCCAGCTTCGACGAGAGACAGCCTTATGCCCATATGAACGGCGGCAGAAAGAACGAGCG CGCCCTGCCTCTGCCCCAGAGCTCCACCTGC
IFNGR1-MET (SEQ ID NO: 99) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCGGCCTGATTGCTGGCGTGGTTTCCATCAGCACAGCCCTGCTGCTGCTTCTGGGCTTCTTCCTGTG GCTGAAAAAGCGGAAGCAGATTAAGGACCTGGGCTCTGAGCTGGTGCGGTACGACGCCAGGGTGCACACCCCTCACCTGG ACAGACTGGTGAGCGCCAGAAGCGTGTCCCCCACCACCGAGATGGTGTCGAACGAGTCCGTCGACTACAGAGCCACATTT CCAGAAGATCAGTTCCCCAACAGCAGCCAGAACGGCTCATGCCGGCAGGTTCAGTACCCCCTGACAGATATGAGCCCTAT CCTGACAAGCGGCGATTCTGATATCAGCAGCCCTCTGCTGCAAAACACCGTGCATATCGACCTGAGCGCCCTTAACCCTG AACTGGTGCAGGCCGTGCAACACGTGGTGATCGGACCTAGCTCTCTGATCGTGCACTTTAACGAGGTGATCGGCAGAGGC CACTTTGGATGTGTGTACCACGGCACCCTGCTCGACAACGACGGCAAGAAAATCCACTGCGCCGTGAAGTCTCTGAACAG AATTACCGACATCGGAGAAGTGTCCCAGTTTCTGACCGAGGGAATCATCATGAAAGACTTCAGCCACCCTAATGTGCTGA GCCTGTTGGGCATCTGCCTGCGGAGCGAAGGCAGCCCTTTGGTGGTCCTGCCCTACATGAAGCACGGCGACCTGAGAAAT TTCATCAGAAATGAAACACACAATCCTACCGTCAAGGATCTGATCGGATTCGGTCTGCAGGTGGCCAAGGGCATGAAATA
CCTGGCCAGCAAGAAGTTCGTGCACAGAGACCTGGCCGCCAGAAACTGCATGCTGGACGAGAAGTTCACCGTGAAGGTGG CAGATTTCGGCCTGGCTAGAGATATGTACGACAAGGAATACTACAGCGTGCACAACAAGACCGGCGCCAAGCTGCCTGTG AAGTGGATGGCCCTGGAAAGCCTGCAGACCCAGAAGTTCACAACCAAGAGCGACGTGTGGAGCTTCGGCGTGCTGCTGTG GGAACTCATGACCCGGGGCGCTCCACCTTATCCTGATGTGAACACATTCGACATCACAGTGTATCTGCTGCAGGGCAGAC GGCTGCTGCAGCCTGAGTACTGCCCCGACCCTCTGTACGAGGTGATGCTGAAGTGTTGGCACCCCAAGGCCGAGATGCGC CCCAGCTTCAGCGAGCTGGTGAGTAGAATCTCTGCCATCTTCTCCACCTTCATCGGCGAGCACTACGTCCATGTGAACGC TACCTACGTGAACGTGAAATGCGTGGCCCCTTACCCATCCCTGCTGTCTAGCGAGGACAACGCCGATGACGAGGTTGACA CCAGACCTGCTTCTTTCTGGGAAACGAGC IFNGR1-ROS1 (SEQ ID NO: 100) ATGGCGCTGCTGTTCCTCCTTCCTCTGGTGATGCAGGGCGTTAGCAGAGCCGAAATGGGAACAGCCGACCTCGGACCTAG CAGCGTTCCAACACCTACAAACGTGACCATCGAGAGCTACAACATGAACCCCATCGTGTACTGGGAGTACCAAATCATGC CTCAGGTGCCCGTGTTCACCGTGGAAGTCAAGAATTATGGCGTGAAGAACAGCGAGTGGATCGACGCTTGTATCAACATC AGCCACCACTACTGCAACATCAGCGATCACGTGGGAGATCCCAGCAACAGCCTGTGGGTGCGGGTGAAGGCTAGAGTGGG CCAAAAGGAGTCTGCCTACGCCAAGAGCGAAGAGTTCGCCGTGTGCAGAGATGGCAAGATCGGGCCTCCAAAGCTGGACA TCAGAAAGGAAGAGAAGCAGATCATGATCGACATCTTTCACCCTAGCGTGTTCGTGAACGGCGATGAGCAGGAGGTTGAC TACGACCCTGAAACCACATGCTACATCCGGGTGTACAATGTGTACGTGCGGATGAACGGCTCTGAGATTCAGTACAAGAT TCTGACACAGAAAGAAGATGACTGCGACGAGATCCAGTGCCAGCTGGCCATCCCCGTCTCTAGCCTGAATAGCCAGTACT GCGTGTCTGCTGAGGGCGTGCTGCATGTGTGGGGCGTGACCACCGAGAAATCTAAGGAAGTGTGTATCACAATCTTCAAC AGCTCTATCAAGGGCACTAGCTTTATCCTGACAATCATCGTGGGCATCTTCCTGGTCGTGACCATCCCCCTCACATTCGT
GTGGCACCGCAGACTGAAGAACCAGAAAAGCGCCAAGGAGGGCGTGACAGTGCTGATCAACGAAGACAAGGAACTGGCCG AGCTGAGAGGCCTGGCCGCCGGCGTCGGCCTGGCCAACGCCTGCTACGCCATCCACACCCTGCCTACACAAGAGGAGATC GAAAACCTGCCTGCTTTTCCCCGGGAAAAACTGACCCTGCGGCTGCTCCTAGGCAGCGGCGCCTTCGGGGAGGTGTACGA
6727-109858-02 GGGCACCGCCGTGGACATCCTTGGAGTGGGCTCTGGCGAGATCAAGGTGGCTGTGAAGACCCTGAAGAAGGGCAGCACCG ACCAAGAGAAGATCGAGTTCCTGAAGGAAGCCCATCTGATGAGCAAGTTCAACCACCCTAACATCCTGAAACAGCTGGGC GTTTGTCTGCTGAATGAGCCCCAGTACATCATCCTGGAACTGATGGAAGGCGGAGATCTGCTGACCTACCTGAGAAAGGC CAGAATGGCCACATTCTACGGTCCTCTGCTGACACTGGTGGATCTGGTGGACTTGTGCGTGGACATTTCTAAGGGCTGTG TGTATCTGGAAAGAATGCACTTCATCCACCGGGACCTGGCTGCTCGGAATTGCCTGGTGTCCGTGAAAGACTACACCAGC CCTAGAATTGTTAAGATCGGCGATTTCGGCCTGGCTAGAGATATCTACAAGAACGACTACTATAGAAAGCGGGGCGAGGG ACTGCTGCCAGTGCGGTGGATGGCCCCTGAATCCCTGATGGACGGCATCTTCACCACACAGAGCGACGTGTGGTCTTTTG GCATCCTCATCTGGGAAATCCTGACCCTTGGCCACCAGCCTTACCCCGCCCACAGCAACCTGGACGTGCTGAATTACGTG CAGACCGGCGGCAGACTGGAACCACCTAGAAACTGCCCTGATGACCTGTGGAACCTGATGACCCAATGTTGGGCCCAGGA GCCCGATCAGAGACCTACCTTCCACAGAATCCAGGACCAGCTGCAGCTGTTCAGAAACTTCTTCCTGAATAGCATCTACA AGTCCCGGGACGAGGCAAACAACAGCGGAGTCATCAACGAGAGCTTTGAGGGAGAAGATGGAGATGTGATCTGCCTGAAC AGCGACGACATTATGCCTGTGGCCCTGATGGAGACAAAGAATAGAGAAGGACTGAACTACATGGTGCTGGCCACCGAGTG CGGCCAGGGCGAAGAGAAGAGCGAGGGCCCTCTGGGCAGCCAGGAGTCCGAGAGCTGCGGCCTGAGGAAGGAAGAAAAGG AACCCCACGCCGATAAGGACTTCTGCCAGGAGAAACAGGTGGCCTACTGCCCCAGCGGCAAGCCTGAGGGCCTGAACTAC
GCCTGTCTGACACACTCTGGATACGGCGACGGATCTGAC Provided below are exemplary codon-optimized nucleic acid sequences encoding chimeric IFNGR1-IFNGR2 polypeptides that include, in the N-terminal to C-terminal direction, a first extracellular domain from IFNGR1, a first transmembrane domain (from IFNGR1 or another cytokine receptor), a first intracellular signaling domain from a heterologous cytokine receptor (or a modified IFNGR1 signaling domain), a 2A peptide sequence, a second extracellular domain from IFNGR2, a second transmembrane domain (from IFNGR2 or another cytokine receptor), and a second intracellular signaling domain from a heterologous cytokine receptor (or from IFNGR2). Although nucleic acid molecules encoding both chimeric IFNGR1 and chimeric IFNGR2 polypeptides are exemplified below, the chimeric IFNGR1 polypeptide and the chimeric IFNGR2 polypeptide can be encoded by separate nucleic acid molecules. IFNGR1-2-EPORtm (SEQ ID NO: 101) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC
CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT
CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCCTGATCCTGACCCTGTCCCTGATCCTGGTTGTGATCCTGGTCCTGCTGACAGTGCTGGCCCTGCT GAGCCACCGGAGAGCCCTGAAACAGAAGATCTGGCCTGGCATCCCTTCTCCTGAGAGCGAGTTCGAGGGACTGTTTACCA CCCACAAGGGCAATTTCCAGCTGTGGCTTTATCAGAACGACGGCTGCCTGTGGTGGAGCCCCTGCACCCCGTTCACAGAG GATCCCCCCGCTAGCCTGGAAGTGCTGTCTGAACGGTGCTGGGGAACAATGCAGGCCGTGGAACCTGGTACAGACGACGA GGGCCCCCTGCTCGAACCCGTGGGCAGCGAGCACGCCCAGGACACCTACCTGGTGCTGGACAAGTGGCTGCTGCCTAGAA ACCCCCCCAGCGAGGACCTGCCTGGCCCTGGAGGCAGCGTGGACATCGTGGCTATGGACGAGGGCTCTGAGGCCTCTTCT TGTAGCAGCGCCCTGGCCTCAAAGCCTAGCCCTGAGGGCGCCTCTGCCGCCTCCTTCGAGTACACCATCCTGGATCCTAG CAGCCAGCTGCTGAGACCTTGGACCCTGTGCCCCGAACTGCCACCTACCCCTCCCCATCTGAAGTACCTGTACCTGGTGG TGTCCGATAGCGGCATCAGCACCGATTACAGCTCCGGCGACAGCCAAGGCGCTCAGGGCGGCCTGTCTGATGGACCATAC AGCAACCCTTACGAGAACAGCCTCATTCCTGCCGCTGAACCACTGCCTCCAAGCTACGTGGCCTGTAGCAGAGCCAAGAG GAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCA CACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTG CCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTC CACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCG TGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAAC GTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAA CGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCG ACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGA
CCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCT
6727-109858-02 CTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAG AGCTGCAACAGCTGATCCTGACCCTGTCCCTGATCCTGGTTGTGATCCTGGTCCTGCTGACAGTGCTGGCCCTGCTGAGC CACCGGAGAGCCCTGAAACAGAAGATCTGGCCTGGCATCCCTTCTCCTGAGAGCGAGTTCGAGGGACTGTTTACCACCCA CAAGGGCAATTTCCAGCTGTGGCTTTATCAGAACGACGGCTGCCTGTGGTGGAGCCCCTGCACCCCGTTCACAGAGGATC CCCCCGCTAGCCTGGAAGTGCTGTCTGAACGGTGCTGGGGAACAATGCAGGCCGTGGAACCTGGTACAGACGACGAGGGC CCCCTGCTCGAACCCGTGGGCAGCGAGCACGCCCAGGACACCTACCTGGTGCTGGACAAGTGGCTGCTGCCTAGAAACCC CCCCAGCGAGGACCTGCCTGGCCCTGGAGGCAGCGTGGACATCGTGGCTATGGACGAGGGCTCTGAGGCCTCTTCTTGTA GCAGCGCCCTGGCCTCAAAGCCTAGCCCTGAGGGCGCCTCTGCCGCCTCCTTCGAGTACACCATCCTGGATCCTAGCAGC CAGCTGCTGAGACCTTGGACCCTGTGCCCCGAACTGCCACCTACCCCTCCCCATCTGAAGTACCTGTACCTGGTGGTGTC CGATAGCGGCATCAGCACCGATTACAGCTCCGGCGACAGCCAAGGCGCTCAGGGCGGCCTGTCTGATGGACCATACAGCA ACCCTTACGAGAACAGCCTCATTCCTGCCGCTGAACCACTGCCTCCAAGCTACGTGGCCTGTAGCTGATAA IFNGR1-2-EPORtrtm (SEQ ID NO: 102) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC
TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC
TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCCTGATTCTGACCCTGTCTCTGATCCTGGTCGTGATCCTGGTTCTGCTTACAGTGCTGGCTCTGCT GAGCCACAGACGGGCCCTGAAGCAGAAAATCTGGCCTGGCATCCCCAGCCCCGAGAGCGAGTTCGAGGGCCTGTTCACCA CCCACAAGGGCAATTTCCAACTGTGGCTGTACCAGAACGACGGCTGTCTGTGGTGGTCCCCGTGCACCCCTTTCACAGAG GACCCTCCAGCTAGCCTGGAAGTGCTGAGCGAACGGTGCTGGGGCACAATGCAGGCCGTGGAACCTGGAACAGACGATGA GGGCCCTCTGCTCGAGCCTGTGGGCAGCGAGCACGCCCAGGACACCTACCTGGTGCTGGACAAGTGGCTGCTGCCTAGAA ACCCCCCCAGCGAAGATCTGCCCGGACCTGGCGGCAGCGTGGACATCGTGGCTATGGACGAGGGATCTGAAGCCAGCAGC TGCAGCAGCGCCCTGGCCAGCAAGCCTTCTCCAGAAGGCGCCTCCGCCGCTTCTTTTGAGTACACCATCCTGGATCCTAG CTCCCAGCTGCTGAGACCTAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATG TGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCA GCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCT CAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGT GGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGC CCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGT GACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCT CTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGG GAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGT GTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCT
GCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGCTGATTCTGACCCTGTCTCTGATCCTGGTCGTGATCCTG GTTCTGCTTACAGTGCTGGCTCTGCTGAGCCACAGACGGGCCCTGAAGCAGAAAATCTGGCCTGGCATCCCCAGCCCCGA GAGCGAGTTCGAGGGCCTGTTCACCACCCACAAGGGCAATTTCCAACTGTGGCTGTACCAGAACGACGGCTGTCTGTGGT GGTCCCCGTGCACCCCTTTCACAGAGGACCCTCCAGCTAGCCTGGAAGTGCTGAGCGAACGGTGCTGGGGCACAATGCAG GCCGTGGAACCTGGAACAGACGATGAGGGCCCTCTGCTCGAGCCTGTGGGCAGCGAGCACGCCCAGGACACCTACCTGGT GCTGGACAAGTGGCTGCTGCCTAGAAACCCCCCCAGCGAAGATCTGCCCGGACCTGGCGGCAGCGTGGACATCGTGGCTA TGGACGAGGGATCTGAAGCCAGCAGCTGCAGCAGCGCCCTGGCCAGCAAGCCTTCTCCAGAAGGCGCCTCCGCCGCTTCT TTTGAGTACACCATCCTGGATCCTAGCTCCCAGCTGCTGAGACCTTGATAA IFNGR1-2-GHRtm (SEQ ID NO: 103) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCTTTCCTTGGCTGCTGATCATCATCTTTGGCATCTTCGGCCTGACAGTGATGCTGTTCGTGTTCCT
GTTCAGCAAGCAGCAGAGAATCAAGATGCTGATCCTGCCACCTGTTCCTGTGCCCAAGATCAAGGGAATCGATCCTGATC TGCTGAAGGAAGGCAAGCTGGAAGAAGTGAACACCATCCTGGCCATCCACGATAGCTATAAGCCCGAGTTTCACAGCGAC GACAGCTGGGTGGAGTTCATCGAGCTGGATATCGACGAGCCTGATGAGAAGACCGAGGAATCTGACACCGACCGGCTGCT
6727-109858-02 GAGCAGCGACCACGAGAAAAGCCACTCCAACCTGGGCGTGAAGGACGGCGACAGCGGCCGGACCTCTTGTTGTGAACCCG ATATTCTCGAGACAGACTTCAACGCCAACGACATCCATGAGGGCACCAGCGAGGTGGCTCAGCCCCAAAGACTCAAAGGA GAAGCCGATCTGCTGTGCCTGGACCAGAAGAACCAGAACAACAGCCCCTACCACGACGCCTGCCCCGCCACCCAGCAACC TTCCGTGATCCAGGCTGAAAAAAACAAGCCTCAGCCTCTGCCCACCGAGGGCGCCGAGAGCACCCACCAGGCCGCCCACA TCCAACTGAGCAATCCTAGCAGCCTGTCTAATATCGACTTCTACGCCCAGGTGTCCGACATTACACCTGCCGGCAGCGTG GTGCTGTCCCCGGGACAGAAAAACAAGGCCGGCATGAGCCAGTGCGACATGCACCCTGAGATGGTCTCCCTATGTCAGGA GAACTTCCTGATGGACAACGCTTACTTCTGCGAGGCCGACGCCAAGAAGTGCATCCCCGTGGCCCCTCACATCAAGGTGG AAAGCCACATCCAGCCAAGCCTGAATCAGGAGGACATCTACATCACCACAGAGTCTCTGACCACCGCTGCTGGCAGACCT GGAACAGGCGAGCACGTGCCAGGCTCTGAGATGCCTGTCCCTGACTACACCAGCATCCATATTGTGCAGAGCCCTCAGGG CCTGATCCTGAATGCCACAGCCCTGCCTCTGCCTGATAAGGAGTTCCTGTCTAGCTGCGGCTACGTGTCTACAGATCAGC TGAACAAAATCATGCCCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTG GAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGC TGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCA GCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGG
TTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCC TAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGA CAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCT CTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGA GAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGT
ACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGC TACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGTTTCCTTGGCTGCTGATCATCATCTTTGGCATCTTCGGCCT GACAGTGATGCTGTTCGTGTTCCTGTTCAGCAAGCAGCAGAGAATCAAGATGCTGATCCTGCCACCTGTTCCTGTGCCCA AGATCAAGGGAATCGATCCTGATCTGCTGAAGGAAGGCAAGCTGGAAGAAGTGAACACCATCCTGGCCATCCACGATAGC TATAAGCCCGAGTTTCACAGCGACGACAGCTGGGTGGAGTTCATCGAGCTGGATATCGACGAGCCTGATGAGAAGACCGA GGAATCTGACACCGACCGGCTGCTGAGCAGCGACCACGAGAAAAGCCACTCCAACCTGGGCGTGAAGGACGGCGACAGCG GCCGGACCTCTTGTTGTGAACCCGATATTCTCGAGACAGACTTCAACGCCAACGACATCCATGAGGGCACCAGCGAGGTG GCTCAGCCCCAAAGACTCAAAGGAGAAGCCGATCTGCTGTGCCTGGACCAGAAGAACCAGAACAACAGCCCCTACCACGA CGCCTGCCCCGCCACCCAGCAACCTTCCGTGATCCAGGCTGAAAAAAACAAGCCTCAGCCTCTGCCCACCGAGGGCGCCG AGAGCACCCACCAGGCCGCCCACATCCAACTGAGCAATCCTAGCAGCCTGTCTAATATCGACTTCTACGCCCAGGTGTCC GACATTACACCTGCCGGCAGCGTGGTGCTGTCCCCGGGACAGAAAAACAAGGCCGGCATGAGCCAGTGCGACATGCACCC TGAGATGGTCTCCCTATGTCAGGAGAACTTCCTGATGGACAACGCTTACTTCTGCGAGGCCGACGCCAAGAAGTGCATCC CCGTGGCCCCTCACATCAAGGTGGAAAGCCACATCCAGCCAAGCCTGAATCAGGAGGACATCTACATCACCACAGAGTCT CTGACCACCGCTGCTGGCAGACCTGGAACAGGCGAGCACGTGCCAGGCTCTGAGATGCCTGTCCCTGACTACACCAGCAT CCATATTGTGCAGAGCCCTCAGGGCCTGATCCTGAATGCCACAGCCCTGCCTCTGCCTGATAAGGAGTTCCTGTCTAGCT GCGGCTACGTGTCTACAGATCAGCTGAACAAAATCATGCCCTGATAA IFNGR1-2-TPORtm (SEQ ID NO: 104) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC
CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCATCAGCCTGGTGACCGCCCTGCACCTGGTCCTGGGACTGTCCGCCGTGCTGGGCCTGCTGCTGCT GAGATGGCAGTTCCCCGCTCACTACCGGAGACTGCGGCACGCCCTGTGGCCTAGCCTGCCCGACCTGCATAGAGTGCTGG GCCAGTACCTGAGAGATACAGCCGCTCTGTCTCCTCCTAAGGCCACAGTGTCCGACACCTGCGAGGAAGTGGAACCTTCT CTGCTCGAGATCCTGCCCAAGTCCAGCGAGCGGACACCTCTGCCTCTTTGTAGCAGCCAGGCCCAGATGGACTACAGAAG GCTGCAGCCTAGCTGTCTGGGCACCATGCCTCTGAGCGTGTGCCCTCCAATGGCCGAGAGCGGCAGCTGCTGCACCACCC ACATCGCCAACCACAGCTACCTGCCACTGTCTTATTGGCAACAGCCCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAAT TTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCT ACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGA TCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAA GTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGC CACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCG AACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAG AACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGC
CTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTA GCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTC CGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGATCAGCCTGGT
6727-109858-02 GACCGCCCTGCACCTGGTCCTGGGACTGTCCGCCGTGCTGGGCCTGCTGCTGCTGAGATGGCAGTTCCCCGCTCACTACC GGAGACTGCGGCACGCCCTGTGGCCTAGCCTGCCCGACCTGCATAGAGTGCTGGGCCAGTACCTGAGAGATACAGCCGCT CTGTCTCCTCCTAAGGCCACAGTGTCCGACACCTGCGAGGAAGTGGAACCTTCTCTGCTCGAGATCCTGCCCAAGTCCAG CGAGCGGACACCTCTGCCTCTTTGTAGCAGCCAGGCCCAGATGGACTACAGAAGGCTGCAGCCTAGCTGTCTGGGCACCA TGCCTCTGAGCGTGTGCCCTCCAATGGCCGAGAGCGGCAGCTGCTGCACCACCCACATCGCCAACCACAGCTACCTGCCA CTGTCTTATTGGCAACAGCCCTGATAA IFNGR1-2-PRLRtm (SEQ ID NO: 105) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC
TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCACAACCGTGTGGATCAGCGTTGCTGTGCTGTCTGCTGTGATCTGCCTGATCATCGTGTGGGCCGT GGCCCTGAAGGGATATAGCATGGTGACCTGTATCTTCCCCCCCGTGCCCGGCCCCAAGATTAAGGGCTTCGACGCCCACC
TGCTTGAGAAGGGAAAATCTGAGGAACTGCTGAGCGCCCTGGGCTGCCAGGATTTCCCTCCAACCAGTGATTACGAGGAC CTGCTGGTGGAGTACCTGGAAGTGGACGACTCCGAAGATCAGCATCTGATGAGCGTGCACAGCAAGGAACACCCCTCCCA GGGCATGAAGCCTACATACCTGGATCCTGATACCGATTCTGGCAGAGGCAGCTGCGACAGCCCCAGCCTGCTGAGCGAGA AGTGTGAAGAGCCTCAAGCTAATCCTAGCACCTTCTACGACCCTGAGGTGATCGAGAAACCTGAGAATCCTGAAACCACA CACACCTGGGACCCTCAGTGCATCAGCATGGAGGGCAAAATCCCCTACTTCCATGCCGGCGGCTCTAAGTGCAGCACATG GCCTCTGCCTCAACCTAGCCAGCACAACCCCAGATCTAGCTACCACAATATCACCGACGTGTGCGAGCTGGCCGTGGGCC CTGCTGGAGCCCCTGCCACCCTGCTCAACGAGGCCGGAAAAGATGCCCTGAAGAGCTCCCAGACCATCAAGAGCAGAGAG GAGGGCAAGGCCACACAGCAGCGGGAAGTCGAGAGCTTCCACTCTGAGACAGACCAGGACACCCCTTGGCTGCTGCCACA AGAGAAGACCCCCTTCGGCAGCGCTAAACCTCTGGACTACGTGGAAATCCACAAGGTGAACAAGGACGGCGCCCTGAGCC TGCTGCCTAAGCAGCGGGAAAACAGCGGCAAGCCGAAAAAGCCAGGCACACCTGAGAACAACAAGGAATACGCCAAGGTG TCCGGCGTGATGGACAACAACATCCTGGTCCTGGTGCCTGACCCCCACGCCAAGAACGTGGCCTGTTTTGAGGAAAGCGC CAAGGAAGCCCCTCCTAGCCTCGAGCAGAACCAGGCCGAGAAGGCCCTGGCTAACTTCACCGCCACATCTAGCAAATGCA GACTGCAGCTGGGCGGACTGGACTACCTGGACCCCGCCTGCTTCACCCACAGCTTTCACAGAGCCAAGAGGAGCGGCAGC GGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTG GTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTC AACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCA GTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCAC TCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGA GACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTG GGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGA
TACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAA GCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAG AGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACA GACAACCGTGTGGATCAGCGTTGCTGTGCTGTCTGCTGTGATCTGCCTGATCATCGTGTGGGCCGTGGCCCTGAAGGGAT ATAGCATGGTGACCTGTATCTTCCCCCCCGTGCCCGGCCCCAAGATTAAGGGCTTCGACGCCCACCTGCTTGAGAAGGGA AAATCTGAGGAACTGCTGAGCGCCCTGGGCTGCCAGGATTTCCCTCCAACCAGTGATTACGAGGACCTGCTGGTGGAGTA CCTGGAAGTGGACGACTCCGAAGATCAGCATCTGATGAGCGTGCACAGCAAGGAACACCCCTCCCAGGGCATGAAGCCTA CATACCTGGATCCTGATACCGATTCTGGCAGAGGCAGCTGCGACAGCCCCAGCCTGCTGAGCGAGAAGTGTGAAGAGCCT CAAGCTAATCCTAGCACCTTCTACGACCCTGAGGTGATCGAGAAACCTGAGAATCCTGAAACCACACACACCTGGGACCC TCAGTGCATCAGCATGGAGGGCAAAATCCCCTACTTCCATGCCGGCGGCTCTAAGTGCAGCACATGGCCTCTGCCTCAAC CTAGCCAGCACAACCCCAGATCTAGCTACCACAATATCACCGACGTGTGCGAGCTGGCCGTGGGCCCTGCTGGAGCCCCT GCCACCCTGCTCAACGAGGCCGGAAAAGATGCCCTGAAGAGCTCCCAGACCATCAAGAGCAGAGAGGAGGGCAAGGCCAC ACAGCAGCGGGAAGTCGAGAGCTTCCACTCTGAGACAGACCAGGACACCCCTTGGCTGCTGCCACAAGAGAAGACCCCCT TCGGCAGCGCTAAACCTCTGGACTACGTGGAAATCCACAAGGTGAACAAGGACGGCGCCCTGAGCCTGCTGCCTAAGCAG CGGGAAAACAGCGGCAAGCCGAAAAAGCCAGGCACACCTGAGAACAACAAGGAATACGCCAAGGTGTCCGGCGTGATGGA CAACAACATCCTGGTCCTGGTGCCTGACCCCCACGCCAAGAACGTGGCCTGTTTTGAGGAAAGCGCCAAGGAAGCCCCTC CTAGCCTCGAGCAGAACCAGGCCGAGAAGGCCCTGGCTAACTTCACCGCCACATCTAGCAAATGCAGACTGCAGCTGGGC GGACTGGACTACCTGGACCCCGCCTGCTTCACCCACAGCTTTCACTGATAA IFNGR1-2-LEPRtm (SEQ ID NO: 106)
ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC
6727-109858-02 AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCGCTGGCCTCTACGTGATCGTGCCTGTGATCATCTCTAGCAGCATTCTGCTGCTGGGAACCCTGCT TATTTCTCACCAGCGGATGAAAAAACTGTTCTGGGAAGATGTGCCCAATCCTAAGAATTGCAGCTGGGCCCAGGGCCTGA ACTTCCAAAAGCCTGAGACATTTGAGCACCTGTTCATCAAGCACACCGCCAGCGTCACATGCGGCCCTCTGCTGCTGGAA CCTGAGACAATCAGCGAGGATATCTCCGTCGACACCAGCTGGAAGAACAAGGACGAGATGATGCCCACCACCGTGGTGTC TCTGCTGTCTACAACAGATCTGGAGAAGGGCAGCGTGTGCATCAGCGATCAGTTCAACTCTGTGAACTTCAGCGAAGCCG AGGGCACCGAGGTGACCTACGAGGATGAGTCTCAGAGACAGCCTTTCGTTAAGTACGCCACACTGATCAGTAATTCTAAG CCCTCCGAAACCGGAGAGGAACAGGGCCTGATCAACTCCAGCGTGACCAAGTGCTTCAGCAGCAAGAACAGCCCCCTGAA AGACAGCTTCTCTAATAGCAGCTGGGAGATCGAGGCTCAGGCCTTCTTCATCCTGAGCGACCAGCATCCTAACATCATCT
CCCCTCACCTGACCTTCAGCGAGGGACTCGACGAGCTGCTGAAGCTGGAAGGCAACTTTCCAGAAGAGAACAACGACAAG AAGAGCATCTATTACCTGGGCGTGACATCTATCAAAAAGCGGGAAAGCGGCGTGCTGCTGACCGACAAGTCTAGAGTGTC CTGCCCCTTCCCAGCCCCTTGTCTGTTTACAGACATCAGAGTGCTGCAGGACAGCTGTAGCCACTTCGTGGAAAACAACA TCAACCTGGGCACCAGCAGCAAGAAAACCTTCGCCAGCTACATGCCTCAATTTCAGACCTGTAGCACTCAGACACACAAG ATCATGGAAAACAAGATGTGCGACCTGACCGTGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAA
GCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGT TCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAAC GCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTA TACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACT TCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTG CACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGAC CCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACT ACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTG AAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCT GAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGCTGGCCTCTACGTGATCGTGCCTG TGATCATCTCTAGCAGCATTCTGCTGCTGGGAACCCTGCTTATTTCTCACCAGCGGATGAAAAAACTGTTCTGGGAAGAT GTGCCCAATCCTAAGAATTGCAGCTGGGCCCAGGGCCTGAACTTCCAAAAGCCTGAGACATTTGAGCACCTGTTCATCAA GCACACCGCCAGCGTCACATGCGGCCCTCTGCTGCTGGAACCTGAGACAATCAGCGAGGATATCTCCGTCGACACCAGCT GGAAGAACAAGGACGAGATGATGCCCACCACCGTGGTGTCTCTGCTGTCTACAACAGATCTGGAGAAGGGCAGCGTGTGC ATCAGCGATCAGTTCAACTCTGTGAACTTCAGCGAAGCCGAGGGCACCGAGGTGACCTACGAGGATGAGTCTCAGAGACA GCCTTTCGTTAAGTACGCCACACTGATCAGTAATTCTAAGCCCTCCGAAACCGGAGAGGAACAGGGCCTGATCAACTCCA GCGTGACCAAGTGCTTCAGCAGCAAGAACAGCCCCCTGAAAGACAGCTTCTCTAATAGCAGCTGGGAGATCGAGGCTCAG GCCTTCTTCATCCTGAGCGACCAGCATCCTAACATCATCTCCCCTCACCTGACCTTCAGCGAGGGACTCGACGAGCTGCT GAAGCTGGAAGGCAACTTTCCAGAAGAGAACAACGACAAGAAGAGCATCTATTACCTGGGCGTGACATCTATCAAAAAGC GGGAAAGCGGCGTGCTGCTGACCGACAAGTCTAGAGTGTCCTGCCCCTTCCCAGCCCCTTGTCTGTTTACAGACATCAGA
GTGCTGCAGGACAGCTGTAGCCACTTCGTGGAAAACAACATCAACCTGGGCACCAGCAGCAAGAAAACCTTCGCCAGCTA CATGCCTCAATTTCAGACCTGTAGCACTCAGACACACAAGATCATGGAAAACAAGATGTGCGACCTGACCGTGTGATAA IFNGR1-IL3Ratm-IFNGR2-CSF2RBtm (SEQ ID NO: 107) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCACCAGCCTGCTGATCGCCCTGGGCACCCTCCTGGCCCTGGTCTGCGTGTTCGTGATCTGCAGACG GTACCTGGTGATGCAGAGACTGTTCCCTAGAATCCCCCACATGAAAGACCCTATCGGAGATTCTTTTCAGAACGACAAGC TGGTTGTGTGGGAGGCTGGCAAGGCCGGCCTGGAAGAATGTCTGGTGACCGAGGTGCAAGTGGTGCAGAAGACAAGAGCC AAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAG GCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCC AGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGC AATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCAT
CGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACT TCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTAC CGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCC
6727-109858-02 CTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGA AGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAG CTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTC AACAGAGCTGCAACAGGTGCTGGCCCTGATCGTGATCTTCTTGACCATCGCTGTGCTGCTGGCCCTGCGCTTCTGCGGCA TCTACGGCTATAGACTGCGGAGAAAGTGGGAGGAAAAGATCCCCAATCCCAGCAAGAGCCACCTGTTTCAGAACGGCTCT GCCGAGCTGTGGCCTCCTGGCTCTATGAGCGCCTTTACAAGCGGCAGCCCTCCACATCAGGGACCTTGGGGCTCCAGATT CCCTGAGCTGGAAGGCGTGTTCCCCGTCGGCTTCGGCGACTCCGAGGTGTCCCCTCTGACAATTGAGGATCCGAAGCACG TGTGCGACCCTCCAAGCGGCCCTGATACCACCCCTGCTGCCAGCGACCTGCCTACCGAGCAGCCCCCCAGCCCACAACCT GGCCCTCCTGCCGCTTCTCACACCCCTGAGAAGCAGGCCTCCTCATTCGACTTCAACGGCCCTTACCTGGGCCCTCCTCA CAGCAGGAGCCTCCCTGATATCCTGGGCCAGCCTGAGCCTCCTCAGGAGGGCGGAAGCCAGAAGAGCCCCCCTCCAGGCA GCCTGGAGTACCTGTGCCTGCCTGCCGGAGGACAGGTGCAGCTGGTGCCCCTGGCCCAGGCTATGGGCCCTGGACAGGCC GTGGAAGTGGAAAGACGGCCTTCTCAGGGCGCCGCCGGCAGCCCCAGCCTGGAAAGCGGCGGCGGACCTGCCCCTCCTGC TCTGGGCCCCAGAGTGGGCGGCCAAGATCAGAAAGACAGCCCTGTGGCCATCCCTATGAGCAGCGGCGACACCGAGGACC CCGGAGTGGCCTCTGGATACGTGTCTTCTGCCGACCTGGTGTTCACCCCTAATAGCGGCGCCAGCAGCGTGTCCCTGGTG
CCTAGCCTCGGTCTCCCTTCCGACCAAACACCTTCTCTGTGTCCTGGCCTGGCTAGTGGCCCTCCTGGAGCCCCCGGCCC CGTGAAAAGCGGTTTTGAGGGCTACGTGGAACTGCCACCCATCGAAGGCAGATCTCCTAGAAGCCCGCGGAACAACCCAG TGCCCCCAGAGGCCAAGAGCCCTGTGCTGAACCCTGGAGAGAGACCTGCTGATGTGTCCCCCACAAGCCCACAGCCTGAA GGTCTGCTGGTCCTGCAGCAAGTTGGCGACTACTGCTTCCTGCCTGGCCTGGGCCCTGGCCCCCTGAGCCTGCGGAGCAA GCCCTCTAGCCCTGGCCCCGGCCCTGAAATCAAGAACCTGGACCAGGCCTTCCAGGTCAAGAAACCTCCCGGACAGGCAG
TGCCACAGGTGCCTGTCATCCAGCTGTTCAAGGCCCTGAAGCAGCAGGACTACCTGAGCCTGCCTCCTTGGGAGGTGAAC AAGCCCGGCGAGGTGTGTTGATAA IFNGR1-TSLPRtm-IFNGR2-IL7Ratm (SEQ ID NO: 108) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCTTTATCCTGATTAGCAGCCTGGCTATCCTGCTGATGGTGTCCCTCCTGCTGCTTTCTCTGTGGAA GCTGTGGCGGGTGAAGAAATTCCTGATCCCCAGCGTGCCAGATCCTAAGTCCATCTTCCCCGGCCTGTTCGAGATCCACC AGGGCAATTTCCAGGAGTGGATCACCGACACCCAGAACGTGGCCCACCTGCACAAAATGGCCGGCGCCGAGCAGGAGAGC GGCCCTGAGGAACCTCTGGTGGTCCAGCTGGCCAAGACCGAGGCTGAAAGCCCTAGAATGCTGGACCCCCAGACAGAAGA GAAGGAAGCCAGCGGCGGATCTCTGCAGCTGCCTCATCAGCCTCTGCAAGGCGGAGATGTGGTGACAATCGGCGGCTTCA CCTTTGTGATGAACGACAGAAGCTACGTGGCCCTGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTG AAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGT
GTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACA ACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAG TATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGA CTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCAC TGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTG ACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTA CTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACC TGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCAC CTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGCCCATTCTGCTGACCATCAGCAT CCTGAGCTTTTTCAGCGTGGCTCTGCTGGTGATCCTGGCTTGTGTGCTGTGGAAGAAGCGGATCAAGCCCATCGTGTGGC CTAGCCTCCCCGACCACAAGAAGACACTGGAACATCTGTGCAAGAAACCTAGAAAGAACCTGAACGTGTCCTTCAACCCC GAGTCCTTTCTGGACTGCCAGATCCACAGAGTGGACGACATCCAGGCCAGAGACGAGGTGGAAGGCTTCCTGCAGGACAC CTTCCCACAGCAGCTGGAGGAATCCGAGAAGCAGCGGCTGGGCGGCGACGTGCAGAGCCCTAATTGCCCTTCTGAAGATG TCGTTATCACCCCTGAGAGCTTCGGCAGAGATAGCAGCCTGACATGCCTGGCCGGCAACGTGTCTGCCTGTGACGCCCCT ATCCTGAGCTCCTCTAGAAGCCTGGATTGCCGGGAATCTGGAAAAAACGGCCCCCACGTGTACCAAGATCTGCTGCTGTC TCTGGGAACCACCAACAGCACCCTGCCTCCTCCATTCAGCCTGCAAAGCGGCATCCTGACACTGAATCCTGTGGCCCAGG GCCAGCCTATCCTTACAAGCCTGGGCAGCAACCAGGAGGAGGCCTACGTGACCATGAGCAGCTTCTACCAGAACCAGTGA TAA IFNGR1-2-INSRtm (SEQ ID NO: 109)
ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC
6727-109858-02 AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCATCATTATCGGCCCTCTGATCTTCGTGTTCCTGTTTAGCGTGGTGATCGGCTCTATCTACCTGTT TCTTAGGAAGCGGCAGCCCGACGGCCCACTGGGCCCTCTGTACGCCAGCAGCAACCCCGAGTACCTGAGCGCATCTGATG TGTTTCCTTGTAGCGTATACGTGCCTGATGAGTGGGAGGTGTCTCGGGAGAAGATCACCCTGCTGAGAGAGCTGGGACAA GGCAGCTTCGGCATGGTTTACGAGGGCAACGCCAGAGACATCATCAAGGGCGAGGCCGAGACAAGAGTGGCTGTGAAGAC CGTGAACGAGAGCGCCAGCCTGCGGGAACGGATCGAGTTCCTGAACGAGGCCAGCGTGATGAAGGGCTTCACCTGTCACC ACGTGGTGCGCCTGCTGGGCGTGGTCTCCAAGGGCCAACCTACCCTGGTCGTCATGGAACTGATGGCCCACGGCGACCTG AAAAGCTATCTGAGATCTCTGCGGCCTGAAGCTGAGAACAACCCAGGCAGACCCCCACCTACACTGCAGGAGATGATTCA GATGGCCGCCGAGATCGCCGACGGCATGGCCTACCTGAATGCCAAGAAGTTCGTTCACAGAGACCTGGCCGCTAGAAACT
GCATGGTGGCCCATGATTTCACAGTGAAAATCGGCGATTTCGGCATGACCAGAGATATCTACGAGACAGACTACTACCGG AAGGGCGGCAAGGGACTGCTCCCTGTGCGGTGGATGGCTCCTGAGAGCCTGAAGGACGGCGTGTTCACCACAAGCTCCGA CATGTGGAGCTTTGGAGTGGTGCTCTGGGAAATCACTTCTCTGGCCGAACAGCCCTATCAGGGCCTGAGCAATGAACAGG TGCTGAAGTTCGTGATGGACGGCGGGTACCTGGACCAGCCTGACAATTGCCCGGAGAGAGTGACCGACCTGATGCGGATG TGCTGGCAGTTCAACCCTAAGATGAGACCCACCTTCCTGGAAATCGTGAATCTGCTGAAAGACGACCTGCACCCTAGCTT
CCCCGAGGTGTCTTTCTTCCACAGCGAGGAAAACAAGGCCCCTGAGTCCGAAGAGCTGGAAATGGAGTTCGAGGACATGG AAAACGTGCCCCTGGATAGATCCTCCCACTGCCAGAGAGAAGAGGCCGGAGGTCGGGATGGCGGCAGCTCTCTTGGATTT AAGAGAAGCTACGAGGAACACATCCCTTACACCCACATGAACGGCGGAAAAAAAAACGGAAGAATCCTGACCCTGCCTAG AAGCAACCCCAGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGG AAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCT CCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTG GGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCA CCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGC GCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAAT GCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGA TTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAA GGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTG TCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACG AGACAATGGCCGATGCCTCAACAGAGCTGCAACAGATCATTATCGGCCCTCTGATCTTCGTGTTCCTGTTTAGCGTGGTG ATCGGCTCTATCTACCTGTTTCTTAGGAAGCGGCAGCCCGACGGCCCACTGGGCCCTCTGTACGCCAGCAGCAACCCCGA GTACCTGAGCGCATCTGATGTGTTTCCTTGTAGCGTATACGTGCCTGATGAGTGGGAGGTGTCTCGGGAGAAGATCACCC TGCTGAGAGAGCTGGGACAAGGCAGCTTCGGCATGGTTTACGAGGGCAACGCCAGAGACATCATCAAGGGCGAGGCCGAG ACAAGAGTGGCTGTGAAGACCGTGAACGAGAGCGCCAGCCTGCGGGAACGGATCGAGTTCCTGAACGAGGCCAGCGTGAT GAAGGGCTTCACCTGTCACCACGTGGTGCGCCTGCTGGGCGTGGTCTCCAAGGGCCAACCTACCCTGGTCGTCATGGAAC TGATGGCCCACGGCGACCTGAAAAGCTATCTGAGATCTCTGCGGCCTGAAGCTGAGAACAACCCAGGCAGACCCCCACCT
ACACTGCAGGAGATGATTCAGATGGCCGCCGAGATCGCCGACGGCATGGCCTACCTGAATGCCAAGAAGTTCGTTCACAG AGACCTGGCCGCTAGAAACTGCATGGTGGCCCATGATTTCACAGTGAAAATCGGCGATTTCGGCATGACCAGAGATATCT ACGAGACAGACTACTACCGGAAGGGCGGCAAGGGACTGCTCCCTGTGCGGTGGATGGCTCCTGAGAGCCTGAAGGACGGC GTGTTCACCACAAGCTCCGACATGTGGAGCTTTGGAGTGGTGCTCTGGGAAATCACTTCTCTGGCCGAACAGCCCTATCA GGGCCTGAGCAATGAACAGGTGCTGAAGTTCGTGATGGACGGCGGGTACCTGGACCAGCCTGACAATTGCCCGGAGAGAG TGACCGACCTGATGCGGATGTGCTGGCAGTTCAACCCTAAGATGAGACCCACCTTCCTGGAAATCGTGAATCTGCTGAAA GACGACCTGCACCCTAGCTTCCCCGAGGTGTCTTTCTTCCACAGCGAGGAAAACAAGGCCCCTGAGTCCGAAGAGCTGGA AATGGAGTTCGAGGACATGGAAAACGTGCCCCTGGATAGATCCTCCCACTGCCAGAGAGAAGAGGCCGGAGGTCGGGATG GCGGCAGCTCTCTTGGATTTAAGAGAAGCTACGAGGAACACATCCCTTACACCCACATGAACGGCGGAAAAAAAAACGGA AGAATCCTGACCCTGCCTAGAAGCAACCCCAGCTGATAA IFNGR1-CSF2RBtm-IFNGR2-GMCSFRAtm (SEQ ID NO: 110) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT
GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCGTGCTGGCCCTGATCGTGATCTTCTTGACCATCGCTGTGCTGCTGGCCCTGCGCTTCTGCGGCAT CTACGGCTATAGACTGCGGAGAAAGTGGGAGGAAAAGATCCCCAATCCCAGCAAGAGCCACCTGTTTCAGAACGGCTCTG
6727-109858-02 CCGAGCTGTGGCCTCCTGGCTCTATGAGCGCCTTTACAAGCGGCAGCCCTCCACATCAGGGACCTTGGGGCTCCAGATTC CCTGAGCTGGAAGGCGTGTTCCCCGTCGGCTTCGGCGACTCCGAGGTGTCCCCTCTGACAATTGAGGATCCGAAGCACGT GTGCGACCCTCCAAGCGGCCCTGATACCACCCCTGCTGCCAGCGACCTGCCTACCGAGCAGCCCCCCAGCCCACAACCTG GCCCTCCTGCCGCTTCTCACACCCCTGAGAAGCAGGCCTCCTCATTCGACTTCAACGGCCCTTACCTGGGCCCTCCTCAC AGCAGGAGCCTCCCTGATATCCTGGGCCAGCCTGAGCCTCCTCAGGAGGGCGGAAGCCAGAAGAGCCCCCCTCCAGGCAG CCTGGAGTACCTGTGCCTGCCTGCCGGAGGACAGGTGCAGCTGGTGCCCCTGGCCCAGGCTATGGGCCCTGGACAGGCCG TGGAAGTGGAAAGACGGCCTTCTCAGGGCGCCGCCGGCAGCCCCAGCCTGGAAAGCGGCGGCGGACCTGCCCCTCCTGCT CTGGGCCCCAGAGTGGGCGGCCAAGATCAGAAAGACAGCCCTGTGGCCATCCCTATGAGCAGCGGCGACACCGAGGACCC CGGAGTGGCCTCTGGATACGTGTCTTCTGCCGACCTGGTGTTCACCCCTAATAGCGGCGCCAGCAGCGTGTCCCTGGTGC CTAGCCTCGGTCTCCCTTCCGACCAAACACCTTCTCTGTGTCCTGGCCTGGCTAGTGGCCCTCCTGGAGCCCCCGGCCCC GTGAAAAGCGGTTTTGAGGGCTACGTGGAACTGCCACCCATCGAAGGCAGATCTCCTAGAAGCCCGCGGAACAACCCAGT GCCCCCAGAGGCCAAGAGCCCTGTGCTGAACCCTGGAGAGAGACCTGCTGATGTGTCCCCCACAAGCCCACAGCCTGAAG GTCTGCTGGTCCTGCAGCAAGTTGGCGACTACTGCTTCCTGCCTGGCCTGGGCCCTGGCCCCCTGAGCCTGCGGAGCAAG CCCTCTAGCCCTGGCCCCGGCCCTGAAATCAAGAACCTGGACCAGGCCTTCCAGGTCAAGAAACCTCCCGGACAGGCAGT
GCCACAGGTGCCTGTCATCCAGCTGTTCAAGGCCCTGAAGCAGCAGGACTACCTGAGCCTGCCTCCTTGGGAGGTGAACA AGCCCGGCGAGGTGTGTAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTG GAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGC TGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCA GCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGG
TTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCC TAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGA CAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCT CTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGA GAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGT ACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGC TACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGAATCTGGGCAGCGTGTACATCTACGTGCTGCTGATCGTGGG CACACTGGTGTGCGGCATCGTGCTGGGATTCCTGTTCAAAAGATTCCTGAGAATCCAGAGACTGTTTCCACCTGTGCCCC AGATCAAGGACAAGCTGAACGACAACCACGAGGTGGAAGATGAGATTATCTGGGAGGAGTTCACCCCTGAGGAAGGCAAG GGCTACCGGGAAGAGGTCCTCACCGTGAAGGAAATCACCTGATAA IFNGR1-IL2Rbtm-IFNGR2-IL2Rgtm (SEQ ID NO: 111) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT
GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCATTCCTTGGCTGGGTCACCTGCTGGTGGGCCTGTCCGGCGCCTTCGGCTTCATCATCCTGGTCTA CCTGCTGATCAACTGCAGAAACACCGGCCCTTGGCTGAAAAAGGTGCTGAAGTGCAACACCCCTGATCCTAGCAAGTTCT TCAGCCAGCTGAGCAGCGAGCACGGCGGCGACGTGCAGAAGTGGCTGAGCAGCCCGTTCCCCAGCTCTTCTTTTTCTCCT GGCGGACTGGCCCCTGAGATCAGCCCCCTGGAAGTGCTGGAACGGGACAAAGTGACCCAACTGCTGCTGCAGCAGGATAA GGTGCCCGAGCCTGCCAGCCTCAGCAGCAATCACAGCCTGACATCATGCTTCACCAACCAGGGCTACTTCTTTTTTCACC TGCCCGACGCCCTGGAAATCGAGGCTTGTCAGGTGTATTTCACCTACGACCCCTACAGCGAGGAAGATCCCGACGAGGGC GTTGCCGGCGCCCCTACCGGCAGCAGCCCCCAGCCCCTGCAACCACTGTCCGGCGAGGACGACGCCTACTGCACCTTCCC TAGCAGAGATGATCTGCTGCTCTTCAGCCCCTCCCTGCTGGGCGGCCCCTCTCCTCCCAGCACCGCCCCTGGAGGAAGCG GCGCTGGAGAGGAAAGAATGCCTCCTTCTCTTCAAGAGAGAGTGCCAAGAGACTGGGACCCCCAGCCTCTGGGCCCTCCA ACACCCGGCGTGCCTGACCTGGTCGACTTCCAGCCTCCTCCAGAACTGGTGCTGAGGGAAGCCGGCGAAGAGGTGCCAGA CGCCGGACCTAGAGAGGGCGTGTCCTTTCCTTGGAGCCGGCCTCCTGGCCAGGGCGAGTTCCGGGCCCTAAACGCCAGAC TGCCTCTGAATACAGATGCTTACCTGTCTCTGCAGGAGCTGCAGGGACAGGACCCTACACATCTGAGAGCCAAGAGGAGC GGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACT GCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTG CCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACC AGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAA CTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCA CCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTG ACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACAT
TGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTT TCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGG AACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCT
6727-109858-02 GCAACAGGTGGTGATCAGCGTGGGCAGCATGGGCCTGATCATCTCTCTGCTGTGCGTGTACTTCTGGCTGGAAAGAACAA TGCCTAGAATCCCCACACTGAAGAACCTGGAAGATCTGGTCACCGAGTACCACGGAAATTTCAGCGCCTGGTCCGGCGTG TCCAAGGGCCTCGCCGAGAGCCTGCAGCCTGACTACAGCGAGCGGCTGTGTCTGGTGTCTGAGATCCCACCTAAGGGAGG CGCTCTGGGCGAGGGCCCCGGCGCCAGCCCTTGCAACCAGCACAGCCCCTATTGGGCCCCTCCATGCTACACCCTGAAAC CTGAAACCTGATAA IFNGR1-IL7Ratm-IFNGR2-IL2Rgtm (SEQ ID NO: 112) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT
CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCCCCATTCTGCTGACCATCAGCATCCTGAGCTTTTTCAGCGTGGCTCTGCTGGTGATCCTGGCTTG TGTGCTGTGGAAGAAGCGGATCAAGCCCATCGTGTGGCCTAGCCTCCCCGACCACAAGAAGACACTGGAACATCTGTGCA AGAAACCTAGAAAGAACCTGAACGTGTCCTTCAACCCCGAGTCCTTTCTGGACTGCCAGATCCACAGAGTGGACGACATC
CAGGCCAGAGACGAGGTGGAAGGCTTCCTGCAGGACACCTTCCCACAGCAGCTGGAGGAATCCGAGAAGCAGCGGCTGGG CGGCGACGTGCAGAGCCCTAATTGCCCTTCTGAAGATGTCGTTATCACCCCTGAGAGCTTCGGCAGAGATAGCAGCCTGA CATGCCTGGCCGGCAACGTGTCTGCCTGTGACGCCCCTATCCTGAGCTCCTCTAGAAGCCTGGATTGCCGGGAATCTGGA AAAAACGGCCCCCACGTGTACCAAGATCTGCTGCTGTCTCTGGGAACCACCAACAGCACCCTGCCTCCTCCATTCAGCCT GCAAAGCGGCATCCTGACACTGAATCCTGTGGCCCAGGGCCAGCCTATCCTTACAAGCCTGGGCAGCAACCAGGAGGAGG CCTACGTGACCATGAGCAGCTTCTACCAGAACCAGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTG AAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGT GTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACA ACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAG TATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGA CTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCAC TGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTG ACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTA CTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACC TGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCAC CTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTGGTGATCAGCGTGGGCAGCAT GGGCCTGATCATCTCTCTGCTGTGCGTGTACTTCTGGCTGGAAAGAACAATGCCTAGAATCCCCACACTGAAGAACCTGG AAGATCTGGTCACCGAGTACCACGGAAATTTCAGCGCCTGGTCCGGCGTGTCCAAGGGCCTCGCCGAGAGCCTGCAGCCT GACTACAGCGAGCGGCTGTGTCTGGTGTCTGAGATCCCACCTAAGGGAGGCGCTCTGGGCGAGGGCCCCGGCGCCAGCCC TTGCAACCAGCACAGCCCCTATTGGGCCCCTCCATGCTACACCCTGAAACCTGAAACCTGATAA IFNGR1-IL9Rtm-IFNGR2-IL2Rgtm (SEQ ID NO: 113) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCGGAAACACCCTGGTGGCCGTGTCCATCTTTCTGCTGCTGACCGGCCCCACCTACCTGCTGTTCAA GCTGTCTCCAAGAGTGAAGCGGATCTTCTACCAGAACGTGCCTAGCCCCGCCATGTTCTTCCAACCTCTGTACTCTGTGC ACAACGGCAACTTCCAGACATGGATGGGCGCCCACGGCGCTGGCGTGCTGCTGAGCCAGGACTGCGCCGGCACCCCTCAG GGCGCCCTTGAACCCTGTGTGCAGGAGGCTACCGCCCTGCTGACATGCGGCCCTGCAAGACCCTGGAAAAGCGTGGCCCT GGAAGAAGAGCAGGAAGGCCCTGGCACAAGACTGCCCGGTAACCTGAGCTCCGAGGACGTGCTGCCAGCTGGATGTACCG AGTGGCGGGTCCAGACCCTGGCCTATCTGCCACAAGAAGATTGGGCCCCTACCAGCCTGACAAGGCCTGCTCCTCCTGAT AGCGAGGGCAGCAGAAGCTCCAGCAGCTCTTCTTCTAGCAACAACAACAATTACTGCGCCCTGGGCTGCTACGGCGGATG GCATCTGTCCGCCCTGCCTGGCAATACCCAGAGCAGCGGCCCTATCCCCGCCCTGGCCTGTGGCCTGAGCTGCGACCACC AGGGCCTCGAGACACAGCAGGGAGTGGCCTGGGTTCTGGCCGGCCACTGCCAGCGGCCTGGACTGCACGAGGACCTGCAG
GGCATGCTGCTCCCTAGCGTGCTGAGCAAGGCCAGAAGCTGGACCTTTAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAA TTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGC TACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAG
6727-109858-02 ATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCA AGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCG CCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCC GAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGA GAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAG CCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATT AGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTT CCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTGGTGATCA GCGTGGGCAGCATGGGCCTGATCATCTCTCTGCTGTGCGTGTACTTCTGGCTGGAAAGAACAATGCCTAGAATCCCCACA CTGAAGAACCTGGAAGATCTGGTCACCGAGTACCACGGAAATTTCAGCGCCTGGTCCGGCGTGTCCAAGGGCCTCGCCGA GAGCCTGCAGCCTGACTACAGCGAGCGGCTGTGTCTGGTGTCTGAGATCCCACCTAAGGGAGGCGCTCTGGGCGAGGGCC CCGGCGCCAGCCCTTGCAACCAGCACAGCCCCTATTGGGCCCCTCCATGCTACACCCTGAAACCTGAAACCTGATAA IFNGR1-2-GP130 (SEQ ID NO: 114)
ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA
TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCGCTATCGTGGTCCCCGTGTGCCTGGCCTTTCTGCTCACCACCCTGCTGGGCGTGCTGTTCTGCTT CAACAAGCGCGACCTGATCAAGAAACACATCTGGCCTAATGTGCCCGATCCTTCTAAGTCTCATATCGCCCAGTGGAGCC CTCACACCCCTCCAAGACACAACTTTAACAGCAAGGACCAGATGTACAGCGACGGCAACTTCACCGACGTGTCTGTGGTG GAAATCGAAGCCAACGACAAGAAGCCCTTCCCCGAGGATCTGAAGAGCCTGGACCTTTTTAAGAAGGAAAAGATCAACAC CGAGGGCCACAGCAGCGGCATCGGCGGAAGCTCCTGCATGAGCAGCTCTAGACCTAGCATCAGCTCTTCTGATGAGAACG AGAGCAGCCAGAACACAAGCAGCACCGTGCAGTACAGCACCGTCGTGCACTCTGGCTACAGACACCAGGTTCCAAGCGTG CAGGTGTTCAGCAGAAGCGAGTCTACCCAGCCTCTGCTGGATAGCGAGGAACGGCCTGAGGACCTGCAGCTGGTGGATCA CGTGGACGGCGGCGACGGAATCCTGCCTAGACAGCAGTACTTCAAGCAGAATTGCAGCCAACACGAGAGCTCACCTGACA TCTCCCACTTCGAGCGGAGCAAACAAGTGTCCAGCGTGAACGAGGAAGATTTCGTGAGGCTGAAACAACAGATCTCCGAC CACATTAGCCAGAGCTGTGGCAGCGGACAGATGAAAATGTTCCAGGAGGTGTCCGCCGCCGACGCCTTCGGCCCTGGTAC AGAGGGCCAGGTGGAAAGATTCGAGACAGTCGGCATGGAAGCCGCTACAGACGAAGGCATGCCCAAGTCCTACCTGCCCC AGACCGTGCGGCAGGGCGGATATATGCCTCAGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAG CAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTT CGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACG CCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTAT ACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTT
CACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGC ACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACC CCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTA CGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGA AGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTG AGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGCTATCGTGGTCCCCGTGTGCCTGGC CTTTCTGCTCACCACCCTGCTGGGCGTGCTGTTCTGCTTCAACAAGCGCGACCTGATCAAGAAACACATCTGGCCTAATG TGCCCGATCCTTCTAAGTCTCATATCGCCCAGTGGAGCCCTCACACCCCTCCAAGACACAACTTTAACAGCAAGGACCAG ATGTACAGCGACGGCAACTTCACCGACGTGTCTGTGGTGGAAATCGAAGCCAACGACAAGAAGCCCTTCCCCGAGGATCT GAAGAGCCTGGACCTTTTTAAGAAGGAAAAGATCAACACCGAGGGCCACAGCAGCGGCATCGGCGGAAGCTCCTGCATGA GCAGCTCTAGACCTAGCATCAGCTCTTCTGATGAGAACGAGAGCAGCCAGAACACAAGCAGCACCGTGCAGTACAGCACC GTCGTGCACTCTGGCTACAGACACCAGGTTCCAAGCGTGCAGGTGTTCAGCAGAAGCGAGTCTACCCAGCCTCTGCTGGA TAGCGAGGAACGGCCTGAGGACCTGCAGCTGGTGGATCACGTGGACGGCGGCGACGGAATCCTGCCTAGACAGCAGTACT TCAAGCAGAATTGCAGCCAACACGAGAGCTCACCTGACATCTCCCACTTCGAGCGGAGCAAACAAGTGTCCAGCGTGAAC GAGGAAGATTTCGTGAGGCTGAAACAACAGATCTCCGACCACATTAGCCAGAGCTGTGGCAGCGGACAGATGAAAATGTT CCAGGAGGTGTCCGCCGCCGACGCCTTCGGCCCTGGTACAGAGGGCCAGGTGGAAAGATTCGAGACAGTCGGCATGGAAG CCGCTACAGACGAAGGCATGCCCAAGTCCTACCTGCCCCAGACCGTGCGGCAGGGCGGATATATGCCTCAG IFNGR1-2-CD28 (SEQ ID NO: 115) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC
TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG
6727-109858-02 CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCTTTTGGGTCCTGGTGGTGGTGGGCGGAGTGCTGGCCTGCTACAGCCTGCTGGTGACCGTGGCCTT CATCATCTTCTGGGTGCGGTCCAAGCGGTCTAGACTGCTGCACAGCGACTACATGAACATGACCCCTAGACGGCCCGGCC CTACAAGAAAGCACTACCAGCCCTACGCCCCTCCAAGAGATTTCGCCGCTTATAGAAGCAGAGCCAAGAGGAGCGGCAGC GGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTG GTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTC AACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCA GTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCAC TCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGA GACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTG
GGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGA TACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAA GCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAG AGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACA GTTTTGGGTCCTGGTGGTGGTGGGCGGAGTGCTGGCCTGCTACAGCCTGCTGGTGACCGTGGCCTTCATCATCTTCTGGG
TGCGGTCCAAGCGGTCTAGACTGCTGCACAGCGACTACATGAACATGACCCCTAGACGGCCCGGCCCTACAAGAAAGCAC TACCAGCCCTACGCCCCTCCAAGAGATTTCGCCGCTTATAGAAGC IFNGR1-2-CD28_YMFM (SEQ ID NO: 116) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCTTTTGGGTCCTGGTGGTGGTGGGCGGCGTGCTGGCCTGCTACAGCCTGCTGGTGACAGTGGCCTT CATCATCTTCTGGGTGCGGTCCAAGCGGTCTAGACTGCTGCACAGCGACTACATGTTCATGACCCCTAGACGGCCCGGAC CTACCAGAAAGCACTACCAGCCCTACGCCCCTCCAAGAGATTTCGCCGCTTATAGAAGCAGAGCCAAGAGGAGCGGCAGC GGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTG GTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTC AACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCA GTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCAC
TCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGA GACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTG GGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGA TACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAA GCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAG AGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACA GTTTTGGGTCCTGGTGGTGGTGGGCGGCGTGCTGGCCTGCTACAGCCTGCTGGTGACAGTGGCCTTCATCATCTTCTGGG TGCGGTCCAAGCGGTCTAGACTGCTGCACAGCGACTACATGTTCATGACCCCTAGACGGCCCGGACCTACCAGAAAGCAC TACCAGCCCTACGCCCCTCCAAGAGATTTCGCCGCTTATAGAAGC IFNGR1-2-4-1BB (SEQ ID NO: 117) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC
AGCAGCATCAAGGGCATCATCTCCTTCTTCCTGGCCCTGACCTCTACAGCCCTGCTGTTTCTGCTCTTTTTCCTGACACT GAGATTCAGCGTGGTGAAGCGGGGCAGAAAGAAACTGCTGTACATCTTCAAGCAGCCTTTCATGCGGCCTGTGCAGACCA CCCAGGAGGAGGACGGCTGCAGCTGCAGATTCCCCGAGGAAGAGGAAGGCGGATGTGAACTGAGAGCCAAGAGGAGCGGC
6727-109858-02 AGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCT GTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCC CTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGA CCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTG CACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCC TGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACC GTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGC CGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCA GAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAAC AAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCA ACAGATCATCTCCTTCTTCCTGGCCCTGACCTCTACAGCCCTGCTGTTTCTGCTCTTTTTCCTGACACTGAGATTCAGCG TGGTGAAGCGGGGCAGAAAGAAACTGCTGTACATCTTCAAGCAGCCTTTCATGCGGCCTGTGCAGACCACCCAGGAGGAG GACGGCTGCAGCTGCAGATTCCCCGAGGAAGAGGAAGGCGGATGTGAACTG
IFNGR1-2-ICOS (SEQ ID NO: 118) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG
CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCTTCTGGCTGCCTATCGGCTGCGCCGCTTTTGTGGTGGTCTGCATCCTGGGATGTATCCTGATCTG CTGGCTGACAAAGAAAAAGTACAGCTCTAGCGTGCACGACCCCAACGGCGAGTACATGTTCATGCGGGCCGTGAACACCG CCAAGAAGTCCAGACTGACCGATGTGACCCTGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAG CAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTT CGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACG CCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTAT ACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTT CACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGC ACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACC CCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTA CGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGA AGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTG AGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGTTCTGGCTGCCTATCGGCTGCGCCGC TTTTGTGGTGGTCTGCATCCTGGGATGTATCCTGATCTGCTGGCTGACAAAGAAAAAGTACAGCTCTAGCGTGCACGACC CCAACGGCGAGTACATGTTCATGCGGGCCGTGAACACCGCCAAGAAGTCCAGACTGACCGATGTGACCCTG IFNGR1-2-CD2 (SEQ ID NO: 119) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCATTTACCTGATCATCGGCATCTGCGGCGGCGGATCTCTGCTCATGGTGTTCGTGGCCCTGCTGGT GTTCTACATCACCAAGCGGAAGAAACAGCGCTCTAGACGGAACGACGAGGAGCTGGAAACAAGAGCCCACAGAGTGGCCA CCGAGGAAAGAGGCAGAAAGCCCCACCAAATCCCCGCTAGCACCCCTCAGAATCCTGCTACCAGCCAGCATCCTCCTCCT CCACCAGGACACAGGTCCCAGGCCCCTAGCCACCGGCCTCCACCTCCTGGCCACCGGGTCCAGCACCAGCCCCAGAAAAG ACCCCCCGCCCCTAGCGGCACACAGGTGCACCAGCAGAAGGGCCCTCCCCTGCCTAGACCCAGAGTGCAACCCAAGCCTC CTCACGGCGCCGCCGAGAACAGCCTGTCCCCTAGCAGCAACAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCA CTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCT GGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCC TGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAG
TTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGA ATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGG GAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATC
6727-109858-02 GAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTT CTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGG ATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTG GGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGATTTACCTGATCATCGG CATCTGCGGCGGCGGATCTCTGCTCATGGTGTTCGTGGCCCTGCTGGTGTTCTACATCACCAAGCGGAAGAAACAGCGCT CTAGACGGAACGACGAGGAGCTGGAAACAAGAGCCCACAGAGTGGCCACCGAGGAAAGAGGCAGAAAGCCCCACCAAATC CCCGCTAGCACCCCTCAGAATCCTGCTACCAGCCAGCATCCTCCTCCTCCACCAGGACACAGGTCCCAGGCCCCTAGCCA CCGGCCTCCACCTCCTGGCCACCGGGTCCAGCACCAGCCCCAGAAAAGACCCCCCGCCCCTAGCGGCACACAGGTGCACC AGCAGAAGGGCCCTCCCCTGCCTAGACCCAGAGTGCAACCCAAGCCTCCTCACGGCGCCGCCGAGAACAGCCTGTCCCCT AGCAGCAAC IFNGR1-2-TLR1 (SEQ ID NO: 120) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC
CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT
CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCCTGCTGATCGTGACCATCGTGGCCACCATGCTGGTGCTGGCCGTGACCGTGACCAGCCTGTGCAG CTATCTGGATCTGCCTTGGTACCTGCGGATGGTTTGTCAGTGGACACAGACAAGAAGGCGGGCTAGAAATATCCCCCTGG AGGAACTCCAAAGAAACCTGCAGTTCCACGCCTTTATCAGCTACTCCGGCCACGACAGCTTCTGGGTCAAGAACGAGCTG CTGCCTAACCTGGAAAAAGAGGGCATGCAGATCTGCCTGCACGAGAGAAACTTCGTGCCCGGCAAGTCTATCGTGGAAAA CATCATCACCTGCATCGAGAAATCTTACAAGTCCATCTTCGTGCTGAGCCCTAATTTCGTGCAGAGCGAGTGGTGCCACT ACGAGCTGTACTTCGCCCACCACAACCTGTTCCATGAGGGCAGCAACAGCCTGATTCTGATCCTGCTGGAACCTATCCCA CAGTACAGCATCCCCAGCAGCTACCACAAGCTGAAGTCCCTGATGGCCAGACGGACATACCTGGAATGGCCTAAGGAAAA GTCTAAGCGCGGACTTTTTTGGGCCAACCTGAGAGCCGCTATCAACATTAAGCTGACCGAGCAGGCCAAGAAAAGAGCCA AGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGG CCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCA GCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCA ATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATC GGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTT CAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACC GCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCC TTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAA GGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGC TGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCA
ACAGAGCTGCAACAGCTGCTGATCGTGACCATCGTGGCCACCATGCTGGTGCTGGCCGTGACCGTGACCAGCCTGTGCAG CTATCTGGATCTGCCTTGGTACCTGCGGATGGTTTGTCAGTGGACACAGACAAGAAGGCGGGCTAGAAATATCCCCCTGG AGGAACTCCAAAGAAACCTGCAGTTCCACGCCTTTATCAGCTACTCCGGCCACGACAGCTTCTGGGTCAAGAACGAGCTG CTGCCTAACCTGGAAAAAGAGGGCATGCAGATCTGCCTGCACGAGAGAAACTTCGTGCCCGGCAAGTCTATCGTGGAAAA CATCATCACCTGCATCGAGAAATCTTACAAGTCCATCTTCGTGCTGAGCCCTAATTTCGTGCAGAGCGAGTGGTGCCACT ACGAGCTGTACTTCGCCCACCACAACCTGTTCCATGAGGGCAGCAACAGCCTGATTCTGATCCTGCTGGAACCTATCCCA CAGTACAGCATCCCCAGCAGCTACCACAAGCTGAAGTCCCTGATGGCCAGACGGACATACCTGGAATGGCCTAAGGAAAA GTCTAAGCGCGGACTTTTTTGGGCCAACCTGAGAGCCGCTATCAACATTAAGCTGACCGAGCAGGCCAAGAAA IFNGR1-2-TLR2 (SEQ ID NO: 121) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCGCTCTCGTGTCCGGCATGTGCTGCGCCCTGTTCCTGCTGATCCTGCTGACCGGCGTGCTTTGTCA
CAGATTCCACGGCCTGTGGTATATGAAAATGATGTGGGCCTGGCTGCAGGCCAAGCGGAAGCCCAGAAAAGCCCCTTCTA GAAACATCTGCTACGACGCTTTTGTGAGCTACAGCGAGCGGGACGCCTACTGGGTCGAGAATCTGATGGTGCAGGAGCTG GAAAACTTCAACCCACCTTTCAAGCTGTGTCTGCACAAAAGAGATTTCATCCCCGGAAAGTGGATCATCGACAACATCAT
6727-109858-02 CGATAGCATCGAGAAGAGCCACAAGACAGTGTTCGTGCTGAGCGAGAATTTCGTGAAGTCTGAATGGTGCAAGTACGAGC TGGACTTCAGCCATTTCAGACTGTTTGATGAGAACAACGACGCCGCCATCCTGATCCTGCTGGAACCTATCGAGAAAAAG GCCATCCCTCAAAGATTCTGCAAGCTGAGAAAGATCATGAACACCAAGACCTACCTGGAATGGCCTATGGACGAGGCCCA GCGGGAAGGCTTTTGGGTGAACCTGCGCGCCGCTATTAAGTCCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCT CACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTG CTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCG CCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGC AGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACA GAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACT GGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACA TCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTC TTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCT GGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGG TGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGCTCTCGTGTCCGGC
ATGTGCTGCGCCCTGTTCCTGCTGATCCTGCTGACCGGCGTGCTTTGTCACAGATTCCACGGCCTGTGGTATATGAAAAT GATGTGGGCCTGGCTGCAGGCCAAGCGGAAGCCCAGAAAAGCCCCTTCTAGAAACATCTGCTACGACGCTTTTGTGAGCT ACAGCGAGCGGGACGCCTACTGGGTCGAGAATCTGATGGTGCAGGAGCTGGAAAACTTCAACCCACCTTTCAAGCTGTGT CTGCACAAAAGAGATTTCATCCCCGGAAAGTGGATCATCGACAACATCATCGATAGCATCGAGAAGAGCCACAAGACAGT GTTCGTGCTGAGCGAGAATTTCGTGAAGTCTGAATGGTGCAAGTACGAGCTGGACTTCAGCCATTTCAGACTGTTTGATG
AGAACAACGACGCCGCCATCCTGATCCTGCTGGAACCTATCGAGAAAAAGGCCATCCCTCAAAGATTCTGCAAGCTGAGA AAGATCATGAACACCAAGACCTACCTGGAATGGCCTATGGACGAGGCCCAGCGGGAAGGCTTTTGGGTGAACCTGCGCGC CGCTATTAAGTCC IFNGR1-2-TLR4 (SEQ ID NO: 122) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCACCATCATTGGAGTCTCTGTGCTGAGCGTGCTGGTGGTGTCTGTGGTGGCCGTGCTTGTGTACAA GTTCTACTTCCATCTGATGCTGCTGGCCGGCTGTATTAAGTACGGCAGAGGCGAGAACATCTACGACGCCTTCGTGATCT ACAGCAGCCAGGACGAGGATTGGGTGCGGAATGAGCTGGTGAAGAACCTGGAAGAGGGCGTTCCTCCATTCCAGCTGTGC CTGCACTATCGGGACTTCATCCCCGGCGTGGCTATCGCCGCTAATATCATCCACGAGGGATTTCACAAATCCCGGAAGGT GATCGTGGTCGTCTCCCAACACTTCATCCAGAGCAGATGGTGCATCTTCGAGTACGAGATCGCCCAGACCTGGCAGTTCC TGAGCAGCCGCGCCGGAATCATCTTTATCGTGCTGCAAAAGGTGGAAAAGACCCTGCTCAGACAGCAGGTGGAACTGTAC
AGACTGCTGTCTAGAAACACCTACCTGGAATGGGAAGATAGCGTGCTGGGCAGACACATCTTCTGGCGGAGACTGAGAAA AGCCCTGCTGGACGGCAAGAGCTGGAACCCTGAGGGCACAGTGGGCACCGGCTGCAACTGGCAGGAGGCCACAAGCATCA GAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCT ATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCT GAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCC TGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATG AGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTAT GGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGC ACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGC AGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCA GGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGG CCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGAT GCCTCAACAGAGCTGCAACAGACCATCATTGGAGTCTCTGTGCTGAGCGTGCTGGTGGTGTCTGTGGTGGCCGTGCTTGT GTACAAGTTCTACTTCCATCTGATGCTGCTGGCCGGCTGTATTAAGTACGGCAGAGGCGAGAACATCTACGACGCCTTCG TGATCTACAGCAGCCAGGACGAGGATTGGGTGCGGAATGAGCTGGTGAAGAACCTGGAAGAGGGCGTTCCTCCATTCCAG CTGTGCCTGCACTATCGGGACTTCATCCCCGGCGTGGCTATCGCCGCTAATATCATCCACGAGGGATTTCACAAATCCCG GAAGGTGATCGTGGTCGTCTCCCAACACTTCATCCAGAGCAGATGGTGCATCTTCGAGTACGAGATCGCCCAGACCTGGC AGTTCCTGAGCAGCCGCGCCGGAATCATCTTTATCGTGCTGCAAAAGGTGGAAAAGACCCTGCTCAGACAGCAGGTGGAA CTGTACAGACTGCTGTCTAGAAACACCTACCTGGAATGGGAAGATAGCGTGCTGGGCAGACACATCTTCTGGCGGAGACT GAGAAAAGCCCTGCTGGACGGCAAGAGCTGGAACCCTGAGGGCACAGTGGGCACCGGCTGCAACTGGCAGGAGGCCACAA
GCATC
6727-109858-02 IFNGR1-2-TLR6 (SEQ ID NO: 123) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCCTCATTGTGACAATCGGAGCCACCATGCTGGTGCTGGCCGTGACCGTGACAAGCCTGTGTATCTA CCTGGACCTGCCTTGGTACCTGAGAATGGTGTGCCAGTGGACCCAGACCAGACGGAGAGCCAGAAACATCCCTCTGGAGG AACTGCAAAGAAATCTGCAGTTCCACGCCTTCATCAGCTACAGCGAGCACGACAGCGCCTGGGTTAAATCTGAACTGGTC CCCTACCTCGAGAAAGAAGATATCCAGATCTGCCTGCACGAGCGGAATTTCGTGCCCGGCAAGAGCATTGTGGAAAACAT
CATCAACTGCATCGAGAAGTCTTATAAGTCCATCTTCGTGCTTTCTCCTAACTTCGTGCAGAGCGAGTGGTGCCACTACG AGCTGTACTTCGCCCACCACAACCTGTTCCATGAGGGCAGCAACAACCTGATCCTGATCCTGCTGGAACCTATCCCCCAG AACAGCATCCCAAACAAGTACCACAAGCTGAAGGCCCTGATGACCCAGAGAACCTACCTGCAGTGGCCTAAGGAAAAGTC CAAGCGCGGCCTGTTTTGGGCTAATATCCGGGCCGCTTTTAACATGAAACTGACACTGGTGACCGAGAACAACGACGTGA AGAGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCT
GGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGA CCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTG TCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGAC ATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATT TCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGT TTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGA TTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCAT CCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGG TGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATG GCCGATGCCTCAACAGAGCTGCAACAGCTCATTGTGACAATCGGAGCCACCATGCTGGTGCTGGCCGTGACCGTGACAAG CCTGTGTATCTACCTGGACCTGCCTTGGTACCTGAGAATGGTGTGCCAGTGGACCCAGACCAGACGGAGAGCCAGAAACA TCCCTCTGGAGGAACTGCAAAGAAATCTGCAGTTCCACGCCTTCATCAGCTACAGCGAGCACGACAGCGCCTGGGTTAAA TCTGAACTGGTCCCCTACCTCGAGAAAGAAGATATCCAGATCTGCCTGCACGAGCGGAATTTCGTGCCCGGCAAGAGCAT TGTGGAAAACATCATCAACTGCATCGAGAAGTCTTATAAGTCCATCTTCGTGCTTTCTCCTAACTTCGTGCAGAGCGAGT GGTGCCACTACGAGCTGTACTTCGCCCACCACAACCTGTTCCATGAGGGCAGCAACAACCTGATCCTGATCCTGCTGGAA CCTATCCCCCAGAACAGCATCCCAAACAAGTACCACAAGCTGAAGGCCCTGATGACCCAGAGAACCTACCTGCAGTGGCC TAAGGAAAAGTCCAAGCGCGGCCTGTTTTGGGCTAATATCCGGGCCGCTTTTAACATGAAACTGACACTGGTGACCGAGA ACAACGACGTGAAGAGC IFNGR1-2-IGF1R (SEQ ID NO: 124)
ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCCTGATCATTGCCCTGCCTGTGGCCGTGCTGCTCATCGTGGGCGGCCTGGTGATCATGCTGTACGT GTTCCACCGGAAGCGGAACAACAGCAGACTGGGCAACGGAGTGCTGTACGCCAGCGTGAATCCTGAATACTTCAGCGCCG CTGATGTGTACGTGCCTGACGAGTGGGAGGTGGCCAGAGAGAAGATCACCATGTCTAGAGAATTGGGCCAAGGCAGCTTC GGCATGGTCTACGAGGGCGTCGCCAAGGGCGTTGTGAAAGACGAGCCTGAGACAAGAGTGGCCATCAAGACCGTGAACGA GGCCGCCTCCATGAGAGAGAGAATCGAGTTCCTGAATGAAGCCTCTGTGATGAAGGAGTTCAACTGCCACCACGTGGTCA GACTGCTGGGTGTTGTGTCTCAGGGCCAGCCCACCCTGGTGATCATGGAACTGATGACCCGCGGGGACCTTAAAAGCTAC CTGCGGAGCCTGAGACCTGAGATGGAAAACAACCCTGTGCTCGCCCCTCCTAGTCTGAGCAAGATGATCCAGATGGCCGG CGAGATCGCCGACGGCATGGCTTATCTGAACGCCAACAAATTCGTGCACAGAGATCTGGCAGCTAGAAACTGCATGGTGG CTGAAGATTTTACCGTGAAGATCGGAGATTTCGGAATGACACGGGACATCTACGAGACAGACTACTATAGAAAGGGCGGC AAGGGACTGCTGCCCGTGCGGTGGATGAGCCCTGAGAGCCTGAAGGACGGCGTGTTCACCACATACAGCGACGTGTGGTC CTTCGGCGTGGTGCTGTGGGAAATCGCCACCCTGGCCGAGCAACCTTACCAGGGCCTGTCTAATGAGCAGGTGCTGAGAT
TCGTGATGGAAGGCGGACTGCTGGATAAGCCTGACAACTGTCCTGACATGCTGTTCGAGCTGATGAGGATGTGCTGGCAG TACAACCCCAAGATGCGACCTTCTTTTCTGGAAATCATCTCTAGCATCAAAGAAGAGATGGAACCCGGCTTCCGGGAGGT GTCCTTCTACTACAGCGAGGAAAACAAGCTGCCTGAGCCCGAAGAACTGGACCTCGAGCCTGAGAATATGGAAAGCGTGC
6727-109858-02 CACTGGACCCCAGCGCCAGCAGCAGCAGCCTGCCACTGCCAGATAGACACAGCGGCCATAAGGCCGAGAACGGCCCTGGC CCCGGCGTGCTGGTCCTGCGGGCCAGCTTTGACGAGCGGCAGCCGTACGCTCACATGAACGGCGGAAGAAAGAACGAGAG AGCCCTGCCTCTGCCCCAGAGTTCCACCTGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGC AGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTC GCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGC CGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATA CAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTC ACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCA CAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCC CTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTAC GTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAA GCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGA GCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGCTGATCATTGCCCTGCCTGTGGCCGTG CTGCTCATCGTGGGCGGCCTGGTGATCATGCTGTACGTGTTCCACCGGAAGCGGAACAACAGCAGACTGGGCAACGGAGT
GCTGTACGCCAGCGTGAATCCTGAATACTTCAGCGCCGCTGATGTGTACGTGCCTGACGAGTGGGAGGTGGCCAGAGAGA AGATCACCATGTCTAGAGAATTGGGCCAAGGCAGCTTCGGCATGGTCTACGAGGGCGTCGCCAAGGGCGTTGTGAAAGAC GAGCCTGAGACAAGAGTGGCCATCAAGACCGTGAACGAGGCCGCCTCCATGAGAGAGAGAATCGAGTTCCTGAATGAAGC CTCTGTGATGAAGGAGTTCAACTGCCACCACGTGGTCAGACTGCTGGGTGTTGTGTCTCAGGGCCAGCCCACCCTGGTGA TCATGGAACTGATGACCCGCGGGGACCTTAAAAGCTACCTGCGGAGCCTGAGACCTGAGATGGAAAACAACCCTGTGCTC
GCCCCTCCTAGTCTGAGCAAGATGATCCAGATGGCCGGCGAGATCGCCGACGGCATGGCTTATCTGAACGCCAACAAATT CGTGCACAGAGATCTGGCAGCTAGAAACTGCATGGTGGCTGAAGATTTTACCGTGAAGATCGGAGATTTCGGAATGACAC GGGACATCTACGAGACAGACTACTATAGAAAGGGCGGCAAGGGACTGCTGCCCGTGCGGTGGATGAGCCCTGAGAGCCTG AAGGACGGCGTGTTCACCACATACAGCGACGTGTGGTCCTTCGGCGTGGTGCTGTGGGAAATCGCCACCCTGGCCGAGCA ACCTTACCAGGGCCTGTCTAATGAGCAGGTGCTGAGATTCGTGATGGAAGGCGGACTGCTGGATAAGCCTGACAACTGTC CTGACATGCTGTTCGAGCTGATGAGGATGTGCTGGCAGTACAACCCCAAGATGCGACCTTCTTTTCTGGAAATCATCTCT AGCATCAAAGAAGAGATGGAACCCGGCTTCCGGGAGGTGTCCTTCTACTACAGCGAGGAAAACAAGCTGCCTGAGCCCGA AGAACTGGACCTCGAGCCTGAGAATATGGAAAGCGTGCCACTGGACCCCAGCGCCAGCAGCAGCAGCCTGCCACTGCCAG ATAGACACAGCGGCCATAAGGCCGAGAACGGCCCTGGCCCCGGCGTGCTGGTCCTGCGGGCCAGCTTTGACGAGCGGCAG CCGTACGCTCACATGAACGGCGGAAGAAAGAACGAGAGAGCCCTGCCTCTGCCCCAGAGTTCCACCTGC IFNGR1tm-CSF2RB_IFNGR2tm-GMCSFRA (SEQ ID NO: 125) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT
GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCCG GTTCTGCGGCATCTACGGGTACAGGCTGCGGAGAAAGTGGGAGGAAAAGATCCCGAATCCTAGCAAGAGCCACCTGTTCC AGAACGGCTCTGCTGAACTGTGGCCTCCCGGAAGTATGAGCGCCTTCACCAGCGGCAGCCCACCTCACCAGGGCCCTTGG GGCAGCAGATTCCCCGAGCTGGAAGGCGTGTTTCCAGTGGGCTTCGGCGATAGCGAGGTGTCCCCTCTGACAATCGAGGA TCCTAAGCACGTGTGCGACCCTCCAAGCGGCCCTGATACAACCCCTGCTGCCAGCGACCTGCCCACCGAGCAGCCTCCCA GCCCTCAGCCTGGCCCTCCAGCCGCCTCTCATACCCCTGAGAAACAGGCCTCTAGCTTTGACTTCAACGGCCCCTACCTG GGTCCTCCACACAGCCGGAGCCTGCCCGACATCCTGGGCCAGCCTGAGCCTCCTCAGGAGGGCGGCAGCCAGAAGAGCCC TCCACCCGGATCTCTGGAATACCTGTGCCTGCCTGCCGGCGGCCAGGTGCAGCTGGTCCCTCTGGCCCAGGCTATGGGCC CCGGCCAGGCCGTGGAAGTGGAACGGAGACCTTCTCAGGGCGCCGCTGGCTCCCCGAGCCTGGAGAGCGGCGGCGGACCA GCTCCTCCTGCTCTGGGCCCTAGAGTGGGAGGCCAAGACCAGAAAGACAGCCCAGTGGCCATTCCTATGTCATCTGGCGA CACCGAGGACCCCGGCGTGGCCAGCGGCTACGTGTCTAGCGCCGATCTGGTGTTCACCCCTAACAGCGGCGCCAGCAGCG TGTCCCTCGTTCCTAGCCTGGGACTGCCTTCTGATCAAACACCCAGCCTGTGTCCTGGCCTGGCCAGCGGACCTCCCGGA GCCCCTGGACCAGTCAAATCCGGTTTCGAGGGCTACGTGGAACTGCCTCCAATCGAGGGCAGATCTCCTCGCTCCCCTAG AAACAACCCCGTGCCTCCCGAAGCCAAGTCTCCCGTGCTTAATCCTGGAGAGAGACCCGCCGACGTGTCCCCTACCAGCC CTCAACCCGAGGGCCTGCTGGTGCTGCAGCAGGTCGGCGACTACTGCTTCCTGCCTGGCCTGGGCCCCGGCCCGCTGAGC CTGAGAAGCAAGCCCTCTAGCCCCGGCCCTGGCCCCGAAATCAAGAACCTGGACCAGGCCTTTCAGGTGAAGAAACCACC TGGACAAGCTGTTCCTCAAGTGCCCGTGATCCAGCTGTTCAAGGCCCTGAAGCAGCAGGACTATCTGTCTCTGCCTCCCT GGGAAGTGAACAAGCCTGGCGAGGTGTGTAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAG GCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGC
CGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCG AGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACA GACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCAC
6727-109858-02 CGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACA GCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCT GGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGT GCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGC CTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGC AATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAG CCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCAAAAGATTCCTGAGAATCCAGAGACTGTTTCCACCTGTGCCCCAGA TCAAGGACAAGCTGAACGACAACCACGAGGTGGAAGATGAGATCATCTGGGAGGAGTTCACCCCTGAGGAAGGCAAGGGC TACCGGGAAGAGGTCCTGACAGTGAAGGAAATCACC IFNGR1tm-GMCSFRA_IFNGR2tm-CSF2RB (SEQ ID NO: 126) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC
AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT
GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAA AAGATTCCTGAGAATCCAGAGACTGTTTCCACCTGTGCCCCAGATCAAGGACAAGCTGAACGACAACCACGAGGTGGAAG ATGAGATCATCTGGGAGGAGTTCACCCCTGAGGAAGGCAAGGGCTACCGGGAAGAGGTCCTGACAGTGAAGGAAATCACC AGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCC TATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCC TGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCC CTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCAT GAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTA TGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAG CACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAG CAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGC AGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAG GCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGA TGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTT TCTTCCGCTTCTGCGGCATCTACGGCTACAGACTGAGAAGAAAGTGGGAGGAAAAGATCCCTAATCCTAGCAAGTCCCAC CTGTTCCAGAATGGCAGCGCCGAGCTGTGGCCTCCCGGTAGCATGAGTGCCTTTACCAGCGGCAGCCCTCCTCACCAGGG ACCTTGGGGCAGCAGATTCCCTGAACTGGAAGGCGTGTTCCCCGTGGGCTTCGGCGATAGCGAGGTCAGCCCCCTGACCA TCGAGGACCCTAAGCACGTGTGCGACCCCCCTTCAGGCCCTGACACAACACCTGCCGCCAGCGACCTGCCTACAGAGCAG CCTCCTAGCCCTCAGCCCGGACCACCTGCCGCTAGCCACACCCCTGAAAAACAGGCCTCTAGCTTCGACTTCAACGGCCC
TTACCTGGGCCCACCACATAGCCGGTCCCTGCCTGATATCCTGGGACAACCTGAGCCCCCTCAGGAGGGCGGCAGCCAGA AAAGCCCTCCACCCGGAAGCCTGGAATACCTGTGTCTGCCTGCTGGCGGACAGGTCCAGCTGGTGCCCCTCGCCCAGGCT ATGGGCCCTGGACAGGCTGTGGAAGTGGAAAGAAGGCCTTCTCAGGGCGCCGCCGGCAGCCCCTCCTTGGAGAGCGGCGG AGGCCCTGCCCCTCCCGCACTGGGCCCCAGAGTGGGCGGCCAGGACCAAAAAGACAGCCCTGTGGCCATCCCCATGAGCA GCGGCGACACCGAGGACCCTGGCGTGGCCTCTGGCTATGTGTCCTCCGCCGACCTGGTTTTCACCCCTAACAGCGGCGCC AGCAGCGTGTCTCTGGTGCCTTCCCTGGGCCTGCCTTCTGATCAAACACCTTCTCTGTGCCCCGGCCTGGCTAGCGGCCC TCCCGGAGCCCCTGGCCCCGTTAAGAGCGGATTTGAGGGCTACGTGGAACTGCCTCCAATCGAGGGCAGAAGCCCGCGGA GCCCCAGAAACAACCCTGTGCCGCCTGAGGCCAAGTCTCCCGTGCTGAACCCCGGCGAGCGGCCTGCCGATGTGTCCCCT ACCAGCCCTCAGCCTGAGGGCCTGCTGGTGCTGCAGCAGGTGGGCGATTACTGCTTCCTGCCTGGACTGGGCCCAGGCCC CCTGTCTCTGCGGTCTAAGCCCTCTAGCCCTGGACCAGGCCCTGAAATCAAGAACCTGGATCAGGCTTTTCAGGTGAAGA AACCTCCCGGCCAGGCCGTGCCCCAGGTCCCCGTGATTCAGCTGTTCAAGGCCCTGAAGCAGCAAGACTACCTCAGCCTG CCCCCGTGGGAAGTGAACAAGCCTGGCGAGGTGTGT IFNGR1tm-IL2RG_IFNGR2tm-IL2RB (SEQ ID NO: 127) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC
TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC
6727-109858-02 AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCGA ACGGACCATGCCTAGAATCCCAACACTGAAGAACCTGGAAGATCTCGTGACCGAGTACCACGGCAACTTCAGCGCCTGGA GCGGCGTGTCCAAGGGACTGGCCGAGAGCCTGCAGCCTGACTACAGCGAGAGACTGTGCCTGGTGTCTGAAATCCCCCCC AAGGGCGGAGCCCTGGGCGAGGGCCCCGGCGCTTCTCCATGTAATCAGCACAGCCCTTATTGGGCCCCTCCTTGCTACAC CCTGAAACCTGAGACAAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGG AGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCT GCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAG CTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGT TCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCT AGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGAC AATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTC TGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAG AAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTA CTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCT
ACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCCTGCTGTCTGTG CTGGCCGGCGCTTGTTTCTTCAATTGCAGAAATACCGGACCTTGGCTGAAGAAAGTGCTCAAGTGCAACACACCTGATCC TAGCAAGTTCTTCAGCCAGCTGAGCTCCGAGCACGGCGGAGATGTGCAGAAATGGCTGTCTAGCCCGTTCCCCAGCTCTT CTTTCAGCCCCGGCGGACTGGCCCCAGAGATCAGCCCTCTGGAAGTGCTGGAACGGGACAAGGTGACCCAGCTGCTGCTG CAGCAGGACAAGGTGCCTGAGCCTGCCTCTCTGAGCAGCAACCATAGCCTGACCAGCTGCTTTACCAACCAGGGCTACTT
TTTCTTCCACCTGCCTGATGCCCTGGAAATCGAGGCTTGTCAGGTGTACTTCACATACGACCCCTACAGCGAGGAAGATC CTGACGAGGGCGTGGCCGGCGCCCCTACCGGATCTAGCCCTCAGCCCCTGCAGCCACTGAGCGGCGAGGACGACGCATAC TGCACCTTCCCAAGCAGGGATGACCTGCTGCTGTTTAGCCCTTCTCTGCTCGGCGGCCCCTCCCCTCCATCAACAGCCCC TGGCGGCAGCGGCGCTGGCGAGGAAAGAATGCCTCCTAGCCTGCAAGAGCGGGTTCCTCGCGACTGGGACCCCCAGCCCC TGGGCCCTCCAACCCCTGGCGTGCCTGACCTGGTCGACTTCCAGCCCCCCCCCGAGCTGGTGCTGAGAGAGGCCGGGGAG GAAGTGCCCGATGCTGGCCCTAGAGAAGGCGTGTCCTTCCCTTGGTCCAGACCTCCTGGACAAGGCGAGTTCAGAGCCCT GAACGCCAGACTGCCCCTTAACACCGACGCCTATCTGAGCCTGCAAGAGCTGCAGGGCCAGGACCCTACACACCTG IFNGR1tm-IL3RA_IFNGR2tm-CSF2RB (SEQ ID NO: 128) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCCG GAGATACCTGGTGATGCAGAGACTGTTCCCTAGAATCCCCCACATGAAAGATCCTATCGGCGACAGCTTCCAGAACGACA
AGCTGGTCGTGTGGGAAGCCGGCAAGGCCGGACTGGAAGAGTGCCTGGTGACCGAGGTGCAAGTGGTGCAGAAGACAAGA GCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTAT GAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGA GCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTG AGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAG CATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGG ACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCAC TACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAG CCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGG TGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCC CAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGC CTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCT TCCGCTTCTGCGGCATCTACGGCTACAGACTGCGGAGAAAATGGGAGGAAAAGATCCCTAATCCTAGCAAGAGCCATCTG TTCCAGAACGGCAGCGCCGAGCTGTGGCCTCCTGGCTCCATGAGCGCTTTTACCAGCGGCAGCCCTCCCCACCAGGGCCC TTGGGGCAGCCGGTTCCCCGAGCTGGAAGGAGTGTTCCCTGTTGGCTTCGGCGATAGCGAGGTGTCCCCTCTGACAATCG AGGACCCCAAGCACGTGTGCGACCCTCCTAGCGGCCCTGATACCACCCCTGCTGCCAGCGACCTGCCTACAGAGCAGCCA CCAAGCCCTCAGCCTGGCCCTCCCGCCGCCAGCCACACCCCTGAGAAGCAGGCCAGCAGCTTCGACTTCAACGGCCCCTA CCTGGGACCACCACACAGCAGAAGCCTGCCCGACATCCTGGGCCAGCCCGAACCCCCCCAGGAGGGCGGCTCTCAGAAAT CTCCACCCCCTGGCAGCCTTGAGTACCTGTGTCTGCCCGCCGGCGGCCAGGTGCAGCTGGTGCCTCTGGCCCAGGCTATG GGCCCCGGCCAAGCCGTGGAAGTGGAAAGACGGCCTAGCCAGGGCGCTGCTGGCAGCCCTTCTCTGGAATCTGGAGGGGG
CCCTGCACCTCCAGCCCTGGGACCAAGAGTGGGCGGCCAGGATCAGAAGGACAGCCCCGTCGCCATCCCCATGAGCAGCG GCGACACCGAGGATCCCGGCGTGGCCTCTGGATACGTGTCCAGCGCCGACCTGGTGTTCACCCCTAATAGCGGAGCTTCT AGCGTGTCTCTGGTTCCTAGCCTGGGCCTGCCTTCTGATCAAACACCTTCCCTCTGTCCTGGCCTGGCCTCCGGACCGCC
6727-109858-02 AGGCGCCCCTGGCCCTGTGAAGAGCGGATTTGAGGGATATGTGGAACTGCCTCCTATTGAGGGCAGAAGCCCGCGGAGCC CTAGGAACAACCCCGTGCCTCCTGAGGCCAAGTCTCCCGTGCTGAACCCTGGAGAGAGACCTGCTGATGTGAGCCCTACC TCCCCTCAGCCTGAGGGCCTGCTGGTCCTGCAGCAAGTGGGCGACTACTGCTTCCTGCCTGGACTGGGCCCCGGCCCCCT CAGCCTGAGATCTAAGCCCTCCTCTCCTGGCCCTGGCCCAGAAATCAAGAACCTGGACCAGGCCTTCCAGGTGAAAAAGC CTCCTGGACAAGCCGTGCCCCAGGTGCCCGTGATCCAGCTGTTTAAGGCCCTGAAGCAGCAGGACTACCTGAGCCTGCCT CCTTGGGAAGTGAACAAGCCTGGAGAAGTCTGC IFNGR1tm-TSLPR_IFNGR2tm-IL7RA (SEQ ID NO: 129) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC
TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAA ACTGTGGCGGGTGAAGAAATTCCTGATCCCCAGCGTGCCAGATCCTAAGTCCATCTTCCCCGGCCTGTTCGAGATCCACC
AGGGCAATTTCCAGGAGTGGATCACCGACACCCAGAACGTGGCCCACCTGCACAAGATGGCCGGCGCCGAGCAGGAGAGC GGCCCTGAGGAACCTCTCGTGGTCCAGCTGGCCAAGACCGAGGCTGAAAGCCCTAGAATGCTGGACCCCCAGACAGAGGA AAAGGAAGCTTCTGGCGGCAGCCTGCAGCTGCCTCATCAGCCTCTGCAAGGCGGAGATGTGGTTACAATCGGCGGATTTA CCTTCGTGATGAACGACAGAAGCTACGTGGCCCTGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTG AAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGT GTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACA ACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAG TATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGA CTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCAC TGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTG ACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTA CTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACC TGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCAC CTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGAC CTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCAAAAAACGGATCAAGCCTATCGTGTGGCCAAGCCTGCCCG ACCATAAGAAGACCCTGGAACACCTGTGCAAGAAGCCCAGAAAGAACCTGAACGTGTCTTTTAACCCCGAGAGCTTCCTG GACTGTCAGATCCACAGAGTCGACGACATCCAGGCTAGAGACGAGGTGGAAGGCTTCCTGCAGGACACCTTCCCTCAGCA GCTGGAAGAGTCCGAGAAGCAGCGGCTGGGCGGAGATGTGCAGAGCCCTAACTGCCCCAGCGAGGACGTGGTTATCACCC CTGAGAGCTTTGGCAGAGATAGCAGCCTCACCTGTCTGGCCGGCAACGTGTCCGCCTGCGACGCCCCTATCCTGTCTTCT AGCAGAAGCCTGGATTGCCGGGAATCCGGCAAGAACGGCCCCCACGTGTACCAAGATCTGCTGCTGAGCCTGGGCACAAC
AAACTCTACACTGCCTCCTCCATTCAGCCTTCAAAGCGGCATCCTGACCCTGAATCCTGTGGCCCAGGGCCAGCCTATTC TGACCAGCCTGGGATCTAATCAGGAGGAAGCCTACGTGACCATGAGCAGCTTCTACCAGAACCAG IFNGR1tm-IL2RB_IFNGR2tm-IL2RG (SEQ ID NO: 130) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAA TTGCAGAAACACCGGTCCCTGGCTGAAAAAGGTGCTGAAGTGCAACACCCCTGACCCTAGCAAGTTCTTCAGCCAGCTGA GCAGCGAGCACGGCGGCGACGTGCAGAAATGGCTGTCTAGCCCGTTCCCTTCTAGCAGCTTTTCCCCAGGCGGCCTGGCC CCTGAGATCAGCCCCCTGGAAGTGCTGGAACGGGACAAGGTGACCCAGCTGCTGCTGCAGCAGGACAAGGTGCCCGAGCC TGCCAGCCTGAGCTCCAACCATAGCCTGACCAGCTGCTTCACAAACCAGGGCTACTTTTTCTTCCACCTGCCCGACGCCC TGGAAATCGAGGCTTGTCAGGTGTACTTCACCTACGACCCCTACAGCGAAGAGGACCCCGACGAGGGCGTGGCCGGCGCC CCTACAGGCAGCAGCCCCCAGCCTCTGCAACCTCTGAGCGGCGAAGATGATGCCTACTGCACCTTCCCCAGCAGAGATGA
CCTGCTGCTGTTCAGCCCATCTCTGCTTGGAGGCCCTAGCCCTCCTTCCACCGCCCCTGGAGGCTCTGGCGCTGGAGAGG AAAGGATGCCTCCTTCTCTGCAGGAGCGGGTGCCCAGAGACTGGGACCCTCAGCCTCTGGGCCCTCCAACACCTGGCGTG CCTGATCTGGTGGACTTCCAGCCCCCCCCCGAGCTGGTCCTGCGGGAAGCCGGCGAGGAAGTGCCAGACGCCGGACCTAG
6727-109858-02 AGAGGGCGTTTCTTTTCCTTGGTCCAGACCTCCAGGACAGGGCGAGTTCAGAGCCCTGAATGCCAGACTGCCTCTCAACA CAGATGCTTATCTGTCCCTCCAAGAGCTGCAAGGCCAGGATCCTACCCACCTGAGAGCCAAGAGGAGCGGCAGCGGCGCC ACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCT GCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACC CCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTG TACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGAT CACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGA GAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCC CCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATC TACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACT CTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAAC ATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTAT CCTGATATCTGTGGGGACCTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCGAACGGACCATGCCTAGAATCC CCACACTGAAGAACCTGGAAGATCTGGTGACAGAGTACCACGGCAATTTCAGCGCCTGGTCTGGCGTGTCCAAGGGCCTG
GCCGAGAGCCTGCAGCCTGACTACAGCGAGAGACTGTGCCTCGTGTCTGAGATCCCTCCAAAGGGAGGAGCTCTGGGCGA GGGCCCCGGCGCCAGCCCCTGCAACCAGCACAGCCCATATTGGGCCCCTCCTTGTTACACCCTGAAACCTGAAACC IFNGR1tm-IL9R_IFNGR2tm-IL2RG (SEQ ID NO: 131) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC
TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAA ACTGTCTCCAAGAGTGAAGCGGATCTTCTACCAGAACGTGCCTAGCCCTGCCATGTTCTTCCAACCTCTGTACAGCGTGC ACAACGGCAATTTCCAGACCTGGATGGGCGCCCACGGCGCCGGCGTGCTGCTGTCTCAGGACTGCGCCGGAACCCCTCAG GGAGCCCTCGAACCCTGCGTGCAGGAGGCCACCGCCCTGCTGACCTGTGGCCCCGCCAGACCTTGGAAGAGCGTGGCCCT GGAAGAAGAACAGGAGGGCCCTGGCACAAGACTGCCCGGAAATCTGAGCTCTGAGGACGTGCTGCCTGCTGGCTGTACCG AGTGGCGGGTTCAAACCCTGGCCTATCTGCCCCAGGAGGACTGGGCCCCTACAAGCCTGACAAGGCCCGCTCCTCCTGAT AGCGAGGGCAGCAGAAGCTCCAGCAGCAGCAGCTCTTCCAACAACAACAACTACTGCGCCCTGGGCTGCTACGGCGGCTG GCACCTGAGCGCCCTGCCTGGCAACACACAGAGCTCCGGCCCTATCCCCGCTCTTGCTTGTGGCCTGTCCTGCGACCACC AGGGCCTGGAAACCCAGCAGGGCGTCGCCTGGGTGCTGGCCGGCCACTGCCAGAGACCAGGACTGCACGAGGATCTGCAG GGAATGCTGCTGCCATCTGTGCTGAGCAAGGCCCGGAGCTGGACCTTTAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAA TTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGC TACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAG
ATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCA AGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCG CCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCC GAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGA GAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAG CCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATT AGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTT CCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGA TATCTGTGGGGACCTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCGAACGGACCATGCCTAGAATCCCAACA CTGAAGAACCTGGAAGATCTGGTGACCGAGTACCACGGCAACTTCAGCGCCTGGAGCGGCGTGTCCAAGGGACTGGCCGA GAGCCTGCAGCCTGACTACAGCGAGAGACTGTGCCTCGTGTCTGAAATCCCCCCCAAGGGCGGAGCCCTGGGCGAGGGCC CCGGCGCTTCTCCATGTAATCAGCACAGCCCTTATTGGGCCCCTCCTTGCTACACCCTGAAACCTGAGACA IFNGR1tm-IL7RA_IFNGR2tm-IL2RG (SEQ ID NO: 132) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC
TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC
6727-109858-02 AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAA AAAGCGGATCAAGCCCATCGTGTGGCCCAGCCTTCCAGATCACAAGAAAACACTGGAACACCTGTGCAAGAAGCCTAGAA AGAATCTGAACGTGTCCTTTAACCCCGAGAGCTTTCTGGATTGTCAGATCCACAGAGTGGACGACATCCAGGCCAGAGAC GAGGTGGAAGGCTTCCTGCAGGACACCTTCCCCCAGCAGCTGGAAGAGTCTGAGAAGCAGCGGCTGGGCGGAGATGTGCA GAGCCCCAACTGCCCTAGCGAGGACGTTGTGATCACCCCTGAGAGCTTCGGCAGAGATAGCTCTCTCACATGCCTGGCCG GCAACGTCTCCGCCTGCGACGCCCCTATCCTGTCTTCTTCTAGAAGCCTGGACTGTCGGGAATCCGGAAAGAACGGCCCT CATGTGTACCAAGACCTGCTGCTGAGCCTGGGCACCACCAACAGCACCCTGCCTCCTCCATTCAGCCTGCAAAGCGGCAT CCTGACCCTGAATCCTGTGGCTCAGGGCCAGCCTATTCTGACAAGCCTGGGCAGCAACCAGGAGGAAGCCTACGTGACCA TGAGCAGCTTCTACCAGAACCAGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGA GATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGC CGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGG TGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCT AAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGC CAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCT
GGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAG GGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTA CTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCC GGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATC AGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCCTGCT
GTCTGTGCTGGCCGGCGCTTGTTTCTTCGAAAGAACAATGCCTAGAATCCCCACCCTCAAGAACCTGGAAGATCTGGTGA CCGAGTACCACGGAAATTTCAGCGCCTGGAGCGGCGTGTCCAAGGGCCTGGCCGAGAGCCTGCAGCCTGACTACAGCGAG CGGCTGTGCCTGGTGTCTGAAATCCCTCCAAAGGGAGGCGCCCTGGGCGAGGGCCCCGGCGCTTCTCCATGCAACCAGCA CAGCCCCTATTGGGCCCCTCCTTGTTACACCCTGAAACCTGAGACA IFNGR1-GMCSFRA_IFNGR2-CSF2RB (SEQ ID NO: 133) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAA TCTGGGCAGCGTGTACATCTACGTGCTGCTGATCGTTGGAACACTGGTGTGCGGCATCGTCCTCGGCTTCCTGTTTAAGC GGTTCCTGAGAATCCAGAGACTGTTCCCCCCAGTGCCTCAGATCAAGGACAAGCTGAACGACAACCACGAGGTGGAAGAT GAGATTATCTGGGAGGAGTTCACCCCTGAGGAAGGCAAAGGCTACAGAGAGGAAGTGCTGACCGTGAAGGAAATCACCAG AGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTA
TGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTG AGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCT GAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGA GCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATG GACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCA CTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCA GCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAG GTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGC CCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATG CCTCAACAGAGCTGCAACAGGTGCTGGCCCTGATCGTGATCTTCCTGACAATCGCCGTGCTGCTGGCCCTGAGATTCTGC GGCATCTACGGCTATAGACTGAGACGGAAGTGGGAGGAAAAGATCCCTAATCCTTCTAAGAGCCATCTGTTTCAGAACGG CAGCGCCGAGCTGTGGCCTCCTGGCAGCATGTCTGCCTTCACCAGCGGCAGCCCACCTCACCAGGGCCCTTGGGGATCTA GGTTCCCTGAACTGGAAGGAGTGTTCCCCGTCGGCTTCGGCGACAGCGAGGTGTCCCCCCTGACAATCGAGGACCCCAAG CACGTGTGCGACCCTCCTTCTGGCCCTGACACAACCCCTGCCGCCTCTGATCTGCCCACCGAGCAGCCTCCTAGCCCACA GCCAGGACCCCCTGCTGCCAGCCACACCCCTGAGAAACAGGCAAGCAGCTTCGACTTCAACGGCCCCTACCTGGGCCCAC CCCACAGCAGAAGCCTGCCTGATATCCTGGGACAGCCAGAGCCTCCCCAGGAGGGCGGCAGCCAGAAATCTCCTCCTCCC GGCAGCCTGGAATACCTGTGCCTGCCTGCCGGCGGACAAGTCCAGCTGGTGCCCCTGGCTCAGGCTATGGGCCCCGGCCA GGCCGTGGAAGTGGAACGGAGACCCTCCCAGGGCGCCGCTGGCAGTCCCAGCCTCGAGAGCGGCGGAGGCCCTGCCCCTC CCGCCCTGGGCCCACGGGTGGGCGGCCAGGACCAAAAGGACTCACCTGTGGCCATCCCCATGAGCTCTGGCGATACCGAG GATCCTGGCGTGGCCTCTGGCTACGTGTCCAGCGCCGACCTGGTCTTTACCCCTAACAGCGGCGCCAGCAGCGTGTCCCT
CGTGCCTAGCCTGGGCCTGCCTAGCGACCAGACCCCATCTCTGTGTCCTGGCCTTGCTAGCGGACCTCCTGGGGCCCCTG GCCCAGTGAAGAGCGGATTCGAGGGCTACGTGGAACTGCCTCCAATCGAGGGAAGATCTCCTAGAAGCCCCCGGAACAAC CCCGTGCCCCCCGAGGCCAAGAGCCCCGTGCTGAACCCTGGGGAGAGACCTGCTGATGTGTCTCCTACAAGCCCGCAACC
6727-109858-02 TGAAGGCCTGCTGGTGCTGCAGCAGGTGGGCGACTACTGCTTCCTGCCTGGACTGGGCCCTGGCCCCCTGTCTCTGCGCT CCAAACCTTCCAGCCCCGGGCCTGGTCCTGAAATCAAGAATCTGGACCAGGCTTTTCAGGTGAAAAAGCCCCCTGGCCAA GCCGTGCCTCAAGTGCCTGTTATTCAGCTGTTCAAGGCCCTGAAGCAGCAGGACTACCTGAGCCTGCCACCCTGGGAAGT GAACAAGCCTGGCGAGGTTTGT IFNGR1-IL2RG_IFNGR2-IL2RB (SEQ ID NO: 134) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT
GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCGT CGTGATCTCTGTGGGCAGCATGGGCCTGATCATCAGCCTGCTGTGCGTGTACTTCTGGCTGGAAAGAACCATGCCTAGAA TCCCCACCCTGAAAAACCTGGAAGATCTGGTGACAGAGTACCACGGCAATTTCAGCGCCTGGTCCGGCGTGTCCAAGGGC CTGGCCGAGAGCCTCCAGCCTGACTACAGCGAGCGGCTGTGCCTGGTGTCTGAGATCCCTCCAAAGGGAGGAGCTCTGGG
CGAGGGCCCCGGCGCCAGCCCTTGCAACCAGCACAGCCCCTACTGGGCCCCTCCTTGTTATACACTGAAGCCAGAAACCA GAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCT ATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCT GAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCC TGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATG AGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTAT GGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGC ACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGC AGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCA GGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGG CCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGAT GCCTCAACAGAGCTGCAACAGATCCCCTGGCTCGGCCATCTGCTGGTGGGCCTGAGCGGAGCCTTCGGCTTCATCATCCT GGTGTACCTGCTGATCAACTGCAGAAACACCGGCCCTTGGCTGAAAAAGGTGCTGAAGTGCAACACACCTGATCCTTCTA AGTTCTTTTCTCAGCTGAGCTCTGAGCACGGCGGCGACGTGCAGAAGTGGCTGTCTAGCCCATTCCCAAGCTCTTCTTTT AGCCCTGGAGGACTGGCCCCTGAGATTAGCCCCCTGGAAGTGCTGGAACGGGACAAAGTGACCCAGCTGCTGCTGCAGCA GGACAAGGTGCCAGAGCCTGCCAGCCTGAGCAGCAACCACAGCCTGACCAGCTGCTTTACCAACCAGGGTTATTTCTTCT TCCACCTGCCTGACGCCCTGGAAATCGAGGCTTGTCAGGTGTACTTTACCTACGACCCCTACAGCGAGGAAGATCCTGAC GAGGGCGTGGCCGGCGCCCCAACAGGCTCTTCCCCACAGCCTCTGCAACCTCTGAGCGGCGAAGATGACGCTTACTGCAC CTTCCCTAGCAGAGATGATCTGCTGCTGTTCTCCCCCAGCCTGCTGGGCGGCCCTTCCCCTCCAAGCACCGCCCCTGGCG GCAGCGGCGCTGGAGAAGAGCGGATGCCTCCTAGCCTGCAGGAGAGGGTGCCTAGAGACTGGGACCCCCAGCCCCTCGGC
CCCCCCACACCTGGCGTTCCTGACCTGGTCGACTTCCAGCCTCCTCCTGAGCTGGTGCTGAGAGAAGCCGGAGAAGAGGT GCCCGACGCCGGCCCCAGAGAGGGCGTGTCCTTCCCCTGGTCCCGCCCCCCTGGACAAGGCGAGTTCCGGGCCCTGAATG CCAGACTGCCCCTTAATACCGACGCCTACCTGAGCCTGCAAGAGCTGCAGGGCCAGGATCCTACACACCTG IFNGR1-IL6RA_IFNGR2-GP130 (SEQ ID NO: 135) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAC ATTTCTGGTCGCCGGCGGCAGCCTCGCCTTCGGCACCCTGCTGTGCATCGCCATCGTGCTGAGATTCAAGAAAACCTGGA AGCTGCGGGCCCTGAAGGAAGGCAAGACAAGCATGCACCCTCCTTACAGCCTGGGACAGCTGGTGCCCGAGCGGCCTAGA CCTACCCCTGTGCTGGTGCCTCTGATCAGCCCTCCAGTGTCCCCATCTAGCCTGGGCTCTGATAATACCAGCAGCCACAA CCGGCCCGACGCTAGAGATCCTAGAAGCCCCTACGACATCTCCAACACCGACTACTTCTTCCCCAGAAGAGCCAAGAGGA GCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACA
CTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCC TGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCA CCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTG
6727-109858-02 AACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGT CACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACG TGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGAC ATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACC TTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCT GGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAG CTGCAACAGGCTATCGTGGTGCCCGTGTGCCTGGCCTTCCTGCTGACCACCCTGCTGGGTGTGCTGTTTTGCTTCAACAA GCGGGACCTGATCAAGAAGCACATCTGGCCTAACGTGCCTGATCCTAGCAAGTCCCACATCGCCCAGTGGAGCCCTCACA CACCCCCCAGACACAACTTCAATTCCAAGGACCAGATGTACTCCGACGGCAACTTCACAGACGTGAGCGTGGTCGAAATC GAGGCCAATGATAAGAAACCTTTTCCTGAGGACCTGAAAAGCCTGGACCTGTTCAAGAAGGAAAAGATCAACACCGAAGG CCACTCTAGCGGAATTGGAGGCTCTTCTTGTATGAGCAGCTCCAGACCTAGCATCAGCAGCAGCGATGAGAACGAAAGCA GCCAGAACACCAGCAGCACCGTGCAGTACAGCACAGTTGTGCACAGCGGCTATAGACACCAGGTGCCATCTGTGCAGGTG TTCAGCAGGTCCGAGTCCACCCAGCCTCTGCTGGACAGCGAGGAAAGACCCGAGGACCTCCAGCTGGTGGACCACGTGGA CGGCGGAGATGGCATCCTGCCCAGACAGCAATACTTCAAACAAAACTGCAGCCAACACGAGAGCTCTCCAGACATCTCTC
ATTTCGAGCGGTCTAAGCAGGTCAGCAGCGTGAACGAGGAAGATTTCGTGCGGCTGAAGCAGCAGATCTCTGATCACATC AGCCAGAGCTGCGGCAGCGGACAGATGAAAATGTTCCAGGAGGTGTCCGCCGCCGACGCCTTTGGCCCTGGCACCGAGGG CCAGGTCGAGAGATTCGAAACCGTGGGCATGGAAGCCGCTACAGACGAGGGCATGCCTAAGAGCTACCTGCCTCAGACCG TGCGCCAGGGCGGCTACATGCCCCAG
IFNGR1-IL11RA_IFNGR2-GP130 (SEQ ID NO: 136) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTC CCTGGGCATCCTGAGCTTCCTGGGCCTCGTGGCCGGCGCCCTGGCCCTGGGACTGTGGCTGAGACTGCGGAGAGGCGGCA AGGACGGCAGCCCAAAGCCTGGCTTCCTGGCTTCTGTGATCCCCGTGGATAGACGGCCTGGAGCCCCTAACCTGAGAGCC AAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAG GCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCC AGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGC AATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCAT CGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACT TCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTAC CGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCC
CTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGA AGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAG CTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTC AACAGAGCTGCAACAGGCTATCGTGGTGCCCGTGTGCCTGGCCTTTCTGCTGACAACCCTGCTCGGCGTGCTGTTCTGCT TCAACAAGCGGGACCTGATCAAGAAGCACATTTGGCCTAACGTGCCTGATCCTTCTAAGTCCCACATCGCCCAATGGTCC CCTCACACCCCTCCAAGACACAACTTTAACAGCAAGGACCAGATGTACAGCGACGGAAATTTCACCGACGTGTCTGTGGT GGAAATCGAGGCCAACGACAAGAAACCCTTCCCCGAGGACCTGAAAAGCCTGGATCTGTTTAAGAAGGAAAAGATCAACA CCGAAGGCCACAGCTCTGGCATCGGTGGCAGCTCTTGTATGAGCTCTTCCAGACCTAGCATCTCTAGCAGCGACGAGAAC GAAAGTAGCCAGAACACATCCTCTACCGTGCAATACAGCACAGTGGTCCACAGCGGCTATAGACACCAGGTTCCAAGCGT GCAGGTGTTCAGCAGAAGCGAGAGCACCCAGCCTCTGCTGGACAGCGAGGAAAGACCCGAGGATCTGCAGCTGGTGGACC ACGTCGACGGCGGAGATGGCATCCTGCCTAGACAGCAATACTTCAAACAGAATTGCAGCCAACACGAGAGCAGCCCTGAC ATCAGCCACTTCGAGCGGAGCAAGCAGGTGTCCAGCGTGAACGAGGAAGATTTCGTGCGGCTGAAGCAGCAGATCTCTGA TCATATCAGCCAGAGCTGCGGCAGCGGACAGATGAAAATGTTCCAGGAGGTGTCCGCCGCCGACGCCTTCGGCCCTGGCA CCGAGGGCCAGGTCGAGAGATTCGAGACAGTGGGCATGGAAGCCGCTACAGACGAAGGCATGCCCAAGAGCTACCTGCCC CAGACCGTGCGCCAGGGCGGATACATGCCTCAG IFNGR1-OSMRB_IFNGR2-GP130 (SEQ ID NO: 137) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC
AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC
6727-109858-02 TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCCT GCTGCTGGGCATGATCGTGTTCGCCGTGATGCTGAGCATCCTGAGCCTGATCGGCATCTTTAACCGGAGCTTCAGAACCG GAATCAAAAGAAGGATCCTGCTGCTGATCCCTAAGTGGCTGTACGAGGATATCCCTAACATGAAAAACAGCAACGTGGTG AAGATGCTGCAGGAGAACTCTGAACTGATGAACAACAATTCTAGCGAGCAGGTGCTGTATGTGGATCCTATGATCACAGA GATCAAGGAAATCTTCATCCCAGAGCACAAGCCTACCGACTACAAAAAGGAAAACACAGGCCCTCTGGAAACCCGGGACT ACCCCCAGAATAGCCTGTTCGACAACACAACCGTGGTCTACATCCCTGATCTGAATACCGGCTACAAGCCTCAGATTAGC AACTTCCTGCCTGAGGGCAGCCACCTGTCCAACAACAACGAGATTACATCTCTGACCCTGAAGCCACCTGTGGACTCCCT GGACAGCGGCAACAACCCCAGACTGCAAAAGCACCCTAATTTTGCCTTCAGCGTGTCCAGCGTTAACTCCCTGTCTAATA CAATCTTTCTGGGCGAGCTGAGTCTGATCCTCAACCAGGGCGAGTGCAGCAGCCCCGACATCCAGAACAGCGTGGAAGAG GAAACCACCATGCTGCTGGAAAACGACAGCCCTTCTGAGACAATCCCCGAGCAGACCCTGCTGCCCGATGAGTTCGTGTC TTGTCTGGGAATCGTGAACGAGGAACTCCCTAGCATCAACACCTACTTCCCCCAGAATATCCTGGAGAGCCATTTCAACA
GAATCAGCCTGCTGGAAAAGAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGAT GTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGC AGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGC TCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAG TGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAG
CCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGG TGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGC TCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTG GGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGG TGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGC TGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGCTATCGTGGTCCCTGTGTGCCTGGCCTTTCTGCTGAC CACCCTGCTGGGCGTGCTGTTTTGCTTCAACAAGAGAGATCTGATCAAGAAGCACATTTGGCCCAACGTGCCCGACCCCA GCAAAAGCCACATCGCCCAGTGGAGCCCCCACACCCCTCCTAGGCACAACTTCAATAGCAAGGACCAGATGTACTCCGAC GGCAACTTTACAGACGTGTCTGTCGTGGAAATCGAAGCCAACGACAAGAAACCTTTCCCCGAGGATCTGAAAAGCCTGGA CCTGTTCAAGAAAGAGAAGATCAACACAGAAGGCCACAGCTCTGGCATCGGCGGATCTTCTTGTATGAGCAGCTCCAGAC CTAGCATCAGCTCATCTGATGAGAACGAGAGCAGCCAGAATACCAGCAGCACCGTGCAGTACAGCACCGTGGTGCACTCT GGATATAGACACCAGGTCCCATCTGTGCAGGTTTTCAGCAGAAGCGAGTCTACCCAGCCTCTGCTCGATTCTGAGGAACG GCCTGAGGACCTGCAGCTGGTGGACCACGTGGATGGCGGCGACGGAATCCTGCCTAGACAGCAATACTTCAAGCAGAACT GCAGCCAGCACGAGAGCTCCCCTGACATCAGCCATTTCGAGCGCAGCAAGCAGGTGTCCAGCGTGAACGAGGAAGATTTC GTGCGGCTGAAGCAACAAATCTCCGACCACATCAGCCAGAGCTGCGGCAGCGGCCAGATGAAGATGTTCCAGGAGGTGTC CGCCGCCGACGCCTTCGGCCCAGGAACAGAGGGCCAGGTGGAAAGATTCGAGACAGTGGGCATGGAAGCTGCCACCGACG AAGGCATGCCTAAGAGCTACCTGCCTCAGACCGTGCGGCAGGGCGGCTACATGCCCCAG IFNGR1-IL10RA_IFNGR2-IL10RB (SEQ ID NO: 138) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC
TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCGT TATCATCTTCTTCGCCTTCGTGCTGCTGCTGAGCGGAGCTCTGGCCTACTGCCTGGCACTGCAGCTGTACGTGCGGAGAA GAAAGAAACTGCCTAGCGTGCTGCTGTTCAAGAAGCCCAGCCCTTTCATCTTTATCAGCCAGAGACCTTCTCCTGAGACC CAGGACACCATCCACCCTCTGGATGAGGAAGCCTTCCTGAAGGTGTCCCCCGAGCTGAAGAACCTGGACCTGCACGGCTC TACCGACAGCGGATTTGGCAGCACAAAGCCTTCCCTGCAAACAGAGGAACCACAGTTCCTGCTGCCTGATCCCCACCCCC AGGCCGACCGGACCCTGGGCAATCGGGAACCTCCAGTGCTGGGCGACTCTTGCAGCTCCGGCTCCAGCAACAGCACCGAT TCTGGCATCTGCCTGCAGGAGCCCAGCCTGTCTCCTAGCACCGGACCTACCTGGGAGCAGCAGGTGGGCAGCAACAGTAG AGGCCAAGACGACAGCGGCATCGACCTGGTGCAGAATAGCGAGGGCAGGGCCGGCGATACACAGGGCGGATCTGCCCTGG GCCACCACAGCCCTCCTGAGCCTGAGGTGCCTGGCGAGGAAGATCCTGCCGCCGTGGCCTTTCAGGGATATCTGAGACAG ACCAGATGCGCCGAGGAGAAGGCCACAAAGACCGGATGTCTGGAAGAAGAGAGCCCCCTGACCGACGGCCTCGGCCCTAA GTTCGGCAGATGTCTGGTGGACGAGGCTGGCCTCCATCCCCCCGCCCTGGCTAAAGGCTACCTGAAACAGGATCCTCTGG AAATGACCCTGGCCAGCTCTGGAGCCCCAACAGGTCAATGGAACCAGCCTACAGAGGAATGGTCACTGCTGGCCCTGAGC
AGCTGCAGCGATCTCGGCATTAGCGACTGGAGCTTCGCCCACGACCTGGCTCCACTGGGCTGCGTGGCCGCTCCAGGCGG CCTGCTTGGCTCCTTCAACAGCGACCTGGTCACCCTCCCCCTGATCAGCAGCCTGCAGAGCAGTGAAAGAGCCAAGAGGA GCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACA
6727-109858-02 CTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCC TGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCA CCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTG AACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGT CACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACG TGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGAC ATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACC TTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCT GGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAG CTGCAACAGTGGATGGTCGCCGTGATCCTGATGGCCAGCGTGTTTATGGTGTGCCTGGCTCTGCTGGGATGTTTTGCCCT GCTGTGGTGCGTGTACAAGAAAACCAAGTACGCCTTCAGCCCTAGAAACAGCCTGCCTCAACACCTGAAGGAGTTCCTGG GCCATCCTCACCACAACACACTGCTCTTCTTCTCCTTCCCCCTGTCTGATGAAAACGACGTGTTCGACAAGCTGTCTGTG ATCGCCGAGGACAGCGAGTCCGGCAAGCAGAATCCTGGAGATAGCTGCAGCCTGGGCACCCCTCCAGGCCAGGGCCCCCA GAGC IFNGR1-IL22R_IFNGR2-IL20RB (SEQ ID NO: 139) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC
AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTA CAGCTTCAGCGGCGCCTTCCTGTTCAGCATGGGCTTCCTGGTCGCCGTGCTGTGCTACCTGAGCTATAGATACGTGACCA AGCCTCCAGCCCCTCCTAACAGCCTGAACGTGCAGCGGGTGCTGACATTCCAGCCCCTGCGCTTCATCCAGGAGCACGTG CTGATCCCCGTTTTTGATCTGTCTGGCCCAAGCAGCCTGGCTCAGCCCGTGCAATACTCACAGATTAGAGTGTCCGGACC TAGAGAGCCTGCCGGCGCACCACAGAGACACTCTCTGAGCGAGATCACATACCTGGGCCAGCCTGATATCAGCATCCTGC AGCCTAGCAACGTGCCTCCTCCGCAGATCCTGAGCCCTCTGAGCTACGCCCCTAATGCCGCCCCTGAAGTGGGCCCTCCA TCCTACGCCCCCCAGGTGACCCCTGAGGCCCAGTTCCCCTTCTACGCCCCCCAGGCCATCAGCAAGGTGCAGCCCTCTAG CTATGCCCCACAAGCTACACCAGACTCCTGGCCCCCTAGCTACGGTGTGTGTATGGAAGGCAGCGGCAAGGACAGCCCCA CCGGCACCCTGAGCAGCCCTAAGCACCTGCGGCCTAAGGGCCAGCTGCAAAAGGAACCTCCAGCTGGCAGCTGCATGCTG GGCGGACTGTCCCTGCAGGAGGTCACCAGCCTGGCTATGGAGGAATCTCAGGAGGCCAAGTCCCTCCATCAGCCTCTGGG AATCTGCACCGACCGGACCTCTGATCCTAACGTGCTGCACAGCGGAGAAGAGGGAACACCTCAATACCTGAAGGGCCAGC TGCCTCTTCTGTCTAGCGTGCAGATCGAGGGCCACCCCATGAGCCTGCCCCTGCAGCCTCCTTCTAGACCCTGCAGCCCT TCTGACCAGGGCCCTAGCCCCTGGGGCCTGCTGGAAAGCCTGGTGTGTCCTAAAGACGAGGCTAAAAGCCCCGCCCCCGA GACAAGCGACCTGGAACAGCCTACCGAGCTGGACTCTCTCTTTAGAGGCCTGGCCCTGACCGTGCAGTGGGAGTCTAGAG
CCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATG AGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAG CCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGA GCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGC ATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGA CTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACT ACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGC CCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGT GAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCC AGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCC TCAACAGAGCTGCAACAGGTTCTGGCCCTGTTCGCCTTCGTGGGCTTCATGCTGATCCTGGTGGTGGTCCCCCTGTTTGT GTGGAAGATGGGCAGACTGCTCCAGTACAGCTGCTGCCCTGTGGTGGTGCTGCCTGATACCCTGAAGATCACCAACAGCC CACAGAAACTGATCTCTTGTAGACGGGAAGAGGTGGACGCCTGCGCTACAGCCGTGATGAGCCCTGAGGAACTGCTGAGA GCCTGGATCTCC IFNGR1-IL20RA_IFNGR2-IL20RB (SEQ ID NO: 140) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG
CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT
6727-109858-02 CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCAT TATCTTTTGGTACGTGCTGCCTGTGTCCATCACCGTTTTCCTGTTCAGCGTGATGGGCTATAGCATCTACCGGTACATCC ACGTGGGCAAAGAGAAGCACCCCGCTAATCTGATTCTGATCTACGGCAACGAGTTCGACAAAAGATTCTTCGTGCCAGCT GAAAAGATCGTGATCAACTTCATCACCCTGAACATCAGCGACGACTCTAAGATCAGCCACCAGGACATGAGCCTGCTGGG CAAGAGCTCCGATGTGTCCAGCCTGAACGACCCCCAACCTTCTGGCAACCTGAGACCTCCTCAGGAGGAAGAAGAGGTCA AGCACCTGGGCTACGCCTCTCATCTGATGGAAATCTTCTGCGACAGCGAGGAAAACACCGAGGGCACCAGCCTCACCCAG CAGGAGAGCCTGAGCCGGACCATCCCTCCAGATAAGACCGTGATCGAGTACGAGTACGACGTGCGGACAACAGATATCTG CGCCGGCCCCGAGGAGCAGGAGCTGAGCCTGCAGGAGGAAGTGTCTACACAGGGCACACTGCTGGAAAGCCAGGCCGCCC TGGCCGTGCTGGGACCTCAAACACTGCAGTACAGCTACACCCCTCAGCTGCAAGATCTGGACCCCCTGGCCCAGGAACAC ACAGACAGCGAGGAAGGCCCAGAAGAGGAGCCTAGCACCACCCTGGTGGACTGGGACCCTCAGACCGGAAGACTGTGCAT CCCCAGCCTGTCCAGCTTTGATCAGGACTCTGAGGGATGTGAACCTAGCGAGGGCGACGGCCTGGGCGAGGAAGGCCTCC TGTCTAGACTGTATGAGGAGCCTGCCCCTGATAGACCCCCTGGAGAGAATGAAACCTACCTGATGCAGTTCATGGAAGAG
TGGGGCCTGTACGTGCAGATGGAAAACAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGC TGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCG CAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAG CAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGA CTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCG
CCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGC GCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGG AGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGC ACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCT AGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAA TATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTGCTGGCCCTGTTCGCCTTCGTGGGCTTCA TGCTGATCCTGGTGGTGGTTCCACTGTTTGTGTGGAAGATGGGCAGACTGCTCCAGTACAGCTGCTGCCCTGTGGTGGTC CTGCCTGATACCCTGAAGATCACCAACAGCCCTCAGAAACTGATCTCTTGTAGACGGGAAGAGGTGGACGCCTGCGCTAC AGCCGTGATGAGCCCCGAGGAACTGCTGAGAGCCTGGATCTCC IFNGR1-2RB-S5_IFNGR2 (SEQ ID NO: 141) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC
AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTG TTTCTACATCAAAAAGATTAACCCCCTCAAGGAAAAGTCTATCATCCTGCCTAAGTCCCTGATCAGCGTGGTGCGGAGCG CCACCCTGGAAACAAAGCCAGAAAGCAAGTATGTGTCTCTGATCACCAGCTACCAGCCTTTCTCCTTGGAGAAGGAAGTG GTTTGTGAAGAGCCCCTGTCCCCTGCTACCGTGCCCGGAATGCACACAGAGGATAATCCCGGCAAGGTGGAGCACACCGA GGAGCTGAGTAGCATAACAGAGGTGGTGACAACCGAAGAAAACATCCCCGATGTGGTGCCTGGCAGCCACCTGACACCTA TCGAGAGAGAGTCCAGCTCTCCACTGAGCTCTAACCAGAGCGAGCCTGGCTCCATCGCCCTGAACAGCTACCACTCTAGA AATTGCAGCGAGTCAGATCACAGCAGAAACGGCTTTGACACCGACAGCAGCTGCCTGGAGTCTCATTCCTCCCTGTCTGA TTCTGAGTTCCCTCCAAACAACAAGGGCGAGATCAAGACCGAGGGCCAGGAGCTGATCACCGTGATCAAAGCCCCTACAA GCGATGCCTACCTGAGCCTGGACGTGCTGGTGGATCTGCTGGTGGACGACTCCGGCAAGGAATCTCTGATCGGCTACAGA CCTACCGAGGACAGCAAGGAGTTCAGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGC TGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCG CAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAG CAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGA CTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCG CCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGC GCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGG AGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGC ACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCT AGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAA TATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCC
TGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCCTGGTACTCAAATACCGGGGCCTGATCAAGTACTGGTTCCATACCCCT CCTAGCATCCCTCTGCAGATTGAAGAGTACCTGAAAGATCCTACCCAACCTATCCTGGAAGCCCTGGACAAGGACAGCAG
6727-109858-02 CCCTAAGGACGACGTCTGGGACAGCGTGTCCATCATCTCTTTCCCCGAGAAAGAACAGGAGGACGTGCTGCAGACCCTGT GATAA IFNGR1-2RB-S5-SOCSYF_IFNGR2 (SEQ ID NO: 142) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTG
TTTCTACATCAAAAAGATTAACCCCCTCAAGGAAAAGTCTATCATCCTGCCTAAGTCCCTGATCAGCGTGGTGCGGAGCG CCACCCTGGAAACAAAGCCAGAAAGCAAGTATGTGTCTCTGATCACCAGCTACCAGCCTTTCTCCTTGGAGAAGGAAGTG GTTTGTGAAGAGCCCCTGTCCCCTGCTACCGTGCCCGGAATGCACACAGAGGATAATCCCGGCAAGGTGGAGCACACCGA GGAGCTGAGTAGCATAACAGAGGTGGTGACAACCGAAGAAAACATCCCCGATGTGGTGCCTGGCAGCCACCTGACACCTA TCGAGAGAGAGTCCAGCTCTCCACTGAGCTCTAACCAGAGCGAGCCTGGCTCCATCGCCCTGAACAGCTACCACTCTAGA
AATTGCAGCGAGTCAGATCACAGCAGAAACGGCTTTGACACCGACAGCAGCTGCCTGGAGTCTCATTCCTCCCTGTCTGA TTCTGAGTTCCCTCCAAACAACAAGGGCGAGATCAAGACCGAGGGCCAGGAGCTGATCACCGTGATCAAAGCCCCTACAA GCGATGCCTACCTGAGCCTGGACGTGCTGGTGGATCTGCTGGTGGACGACTCCGGCAAGGAATCTCTGATCGGCTTCAGA CCTACCGAGGACAGCAAGGAGTTCAGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGC TGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCG CAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAG CAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGA CTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCG CCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGC GCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGG AGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGC ACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCT AGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAA TATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCC TGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCCTGGTACTCAAATACCGGGGCCTGATCAAGTACTGGTTCCATACCCCT CCTAGCATCCCTCTGCAGATTGAAGAGTACCTGAAAGATCCTACCCAACCTATCCTGGAAGCCCTGGACAAGGACAGCAG CCCTAAGGACGACGTCTGGGACAGCGTGTCCATCATCTCTTTCCCCGAGAAAGAACAGGAGGACGTGCTGCAGACCCTGT GATAA IFNGR1-2RB-Cterm20_IFNGR2 (SEQ ID NO: 143)
ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTG TTTCTACATCAAAAAGATTAACCCCCTCAAGGAAAAGTCTATCATCCTGCCTAAGTCCCTGATCAGCGTGGTGCGGAGCG CCACCCTGGAAACAAAGCCAGAAAGCAAGTATGTGTCTCTGATCACCAGCTACCAGCCTTTCTCCTTGGAGAAGGAAGTG GTTTGTGAAGAGCCCCTGTCCCCTGCTACCGTGCCCGGAATGCACACAGAGGATAATCCCGGCAAGGTGGAGCACACCGA GGAGCTGAGTAGCATAACAGAGGTGGTGACAACCGAAGAAAACATCCCCGATGTGGTGCCTGGCAGCCACCTGACACCTA TCGAGAGAGAGTCCAGCTCTCCACTGAGCTCTAACCAGAGCGAGCCTGGCTCCATCGCCCTGAACAGCTACCACTCTAGA AATTGCAGCGAGTCAGATCACAGCAGAAACGGCTTTGACACCGACAGCAGCTGCCTGGAGTCTCATTCCTCCCTGTCTGA TTCTGAGTTCCCTCCAAACAACAAGGGCGAGATCAAGACCGAGGGCCAGGAGCTGATCACCGTGATCAAAGCCCCTAACA CCGACGCCTACCTGAGCCTGCAGGAGCTGCAGGGCCAGGATCCTACACACCTGGTGAGAGCCAAGAGGAGCGGCAGCGGC GCCACCAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTC CCTGCTGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAAC
ACCCCAAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTG GTGTACCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCA GATCACCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGAC
6727-109858-02 TGAGAGCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGC CCCCCCGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATAC ATCTACAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCA ACTCTATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGC AACATCTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGT TATCCTGATATCTGTGGGGACCTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCCTGGTACTCAAATACCGGG GCCTGATCAAGTACTGGTTCCATACCCCTCCTAGCATCCCTCTGCAGATTGAAGAGTACCTGAAAGATCCTACCCAACCT ATCCTGGAAGCCCTGGACAAGGACAGCAGCCCTAAGGACGACGTCTGGGACAGCGTGTCCATCATCTCTTTCCCCGAGAA AGAACAGGAGGACGTGCTGCAGACCCTGTGATAA IFNGR1-GHR-S5x2_IFNGR2 (SEQ ID NO: 144) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC
AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT
GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTG TTTCTACATCAAAAAGATTAACCCCCTCAAGGAAAAGTCTATCATCCTGCCTAAGTCCCTGATCAGCGTGGTGCGGAGCG CCACCCTGGAAACAAAGCCAGAAAGCAAGTATGTGTCTCTGATCACCAGCTACCAGCCTTTCTCCTTGGAGAAGGAAGTG GTTTGTGAAGAGCCCCTGTCCCCTGCTACCGTGCCCGGAATGCACACAGAGGATAATCCCGGCAAGGTGGAGCACACCGA GGAGCTGAGTAGCATAACAGAGGTGGTGACAACCGAAGAAAACATCCCCGATGTGGTGCCTGGCAGCCACCTGACACCTA TCGAGAGAGAGTCCAGCTCTCCACTGAGCTCTAACCAGAGCGAGCCTGGCTCCATCGCCCTGAACAGCTACCACTCTAGA AATTGCAGCGAGTCAGATCACAGCAGAAACGGCTTTGACACCGACAGCAGCTGCCTGGAGTCTCATTCCTCCCTGTCTGA TTCTGAGTTCCCTCCAAACAACAAGGGCGAGATCAAGACCGAGGGCCAGGAGCTGATCACCGTGATCAAAGCCCCTATGG ACAACGCCTACTTCTGCGAGGCCGTGCTGGTGGATCTGCTGGTGGACGACAGCGGCAAGGAACAGGAGGACATCTACATC ACCACAGAGGATTCTAAGGAGTTCAGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGC TGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCG CAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAG CAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGA CTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCG CCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGC GCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGG AGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGC ACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCT AGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAA
TATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCC TGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCCTGGTACTCAAATACCGGGGCCTGATCAAGTACTGGTTCCATACCCCT CCTAGCATCCCTCTGCAGATTGAAGAGTACCTGAAAGATCCTACCCAACCTATCCTGGAAGCCCTGGACAAGGACAGCAG CCCTAAGGACGACGTCTGGGACAGCGTGTCCATCATCTCTTTCCCCGAGAAAGAACAGGAGGACGTGCTGCAGACCCTGT GATAA IFNGR1-GHR-Cyt45_IFNGR2 (SEQ ID NO: 145) ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTG TTTCTACATCAAAAAGATTAACCCCCTCAAGGAAAAGTCTATCATCCTGCCTAAGTCCCTGATCAGCGTGGTGCGGAGCG CCACCCTGGAAACAAAGCCAGAAAGCAAGTATGTGTCTCTGATCACCAGCTACCAGCCTTTCTCCTTGGAGAAGGAAGTG GTTTGTGAAGAGCCCCTGTCCCCTGCTACCGTGCCCGGAATGCACACAGAGGATAATCCCGGCAAGGTGGAGCACACCGA
GGAGCTGAGTAGCATAACAGAGGTGGTGACAACCGAAGAAAACATCCCCGATGTGGTGCCTGGCAGCCACCTGACACCTA TCGAGAGAGAGTCCAGCTCTCCACTGAGCTCTAACCAGAGCGAGCCTGGCTCCATCGCCCTGAACAGCTACCACTCTAGA AATTGCAGCGAGTCAGATCACAGCAGAAACGGCTTTGACACCGACAGCAGCTGCCTGGAGTCTCATTCCTCCCTGTCTGA
6727-109858-02 TTCTGAGTTCCCTCCAAACAACAAGGGCGAGATCAAGACCGAGGGCCAGGAGCTGATCACCGTGATCAAAGCCCCTATGG ACAACGCCTACTTCTGTGAAGCTGATGCCAAGAAATGCATCCCCGTGGCCCCTCACATCAAGGTGGAAAGCCACATCCAG CCTAGCCTGAACCAGGAGGACATCTACATCACCACAGAGTCTCTGACCACCAGAGCCAAGAGGAGCGGCAGCGGCGCCAC CAATTTCTCACTGCTGAAGCAGGCTGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGC TGCTACTGCTGGGCGTGTTCGCCGCAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCC AAGATCCGCCTGTACAACGCCGAGCAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTA CCAAGTGCAGTTTAAGTATACAGACTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCA CCGCCACAGAATGCGACTTCACCGCCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGA GCCGAACTGGGAGCACTGCACAGCGCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCC CGAGAACATCGAGGTGACCCCTGGAGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTA CAGCCTTCTTCTGCTACTACGTGCACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCT ATTAGCCTGGATAACCTGAAGCCTAGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACAT CTTCCGGGTGGGCCACCTGAGCAATATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCC TGATATCTGTGGGGACCTTCAGCCTGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCCTGGTACTCAAATACCGGGGCCTG
ATCAAGTACTGGTTCCATACCCCTCCTAGCATCCCTCTGCAGATTGAAGAGTACCTGAAAGATCCTACCCAACCTATCCT GGAAGCCCTGGACAAGGACAGCAGCCCTAAGGACGACGTCTGGGACAGCGTGTCCATCATCTCTTTCCCCGAGAAAGAAC AGGAGGACGTGCTGCAGACCCTGTGATAA IFNGR1-EPOR-S5_IFNGR2 (SEQ ID NO: 146)
ATGGCGCTGCTGTTCCTGCTGCCTCTGGTGATGCAGGGCGTCAGCAGAGCCGAGATGGGCACCGCCGATCTGGGCCCCTC TTCCGTCCCTACACCTACCAACGTGACCATCGAGAGCTACAACATGAACCCAATCGTGTACTGGGAATACCAGATCATGC CTCAGGTGCCCGTGTTTACCGTGGAAGTGAAAAACTACGGCGTGAAAAACAGCGAATGGATCGACGCCTGCATCAACATC AGCCACCACTACTGTAATATCTCCGACCACGTGGGAGACCCAAGCAATAGCCTGTGGGTTAGAGTGAAGGCCAGAGTCGG CCAGAAGGAATCCGCCTACGCCAAGTCTGAGGAGTTCGCCGTGTGCCGGGACGGCAAGATCGGCCCTCCAAAGCTGGATA TCAGAAAGGAGGAAAAGCAGATCATGATCGACATCTTCCACCCCAGCGTGTTCGTGAACGGCGACGAGCAGGAGGTGGAC TACGACCCTGAAACCACTTGCTACATCCGGGTGTATAATGTGTACGTGCGGATGAACGGCAGCGAGATCCAGTATAAGAT CCTGACCCAGAAAGAAGATGACTGCGATGAGATCCAATGTCAGCTCGCTATCCCTGTGAGCAGCCTTAACAGCCAGTACT GCGTGTCCGCTGAAGGCGTGCTGCATGTGTGGGGAGTGACCACCGAAAAGAGCAAGGAAGTGTGCATCACCATCTTTAAC AGCAGCATCAAGGGCAGCCTGTGGATCCCTGTAGTCGCCGCTCTGCTGCTTTTTTTAGTCCTGAGCCTGGTCTTCATCTG TTTCTACATCAAAAAGATTAACCCCCTCAAGGAAAAGTCTATCATCCTGCCTAAGTCCCTGATCAGCGTGGTGCGGAGCG CCACCCTGGAAACAAAGCCAGAAAGCAAGTATGTGTCTCTGATCACCAGCTACCAGCCTTTCTCCTTGGAGAAGGAAGTG GTTTGTGAAGAGCCCCTGTCCCCTGCTACCGTGCCCGGAATGCACACAGAGGATAATCCCGGCAAGGTGGAGCACACCGA GGAGCTGAGTAGCATAACAGAGGTGGTGACAACCGAAGAAAACATCCCCGATGTGGTGCCTGGCAGCCACCTGACACCTA TCGAGAGAGAGTCCAGCTCTCCACTGAGCTCTAACCAGAGCGAGCCTGGCTCCATCGCCCTGAACAGCTACCACTCTAGA AATTGCAGCGAGTCAGATCACAGCAGAAACGGCTTTGACACCGACAGCAGCTGCCTGGAGTCTCATTCCTCCCTGTCTGA TTCTGAGTTCCCTCCAAACAACAAGGGCGAGATCAAGACCGAGGGCCAGGAGCTGATCACCGTGATCAAAGCCCCTACAA GCGACACCTACCTGGTCCTGGACGTGCTGGTGGACCTGCTGGTGGATGATTCTGGCAAGGAGAGCCTGATCGGCTACAGA CCTACAGAGGACTCCAAGGAGTTCAGCAGAGCCAAGAGGAGCGGCAGCGGCGCCACCAATTTCTCACTGCTGAAGCAGGC TGGAGATGTGGAGGAAAACCCTGGCCCTATGAGGCCCACACTGCTGTGGTCCCTGCTGCTACTGCTGGGCGTGTTCGCCG
CAGCCGCAGCTGCTCCGCCTGACCCCCTGAGCCAGCTGCCTGCCCCTCAACACCCCAAGATCCGCCTGTACAACGCCGAG CAGGTGCTCAGCTGGGAGCCTGTCGCCCTGAGCAATTCCACCAGACCAGTGGTGTACCAAGTGCAGTTTAAGTATACAGA CTCTAAGTGGTTCACCGCCGACATCATGAGCATCGGCGTGAACTGCACTCAGATCACCGCCACAGAATGCGACTTCACCG CCGCCAGCCCTAGCGCCGGATTTCCTATGGACTTCAACGTCACCCTGAGACTGAGAGCCGAACTGGGAGCACTGCACAGC GCCTGGGTGACAATGCCCTGGTTTCAGCACTACCGCAACGTGACCGTGGGCCCCCCCGAGAACATCGAGGTGACCCCTGG AGAGGGCTCTCTGATTATCAGATTCAGCAGCCCCTTCGACATTGCCGATACATCTACAGCCTTCTTCTGCTACTACGTGC ACTACTGGGAGAAAGGCGGCATCCAGCAGGTGAAGGGACCTTTCAGAAGCAACTCTATTAGCCTGGATAACCTGAAGCCT AGCCGGGTGTACTGTCTGCAGGTGCAGGCCCAGCTGCTCTGGAACAAGAGCAACATCTTCCGGGTGGGCCACCTGAGCAA TATCAGCTGCTACGAGACAATGGCCGATGCCTCAACAGAGCTGCAACAGGTTATCCTGATATCTGTGGGGACCTTCAGCC TGCTGTCTGTGCTGGCCGGCGCTTGTTTCTTCCTGGTACTCAAATACCGGGGCCTGATCAAGTACTGGTTCCATACCCCT CCTAGCATCCCTCTGCAGATTGAAGAGTACCTGAAAGATCCTACCCAACCTATCCTGGAAGCCCTGGACAAGGACAGCAG CCCTAAGGACGACGTCTGGGACAGCGTGTCCATCATCTCTTTCCCCGAGAAAGAACAGGAGGACGTGCTGCAGACCCTGT GATAA V. Overview of Aspects Aspect 1. A nucleic acid molecule or molecules encoding a first chimeric polypeptide, wherein: the first chimeric polypeptide comprises an interferon gamma receptor 1 (IFNGR1) extracellular domain, a first transmembrane domain, and a first intracellular signaling domain, wherein the first
6727-109858-02 intracellular signaling domain is a heterologous signaling domain of a cytokine receptor or a modified IFNGR1 intracellular signaling domain. Aspect 2. The nucleic acid molecule or molecules of aspect 1, further encoding a second chimeric polypeptide, wherein: the second chimeric polypeptide comprises an interferon gamma receptor 2 (IFNGR2) extracellular domain, a second transmembrane domain, and a second intracellular signaling domain, wherein the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor or an IFNGR2 intracellular signaling domain. Aspect 3. The nucleic acid molecule or molecules of aspect 2, wherein the first intracellular signaling domain is a heterologous intracellular signaling domain of a first cytokine receptor and/or the second intracellular signaling domain is a heterologous intracellular signaling domain of a second cytokine receptor. Aspect 4. The nucleic acid molecule or molecules of aspect 3, wherein the first cytokine receptor and the second cytokine receptor are individually selected from the group consisting of: erythropoietin receptor (EPOR), growth hormone receptor (GHR), thrombopoietin receptor (TPOR), prolactin receptor (PRLR), leptin receptor (LEPR), thymic stromal lymphopoietin receptor (TSLPR), colony stimulating factor 2 receptor subunit beta (CSF2RB), interleukin 3 receptor subunit alpha (IL3RA), interleukin 2 receptor subunit beta (IL2RB), interleukin 7 receptor (IL7R), interleukin 9 receptor (IL9R), insulin receptor (INSR), membrane glycoprotein 130 (GP130), CD28, 4-1BB, inducible T cell costimulator (ICOS), CD2, toll-like receptor 1 (TLR1), toll-like receptor 2 (TLR2), toll-like receptor 4 (TLR4), toll-like receptor 6(TLR6), epidermal growth factor receptor (EGFR), insulin-like growth factor 1 receptor (IGF1R), MET proto-oncogene receptor tyrosine kinase (MET), ROS1 proto-oncogene 1 receptor tyrosine kinase (ROS1), granulocyte-macrophage colony stimulating factor receptor alpha (GMCSFRA), interleukin 2 receptor subunit gamma (IL2RG), interleukin 6 receptor (IL6R), interleukin 11 receptor subunit alpha (IL11RA), oncostatin M receptor (OSMRB), interleukin 10 receptor subunit alpha (IL10RA), interleukin 10 receptor subunit beta (IL10RB), interleukin 22 receptor (IL22R), interleukin 20 receptor subunit alpha (IL20RA), and interleukin 20 receptor subunit beta (IL20RB). Aspect 5. The nucleic acid molecule or molecules of any one of aspects 1-4, wherein the amino acid sequence of the first intracellular signaling domain is at least 90% identical to residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268- 389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267- 441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues
6727-109858-02 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271- 465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267- 385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. Aspect 6. The nucleic acid molecule or molecules of any one of aspects 1-5, wherein the amino acid sequence of the first intracellular signaling domain comprises or consists of residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267- 385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269- 810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269-503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273- 313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267-304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of
6727-109858-02 SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267- 461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267-348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. Aspect 7. The nucleic acid molecule or molecules of any one of aspects 1-6, wherein the amino acid sequence of the second intracellular signaling domain is at least 90% identical to residues 801- 1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761- 846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616- 1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844- 900 of SEQ ID NO: 67. Aspect 8. The nucleic acid molecule or molecules of any one of aspects 1-7, wherein the amino acid sequence of the second intracellular signaling domain comprises or consists of residues 801- 1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610-1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761- 846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600-637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616- 1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757-842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of
6727-109858-02 SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844- 900 of SEQ ID NO: 67. Aspect 9. The nucleic acid molecule or molecules of aspect 1, wherein the first intracellular signaling domain is a modified IFNGR1 signaling domain. Aspect 10. The nucleic acid molecule or molecules of aspect 2, wherein the first intracellular signaling domain is a modified IFNGR1 signaling domain and the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. Aspect 11. The nucleic acid molecule or molecules of aspect 9 or aspect 10, wherein the amino acid sequence of the modified IFNGR1 intracellular signaling domain is at least 90% identical to residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. Aspect 12. The nucleic acid molecule or molecules of any one of aspects 9-11, wherein the amino acid sequence of the modified IFNGR1 intracellular signaling domain comprises or consists of residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. Aspect 13. The nucleic acid molecule or molecules of any one of aspects 10-12, wherein the wild-type IFNGR2 intracellular signaling domain comprises residues 288-356 of SEQ ID NO: 148. Aspect 14. The nucleic acid molecule or molecules of any one of aspects 1-13, wherein the first transmembrane domain is a first heterologous transmembrane domain. Aspect 15. The nucleic acid molecule or molecules of any one of aspects 2-14, wherein the second transmembrane domain is a second heterologous transmembrane domain. Aspect 16. The nucleic acid molecule or molecules of aspect 14 or aspect 15, wherein: the first heterologous transmembrane domain is from the same cytokine receptor as the first intracellular signaling domain; and/or the second heterologous transmembrane domain is from the same cytokine receptor as the second intracellular signaling domain. Aspect 17. The nucleic acid molecule or molecules of any one of aspects 1-13, wherein the first transmembrane domain is an IFNGR1 transmembrane domain. Aspect 18. The nucleic acid molecule or molecules of any one of aspects 2-13 and 17, wherein the second transmembrane domain is an IFNGR2 transmembrane domain. Aspect 19. The nucleic acid molecule or molecules of any one of aspects 2-18, wherein the first chimeric polypeptide and the second chimeric polypeptide are encoded by a single nucleic acid molecule and the coding sequence for the first chimeric polypeptide and the coding sequence for the second chimeric polypeptide are separated by a nucleic acid sequence encoding a self-cleaving peptide.
6727-109858-02 Aspect 20. The nucleic acid molecule or molecules of aspect 19, wherein the self-cleaving peptide is a 2A peptide. Aspect 21. The nucleic acid molecule or molecules of aspect 20, wherein the amino acid sequence of the self-cleaving peptide comprises residues 512-530 of SEQ ID NO: 28. Aspect 22. The nucleic acid molecule or molecules of aspect 20, wherein the 2A peptide is a porcine teschovirus-12A peptide (P2A), a Thosea asigna virus 2A peptide (T2A), an equine rhinitis A virus 2A peptide (E2A), or a foot and mouth disease virus 2A peptide (F2A). Aspect 23. The nucleic acid molecule or molecules of aspect 22, wherein the amino acid sequence of the P2A peptide comprises SEQ ID NO: 149, the amino acid sequence of the F2A peptide comprises SEQ ID NO: 150, the amino acid sequence of the E2A peptide comprises SEQ ID NO: 151, or the amino acid sequence of the T2A peptide comprises SEQ ID NO: 152. Aspect 24. The nucleic acid molecule or molecules of any one of aspects 2-18, wherein the first chimeric polypeptide is encoded by a first nucleic acid molecule and the second chimeric polypeptide is encoded by a second nucleic acid molecule. Aspect 25. The nucleic acid molecule or molecules of any one of aspects 1-24, which is codon- optimized for expression in human cells. Aspect 26. The nucleic acid molecule or molecules of any one of aspects 1-25, comprising the nucleotide sequence of any one of SEQ ID NOs: 74-100, or a degenerate variant thereof. Aspect 27. The nucleic acid molecule or molecules of any one of aspects 2-25, comprising the nucleotide sequence of any one of SEQ ID NOs: 101-146, or a degenerate variant thereof. Aspect 28. The nucleic acid molecule or molecules of any one of aspects 1-27, operably linked to a promoter. Aspect 29. A vector comprising the nucleic acid molecule or molecules of any one of aspects 1- 28. Aspect 30. The vector of aspect 29, which is a viral vector. Aspect 31. The vector of aspect 30, which is a gammaretroviral vector or a lentiviral vector. Aspect 32. A modified immune cell comprising the nucleic acid molecule or molecules of any one of aspects 1-28 or the vector of any one of aspects 29-31. Aspect 33. The modified immune cell of aspect 32, wherein the immune cell is a T cell. Aspect 34. The modified immune cell of aspect 33, wherein the T cell is a tumor-reactive T cell or a tumor-infiltrating lymphocyte (TIL). Aspect 35. The modified immune cell of aspect 33 or aspect 34, wherein the T cell is a human T cell. Aspect 36. A modified immune cell expressing a first chimeric polypeptide, wherein the first chimeric polypeptide comprises an interferon gamma receptor 1 (IFNGR1) extracellular domain, a first transmembrane domain, and a first intracellular signaling domain, wherein the first intracellular signaling
6727-109858-02 domain is a heterologous signaling domain of a cytokine receptor or a modified IFNGR1 intracellular signaling domain. Aspect 37. The modified immune cell of aspect 36, further expressing a second chimeric polypeptide, wherein: the second chimeric polypeptide comprises an interferon gamma receptor 2 (IFNGR2) extracellular domain, a second transmembrane domain, and a second intracellular signaling domain, wherein the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor or an IFNGR2 intracellular signaling domain. Aspect 38. The modified immune cell of aspect 36 or aspect 37, wherein the first intracellular signaling domain is a heterologous intracellular signaling domain of a first cytokine receptor and/or the second intracellular signaling domain is a heterologous intracellular signaling domain of a second cytokine receptor. Aspect 39. The modified immune cell of aspect 38, wherein the first cytokine receptor and the second cytokine receptor are individually selected from the group consisting of: erythropoietin receptor (EPOR), growth hormone receptor (GHR), thrombopoietin receptor (TPOR), prolactin receptor (PRLR), leptin receptor (LEPR), thymic stromal lymphopoietin receptor (TSLPR), colony stimulating factor 2 receptor subunit beta (CSF2RB), interleukin 3 receptor subunit alpha (IL3RA), interleukin 2 receptor subunit beta (IL2RB), interleukin 7 receptor (IL7R), interleukin 9 receptor (IL9R), insulin receptor (INSR), membrane glycoprotein 130 (GP130), CD28, 4-1BB, inducible T cell costimulator (ICOS), CD2, toll-like receptor 1 (TLR1), toll-like receptor 2 (TLR2), toll-like receptor 4 (TLR4), toll-like receptor 6(TLR6), epidermal growth factor receptor (EGFR), insulin-like growth factor 1 receptor (IGF1R), MET proto- oncogene receptor tyrosine kinase (MET), ROS1 proto-oncogene 1 receptor tyrosine kinase (ROS1), granulocyte-macrophage colony stimulating factor receptor alpha (GMCSFRA), interleukin 2 receptor subunit gamma (IL2RG), interleukin 6 receptor (IL6R), interleukin 11 receptor subunit alpha (IL11RA), oncostatin M receptor (OSMRB), interleukin 10 receptor subunit alpha (IL10RA), interleukin 10 receptor subunit beta (IL10RB), interleukin 22 receptor (IL22R), interleukin 20 receptor subunit alpha (IL20RA), and interleukin 20 receptor subunit beta (IL20RB). Aspect 40. The modified immune cell of any one of aspects 36-39, wherein the amino acid sequence of the first intracellular signaling domain is at least 90% identical to residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of
6727-109858-02 SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269- 503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267- 304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267- 348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. Aspect 41. The modified immune cell of any one of aspects 36-40 wherein the amino acid sequence of the first intracellular signaling domain comprises or consists of residues 269-503 of SEQ ID NO: 1; residues 269-433 of SEQ ID NO: 2; residues 270-619 of SEQ ID NO: 3; residues 268-389 of SEQ ID NO: 4; residues 270-633 of SEQ ID NO: 5; residues 269-571 of SEQ ID NO: 6; residues 267-385 of SEQ ID NO: 7; residues 263-699 of SEQ ID NO: 8; residues 266-318 of SEQ ID NO: 9; residues 271-555 of SEQ ID NO: 10; residues 271-465 of SEQ ID NO: 11; residues 267-496 of SEQ ID NO: 12; residues 269-671 of SEQ ID NO: 13; residues 268-544 of SEQ ID NO: 14; residues 281-313 of SEQ ID NO: 15; residues 273-313 of SEQ ID NO: 16; residues 273-314 of SEQ ID NO: 17; residues 267-304 of SEQ ID NO: 18; residues 272-387 of SEQ ID NO: 19; residues 272-387 of SEQ ID NO: 20; residues 267-441 of SEQ ID NO: 21; residues 267-453 of SEQ ID NO: 22; residues 267-455 of SEQ ID NO: 23; residues 269-810 of SEQ ID NO: 25; residues 270-677 of SEQ ID NO: 26; residues 269-733 of SEQ ID NO: 27; residues 269- 503 of SEQ ID NO: 28, residues 269-433 of SEQ ID NO: 29; residues 270-619 of SEQ ID NO: 30; residues 268-389 of SEQ ID NO: 31; residues 270-633 of SEQ ID NO: 32; residues 269-571 of SEQ ID NO: 33; residues 266-318 of SEQ ID NO: 34; residues 266-385 of SEQ ID NO: 35; residues 269-671 of SEQ ID NO: 36; residues 263-699 of SEQ ID NO: 37; residues 271-555 of SEQ ID NO: 38; residues 271-465 of SEQ ID NO: 39; residues 267-496 of SEQ ID NO: 40; residues 268-544 of SEQ ID NO: 41; residues 273-313 of SEQ ID NO: 42; residues 273-313 of SEQ ID NO: 43; residues 273-314 of SEQ ID NO: 44; residues 267- 304 of SEQ ID NO: 45; residues 272-387 of SEQ ID NO: 46; residues 267-451 of SEQ ID NO: 47; residues 267-441 of SEQ ID NO: 48; residues 267-453 of SEQ ID NO: 49; residues 267-455 of SEQ ID NO: 50; residues 267-677 of SEQ ID NO: 51; residues 267-703 of SEQ ID NO: 52; residues 267-320 of SEQ ID NO: 53; residues 267-352 of SEQ ID NO: 54; residues 267-319 of SEQ ID NO: 55; residues 267-385 of SEQ ID NO: 56; residues 267-551 of SEQ ID NO: 57; residues 267-496 of SEQ ID NO: 58; residues 267-461 of
6727-109858-02 SEQ ID NO: 59; residues 272-325 of SEQ ID NO: 60; residues 267-352 of SEQ ID NO: 61; residues 267- 348 of SEQ ID NO: 62; residues 267-297 of SEQ ID NO: 63; residues 267-519 of SEQ ID NO: 64; residues 267-588 of SEQ ID NO: 65; residues 267-591 of SEQ ID NO: 66; or residues 267-548 of SEQ ID NO: 67. Aspect 42. The modified immune cell of any one of aspects 36-41, wherein the amino acid sequence of the second intracellular signaling domain is at least 90% identical to residues 801-1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610- 1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761-846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600- 637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616-1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757- 842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844-900 of SEQ ID NO: 67. Aspect 43. The modified immune cell of any one of aspects 36-42, wherein the amino acid sequence of the second intracellular signaling domain comprises or consists of residues 801-1035 of SEQ ID NO: 28; residues 731-895 of SEQ ID NO: 29; residues 918-1267 of SEQ ID NO: 30; residues 686-807 of SEQ ID NO: 31; residues 932-1295 of SEQ ID NO: 32; residues 869-1171 of SEQ ID NO: 33; residues 610- 1046 of SEQ ID NO: 34; residues 685-879 of SEQ ID NO: 35; residues 969-1371 of SEQ ID NO: 36; residues 1000-1053 of SEQ ID NO: 37; residues 851-936 of SEQ ID NO: 38; residues 761-846 of SEQ ID NO: 39; residues 792-877 of SEQ ID NO: 40; residues 841-1117 of SEQ ID NO: 41; residues 615-655 of SEQ ID NO: 42; residues 615-655 of SEQ ID NO: 43; residues 616-657 of SEQ ID NO: 44; residues 600- 637 of SEQ ID NO: 45; residues 688-803 of SEQ ID NO: 46; residues 747-931 of SEQ ID NO: 47; residues 737-911 of SEQ ID NO: 48; residues 749-935 of SEQ ID NO: 49; residues 751-939 of SEQ ID NO: 50; residues 976-1383 of SEQ ID NO: 51; residues 999-1052 of SEQ ID NO: 52; residues 616-1052 of SEQ ID NO: 53; residues 648-932 of SEQ ID NO: 54; residues 615-1051 of SEQ ID NO: 55; residues 681-875 of SEQ ID NO: 56; residues 847-932 of SEQ ID NO: 57; residues 792-877 of SEQ ID NO: 58; residues 757- 842 of SEQ ID NO: 59; residues 617-1053 of SEQ ID NO: 60; residues 652-936 of SEQ ID NO: 61; residues 645-921 of SEQ ID NO: 62; residues 594-870 of SEQ ID NO: 63; residues 816-1092 of SEQ ID NO: 64; residues 885-967 of SEQ ID NO: 65; residues 887-943 of SEQ ID NO: 66; residues 844-900 of SEQ ID NO: 67.
6727-109858-02 Aspect 44. The modified immune cell of aspect 36, wherein the first intracellular signaling domain is a modified IFNGR1 signaling domain. Aspect 45. The modified immune cell of aspect 37, wherein the first intracellular signaling domain is a modified IFNGR1 signaling domain and the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. Aspect 46. The modified immune cell of aspect 44 or aspect 45, wherein the amino acid sequence of the modified IFNGR1 intracellular signaling domain is at least 90% identical to residues 267- 489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. Aspect 47. The modified immune cell of any one of aspects 44-46, wherein the amino acid sequence of the modified IFNGR1 intracellular signaling domain comprises or consists of residues 267-489 of SEQ ID NO: 68; residues 267-489 of SEQ ID NO: 69; residues 267-472 of SEQ ID NO: 70; residues 267-489 of SEQ ID NO: 71; residues 267-497 of SEQ ID NO: 72; or residues 267-489 of SEQ ID NO: 73. Aspect 48. The modified immune cell of any one of aspects 45-47, wherein the wild-type IFNGR2 intracellular signaling domain comprises residues 288-356 of SEQ ID NO: 148. Aspect 49. The modified immune cell of any one of aspects 36-48, wherein the first transmembrane domain is a first heterologous transmembrane domain. Aspect 50. The modified immune cell of any one of aspects 37-49, wherein the second transmembrane domain is a second heterologous transmembrane domain. Aspect 51. The modified immune cell of aspect 49 or aspect 50, wherein: the first heterologous transmembrane domain is from the same cytokine receptor as the first intracellular signaling domain; and/or the second heterologous transmembrane domain is from the same cytokine receptor as the second intracellular signaling domain. Aspect 52. The modified immune cell of any one of aspects 36-48, wherein the first transmembrane domain is an IFNGR1 transmembrane domain. Aspect 53. The modified immune cell of any one of aspects 37-48 and 52, wherein the second transmembrane domain is an IFNGR2 transmembrane domain. Aspect 54. The modified immune cell of any one of aspects 36-53, wherein the amino acid sequence of the first chimeric polypeptide is at least 90% identical to SEQ ID NO: 1; SEQ ID NO: 2; SEQ ID NO: 3; SEQ ID NO: 4; SEQ ID NO: 5; SEQ ID NO: 6; SEQ ID NO: 7; SEQ ID NO: 8; SEQ ID NO: 9; SEQ ID NO: 10; SEQ ID NO: 11; SEQ ID NO: 12; SEQ ID NO: 13; SEQ ID NO: 14; SEQ ID NO: 15; SEQ ID NO: 16; SEQ ID NO: 17; SEQ ID NO: 18; SEQ ID NO: 19; SEQ ID NO: 20; SEQ ID NO: 21; SEQ ID NO: 21; SEQ ID NO: 22; SEQ ID NO: 23; SEQ ID NO: 24; SEQ ID NO: 25; SEQ ID NO: 26; SEQ ID NO: 27; residues 1-503 of SEQ ID NO: 28; residues 1-433 of SEQ ID NO: 29; residues 1-619 of SEQ ID NO: 30; residues 1-389 of SEQ ID NO: 31; residues 1-633 of SEQ ID NO: 32; residues 1-571 of SEQ ID NO: 33; residues 1-318 of SEQ ID NO: 34; residues 1-385 of SEQ ID NO: 35; residues 1-671 of SEQ ID NO:
6727-109858-02 36; residues 1-699 of SEQ ID NO: 37; residues 1-555 of SEQ ID NO: 38; residues 1-465 of SEQ ID NO: 39; residues 1-496 of SEQ ID NO: 40; residues 1-544 of SEQ ID NO: 41; residues 1-313 of SEQ ID NO: 42; residues 1-313 of SEQ ID NO: 43; residues 1-314 of SEQ ID NO: 44; residues 1-304 of SEQ ID NO: 45; residues 1-387 of SEQ ID NO: 46; residues 1-451 of SEQ ID NO: 47; residues 1-441 of SEQ ID NO: 48; residues 1-453 of SEQ ID NO: 49; residues 1-455 of SEQ ID NO: 50; residues 1-677 of SEQ ID NO: 51; residues 1-703 of SEQ ID NO: 52; residues 1-320 of SEQ ID NO: 53; residues 1-352 of SEQ ID NO: 54; residues 1-319 of SEQ ID NO: 55; residues 1-385 of SEQ ID NO: 56; residues 1-551 of SEQ ID NO: 57; residues 1-496 of SEQ ID NO: 58; residues 1-461 of SEQ ID NO: 59; residues 1-325 of SEQ ID NO: 60; residues 1-352 of SEQ ID NO: 61; residues 1-348 of SEQ ID NO: 62; residues 1-297 of SEQ ID NO: 63; residues 1-519 of SEQ ID NO: 64; residues 1-588 of SEQ ID NO: 65; residues 1-591 of SEQ ID NO: 66; residues 1-548 of SEQ ID NO: 67; residues 1-489 of SEQ ID NO: 68; residues 1-489 of SEQ ID NO: 69; residues 1-472 of SEQ ID NO: 70; residues 1-489 of SEQ ID NO: 71; residues 1-497 of SEQ ID NO: 72; or residues 1-489 of SEQ ID NO: 73. Aspect 55. The modified immune cell of any one of aspects 36-54, wherein the amino acid sequence of the first chimeric polypeptide comprises or consists of SEQ ID NO: 1; SEQ ID NO: 2; SEQ ID NO: 3; SEQ ID NO: 4; SEQ ID NO: 5; SEQ ID NO: 6; SEQ ID NO: 7; SEQ ID NO: 8; SEQ ID NO: 9; SEQ ID NO: 10; SEQ ID NO: 11; SEQ ID NO: 12; SEQ ID NO: 13; SEQ ID NO: 14; SEQ ID NO: 15; SEQ ID NO: 16; SEQ ID NO: 17; SEQ ID NO: 18; SEQ ID NO: 19; SEQ ID NO: 20; SEQ ID NO: 21; SEQ ID NO: 21; SEQ ID NO: 22; SEQ ID NO: 23; SEQ ID NO: 24; SEQ ID NO: 25; SEQ ID NO: 26; SEQ ID NO: 27; residues 1-503 of SEQ ID NO: 28; residues 1-433 of SEQ ID NO: 29; residues 1-619 of SEQ ID NO: 30; residues 1-389 of SEQ ID NO: 31; residues 1-633 of SEQ ID NO: 32; residues 1-571 of SEQ ID NO: 33; residues 1-318 of SEQ ID NO: 34; residues 1-385 of SEQ ID NO: 35; residues 1-671 of SEQ ID NO: 36; residues 1-699 of SEQ ID NO: 37; residues 1-555 of SEQ ID NO: 38; residues 1-465 of SEQ ID NO: 39; residues 1-496 of SEQ ID NO: 40; residues 1-544 of SEQ ID NO: 41; residues 1-313 of SEQ ID NO: 42; residues 1-313 of SEQ ID NO: 43; residues 1-314 of SEQ ID NO: 44; residues 1-304 of SEQ ID NO: 45; residues 1-387 of SEQ ID NO: 46; residues 1-451 of SEQ ID NO: 47; residues 1-441 of SEQ ID NO: 48; residues 1-453 of SEQ ID NO: 49; residues 1-455 of SEQ ID NO: 50; residues 1-677 of SEQ ID NO: 51; residues 1-703 of SEQ ID NO: 52; residues 1-320 of SEQ ID NO: 53; residues 1-352 of SEQ ID NO: 54; residues 1-319 of SEQ ID NO: 55; residues 1-385 of SEQ ID NO: 56; residues 1-551 of SEQ ID NO: 57; residues 1-496 of SEQ ID NO: 58; residues 1-461 of SEQ ID NO: 59; residues 1-325 of SEQ ID NO: 60; residues 1-352 of SEQ ID NO: 61; residues 1-348 of SEQ ID NO: 62; residues 1-297 of SEQ ID NO: 63; residues 1-519 of SEQ ID NO: 64; residues 1-588 of SEQ ID NO: 65; residues 1-591 of SEQ ID NO: 66; residues 1-548 of SEQ ID NO: 67; residues 1-489 of SEQ ID NO: 68; residues 1-489 of SEQ ID NO: 69; residues 1-472 of SEQ ID NO: 70; residues 1-489 of SEQ ID NO: 71; residues 1-497 of SEQ ID NO: 72; or residues 1-489 of SEQ ID NO: 73. Aspect 56. The modified immune cell of any one of aspects 37-55, wherein the amino acid sequence of the second chimeric polypeptide is at least 90% identical to residues 531-1035 of SEQ ID NO:
6727-109858-02 28; residues 461-895 of SEQ ID NO: 29; residues 645-1297 of SEQ ID NO: 30; residues 417-807 of SEQ ID NO: 31; residues 661-1295 of SEQ ID NO: 32; residues 599-1171 of SEQ ID NO: 33; residues 346-1046 of SEQ ID NO: 34; residues 413-879 of SEQ ID NO: 35; residues 699-1371 of SEQ ID NO: 36; residues 727-1053 of SEQ ID NO: 37; residues 535-936 of SEQ ID NO: 38; residues 493-846 of SEQ ID NO: 39; residues 524-877 of SEQ ID NO: 40; residues 572-1117 of SEQ ID NO: 41; residues 341-655 of SEQ ID NO: 42; residues 341-655 of SEQ ID NO: 43; residues 342-657 of SEQ ID NO: 44; residues 332-637 of SEQ ID NO: 45; residues 415-803 of SEQ ID NO: 46; residues 479-931 of SEQ ID NO: 47; residues 469- 911 of SEQ ID NO: 48; residues 481-935 of SEQ ID NO: 49; residues 483-939 of SEQ ID NO: 50; residues 705-1383 of SEQ ID NO: 51; residues 731-1053 of SEQ ID NO: 52; residues 348-1052 of SEQ ID NO: 53; residues 380-932 of SEQ ID NO: 54; residues 347-1051 of SEQ ID NO: 55; residues 413-875 of SEQ ID NO: 56; residues 579-932 of SEQ ID NO: 57; residues 524-877 of SEQ ID NO: 58; residues 489-842 of SEQ ID NO: 59; residues 353-1053 of SEQ ID NO: 60; residues 380-936 of SEQ ID NO: 61; residues 376- 921 of SEQ ID NO: 62; residues 325-870 of SEQ ID NO: 63; residues 547-1092 of SEQ ID NO: 64; residues 616-967 of SEQ ID NO: 65; residues 619-943 of SEQ ID NO: 66; residues 576-900 of SEQ ID NO: 67; residues 517-853 of SEQ ID NO: 68; residues 517-853 of SEQ ID NO: 69; residues 500-836 of SEQ ID NO: 70; residues 517-853 of SEQ ID NO: 71; residues 525-861 of SEQ ID NO: 72; or residues 517-853 of SEQ ID NO: 73. Aspect 57. The modified immune cell of any one of aspects 37-56, wherein the amino acid sequence of the second chimeric polypeptide comprises or consists of residues 531-1035 of SEQ ID NO: 28; residues 461-895 of SEQ ID NO: 29; residues 645-1297 of SEQ ID NO: 30; residues 417-807 of SEQ ID NO: 31; residues 661-1295 of SEQ ID NO: 32; residues 599-1171 of SEQ ID NO: 33; residues 346-1046 of SEQ ID NO: 34; residues 413-879 of SEQ ID NO: 35; residues 699-1371 of SEQ ID NO: 36; residues 727- 1053 of SEQ ID NO: 37; residues 535-936 of SEQ ID NO: 38; residues 493-846 of SEQ ID NO: 39; residues 524-877 of SEQ ID NO: 40; residues 572-1117 of SEQ ID NO: 41; residues 341-655 of SEQ ID NO: 42; residues 341-655 of SEQ ID NO: 43; residues 342-657 of SEQ ID NO: 44; residues 332-637 of SEQ ID NO: 45; residues 415-803 of SEQ ID NO: 46; residues 479-931 of SEQ ID NO: 47; residues 469- 911 of SEQ ID NO: 48; residues 481-935 of SEQ ID NO: 49; residues 483-939 of SEQ ID NO: 50; residues 705-1383 of SEQ ID NO: 51; residues 731-1053 of SEQ ID NO: 52; residues 348-1052 of SEQ ID NO: 53; residues 380-932 of SEQ ID NO: 54; residues 347-1051 of SEQ ID NO: 55; residues 413-875 of SEQ ID NO: 56; residues 579-932 of SEQ ID NO: 57; residues 524-877 of SEQ ID NO: 58; residues 489-842 of SEQ ID NO: 59; residues 353-1053 of SEQ ID NO: 60; residues 380-936 of SEQ ID NO: 61; residues 376- 921 of SEQ ID NO: 62; residues 325-870 of SEQ ID NO: 63; residues 547-1092 of SEQ ID NO: 64; residues 616-967 of SEQ ID NO: 65; residues 619-943 of SEQ ID NO: 66; residues 576-900 of SEQ ID NO: 67; residues 517-853 of SEQ ID NO: 68; residues 517-853 of SEQ ID NO: 69; residues 500-836 of SEQ ID NO: 70; residues 517-853 of SEQ ID NO: 71; residues 525-861 of SEQ ID NO: 72; or residues 517-853 of SEQ ID NO: 73.
6727-109858-02 Aspect 58. A chimeric interferon gamma receptor (IFNGR), comprising a first chimeric polypeptide, wherein the first chimeric polypeptide comprises an interferon gamma receptor 1 (IFNGR1) extracellular domain, a first transmembrane domain, and a first intracellular signaling domain, wherein the first intracellular signaling domain is a heterologous signaling domain of a cytokine receptor or a modified IFNGR1 intracellular signaling domain. Aspect 59. The chimeric IFNGR of aspect 58, further comprising a second chimeric polypeptide, wherein the second chimeric polypeptide comprises an interferon gamma receptor 2 (IFNGR2) extracellular domain, a second transmembrane domain, and a second intracellular signaling domain, wherein the second intracellular signaling domain is a heterologous signaling domain of a cytokine receptor or an IFNGR2 intracellular signaling domain. Aspect 60. The chimeric IFNGR of aspect 58 or aspect 59, wherein the first intracellular signaling domain is a heterologous intracellular signaling domain of a first cytokine receptor and/or the second intracellular signaling domain is a heterologous intracellular signaling domain of a second cytokine receptor. Aspect 61. The chimeric IFNGR of aspect 60, wherein the first cytokine receptor and the second cytokine receptor are individually selected from the group consisting of: erythropoietin receptor (EPOR), growth hormone receptor (GHR), thrombopoietin receptor (TPOR), prolactin receptor (PRLR), leptin receptor (LEPR), thymic stromal lymphopoietin receptor (TSLPR), colony stimulating factor 2 receptor subunit beta (CSF2RB), interleukin 3 receptor subunit alpha (IL3RA), interleukin 2 receptor subunit beta (IL2RB), interleukin 7 receptor (IL7R), interleukin 9 receptor (IL9R), insulin receptor (INSR), membrane glycoprotein 130 (GP130), CD28, 4-1BB, inducible T cell costimulator (ICOS), CD2, toll-like receptor 1 (TLR1), toll-like receptor 2 (TLR2), toll-like receptor 4 (TLR4), toll-like receptor 6(TLR6), epidermal growth factor receptor (EGFR), insulin-like growth factor 1 receptor (IGF1R), MET proto- oncogene receptor tyrosine kinase (MET), ROS1 proto-oncogene 1 receptor tyrosine kinase (ROS1), granulocyte-macrophage colony stimulating factor receptor alpha (GMCSFRA), interleukin 2 receptor subunit gamma (IL2RG), interleukin 6 receptor (IL6R), interleukin 11 receptor subunit alpha (IL11RA), oncostatin M receptor (OSMRB), interleukin 10 receptor subunit alpha (IL10RA), interleukin 10 receptor subunit beta (IL10RB), interleukin 22 receptor (IL22R), interleukin 20 receptor subunit alpha (IL20RA), and interleukin 20 receptor subunit beta (IL20RB). Aspect 62. The chimeric IFNGR of aspect 58 wherein the first intracellular signaling domain is a modified IFNGR1 signaling domain. Aspect 63. The chimeric IFNGR of aspect 59, wherein the first intracellular signaling domain is a modified IFNGR1 signaling domain and the second intracellular signaling domain is a wild-type IFNGR2 signaling domain. Aspect 64. The chimeric IFNGR of any one of aspects 58-63, wherein the first transmembrane domain is a first heterologous transmembrane domain and/or the second transmembrane domain is a second heterologous transmembrane domain.
6727-109858-02 Aspect 65. The chimeric IFNGR of any one of aspects 58-64, wherein the first transmembrane domain is an IFNGR1 transmembrane domain and/or the second transmembrane domain is an IFNGR2 transmembrane domain. Aspect 66. A pharmaceutical composition comprising the modified immune cell of any one of aspects 32-57 and a pharmaceutically acceptable carrier. Aspect 67. A method of treating cancer in a subject, comprising administering to the subject a therapeutically effective amount of the modified immune cell of any one of aspects 32-57 or the pharmaceutical composition of aspect 66. Aspect 68. The method of aspect 67, further comprising administering one or more additional anti-cancer therapies to the subject. EXAMPLES The following examples are provided to illustrate particular features of certain aspects of the disclosure, but the scope of the claims should not be limited to those features exemplified. Example 1: Design of chimeric IFNG receptors The native IFNGR is comprised of two homodimers of IFNGR1 and IFNGR2 that are activated upon binding to IFN-γ. The chimeric IFNG receptors disclosed herein include extracellular domains from the IFNGR fused to cytoplasmic signaling domains from other receptors that can activate pathways that enhance T cell activity. Entire cytoplasmic domains (see, e.g., schematics ii, iii and iv in FIG.1 and SEQ ID NOs: 1-67) or parts of cytoplasmic domains (see, e.g., schematic v in FIG.1 and SEQ ID NOs: 68-73) from other receptors can be used. The transmembrane domain (TMD) can be derived from any receptor (e.g., from IFNGR1, IFNGR2, or the signaling receptor). In constructs that contained both IFNGR1 and IFNGR2 receptors, the sequences were separated by a sequence encoding a 2A self-cleaving (ribosomal skipping) peptide (such as SEQ ID NO: 149). Nucleic acid sequences encoding IFNG chimeric receptors were codon-optimized (e.g., SEQ ID NOs: 74-146), synthesized and cloned into the MSGV1 gammaretroviral plasmid (GenScript). Retroviral vector was generated by transfecting 293GP cells with the MSGV1 plasmid encoding the IFNG chimeric receptor and the envelope plasmid RD114. Supernatants (retroviral vector) were harvested about 2 days later and used to transduce human T cells. Example 2: Generation and characterization of engineered T cells expressing chimeric IFNG receptors Human peripheral blood mononuclear cells were stimulated with anti-CD3 antibody OKT3 (50 ng/mL) and IL-2 (300 IU/ml) for two days and then transduced with a retroviral vector encoding a TCR recognizing an HLA-C*08:02-restricted KRAS-G12D neoantigen alone (FIG.2A), or co-transduced with either a retroviral vector encoding an IFNG chimeric receptor containing the IFNGR1 extracellular domain fused to the IL-2 receptor beta chain transmembrane and cytoplasmic domains and the IFNGR2 extracellular
6727-109858-02 domain fused to the common gamma chain transmembrane and cytoplasmic domains (IFNGR/IL2R) (FIG. 2B), or a retroviral vector encoding an IFNG receptor containing the IFNGR1 extracellular domain fused to the common beta chain cytoplasmic and transmembrane domains and the IFNGR2 extracellular domain fused to the GMCSF receptor alpha transmembrane and cytoplasmic domains (IFNGR/GMCSFR) (FIG. 2C). To evaluate whether these cells could activate STAT5, which is a key transcription factor involved in IL2R and GMCSFR signaling, cells were washed, and rested overnight in media without exogenous cytokines. Cells were then stimulated with nothing, 300 IU/ml IL-2 (positive control), or titrating doses of IFNG. Thirty minutes after stimulation, cells were fixed and permeabilized with cold methanol and stained with antibodies specific for phosphorylated STAT5 (P-STAT5). Cells were washed and analyzed by flow cytometry. Data were gated on CD8+mTCRb+ transduced T cells. FIGS.2A-2C show the evaluation of biochemical signaling capacity of T cells expressing the exemplary IFNG chimeric receptors (IFNGR/IL2R or IFNGR/GMCSFR) after IFNG stimulation as measured by phosphorylated STAT5 (P-STAT5) by flow cytometry. Example 3: In vitro cytotoxicity of chimeric IFNG receptors against a pancreatic cancer cell line T cells were transduced to express the KRAS G12D-reactive TCR alone, or co-transduced to express either an IFNG chimeric receptor containing the IFNGR1 extracellular domain fused to the IL-2 receptor beta chain transmembrane and cytoplasmic domains and the IFNGR2 extracellular domain fused to the common gamma chain transmembrane and cytoplasmic domains (IFNGR/IL2R), or an IFNG receptor containing the IFNGR1 extracellular domain fused to the common beta chain cytoplasmic and transmembrane domains and the IFNGR2 extracellular domain fused to the GMCSF receptor alpha transmembrane and cytoplasmic domains (IFNGR/GMCSFR). These cells then underwent a “serial kill” assay in which the T cells were initially cocultured at 5:1 E:T (50,000 T cells, 10,000 tumor cells) with the HPAC pancreatic cancer cell line that was genetically engineered to express GFP. An additional 10,000 HPAC-GFP cells were added about every 2 days, 5 times total, until the end of the assay. FIG.3A shows GFP fluorescence (as a measure of tumor cell growth) of the KRAS-G12D-positive and HLA-C*08:02- positive HPAC-GFP pancreatic cancer cell line in the presence of T cells transduced to express the HLA- C*08:02-restricted KRAS-G12D reactive TCR with or without 300 IU/ml IL-2. FIGS.3B-3C show GFP fluorescence of the KRAS-G12D-positive and HLA-C*08:02-positive HPAC-GFP pancreatic cancer cell line in the presence of T cells co-transduced to express the HLA-C*08:02-restricted KRAS-G12D reactive TCR and IFNGR/IL2R chimeric receptors (FIG.3B) or IFNGR/GMCSFR chimeric receptors (FIG.3C). No exogenous cytokines were added to the coculture. The data from FIG.3A were incorporated into FIG.3B and FIG.3C to facilitate comparison against the control TCR alone without or with 300 IU/ml IL-2. The data demonstrate that the serial killing of tumor cells in vitro by T cells expressing the IFNG chimeric receptors is similar to that of T cells cocultured with tumor cells in the presence of exogenously added IL-2,
6727-109858-02 suggesting that the IFN-γ released by the activated T cells is stimulating the IFNG chimeric receptors leading to enhanced tumor cell killing by the IFNG chimeric receptor expressing T cells. It will be apparent that the precise details of the methods or compositions described may be varied or modified without departing from the spirit of the described aspects of the disclosure. We claim all such modifications and variations that fall within the scope and spirit of the claims below.
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTE DPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASS CSSALASKPSPEGASAASFEYTILDPSSQLLRP Domain Source Residues of 2
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLILTLSLILVVILVLLTVLALLSHRRALKQKIWPGIPSPESEFEGLFTTHKGNFQLWLYQNDGCLWWSPCTPFTE DPPASLEVLSERCWGTMQAVEPGTDDEGPLLEPVGSEHAQDTYLVLDKWLLPRNPPSEDLPGPGGSVDIVAMDEGSEASS CSSALASKPSPEGASAASFEYTILDPSSQLLRP Domain Source Residues of 2
 IFNGR1-GHRtm (SEQ ID NO: 3) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFPWLLIIIFGIFGLTVMLFVFLFSKQQRIKMLILPPVPVPKIKGIDPDLLKEGKLEEVNTILAIHDSYKPEFHSD DSWVEFIELDIDEPDEKTEESDTDRLLSSDHEKSHSNLGVKDGDSGRTSCCEPDILETDFNANDIHEGTSEVAQPQRLKG EADLLCLDQKNQNNSPYHDACPATQQPSVIQAEKNKPQPLPTEGAESTHQAAHIQLSNPSSLSNIDFYAQVSDITPAGSV VLSPGQKNKAGMSQCDMHPEMVSLCQENFLMDNAYFCEADAKKCIPVAPHIKVESHIQPSLNQEDIYITTESLTTAAGRP GTGEHVPGSEMPVPDYTSIHIVQSPQGLILNATALPLPDKEFLSSCGYVSTDQLNKIMP Domain Source Residues of
IFNGR1-GHRtm (SEQ ID NO: 3) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFPWLLIIIFGIFGLTVMLFVFLFSKQQRIKMLILPPVPVPKIKGIDPDLLKEGKLEEVNTILAIHDSYKPEFHSD DSWVEFIELDIDEPDEKTEESDTDRLLSSDHEKSHSNLGVKDGDSGRTSCCEPDILETDFNANDIHEGTSEVAQPQRLKG EADLLCLDQKNQNNSPYHDACPATQQPSVIQAEKNKPQPLPTEGAESTHQAAHIQLSNPSSLSNIDFYAQVSDITPAGSV VLSPGQKNKAGMSQCDMHPEMVSLCQENFLMDNAYFCEADAKKCIPVAPHIKVESHIQPSLNQEDIYITTESLTTAAGRP GTGEHVPGSEMPVPDYTSIHIVQSPQGLILNATALPLPDKEFLSSCGYVSTDQLNKIMP Domain Source Residues of
 6727-109858-02 Transmembrane GHR 246-269 Intracellular GHR 270-619
6727-109858-02 Transmembrane GHR 246-269 Intracellular GHR 270-619
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPS LLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQP Domain Source Residues of SEQ ID NO: 4
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPS LLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQP Domain Source Residues of SEQ ID NO: 4
 IFNGR1-LEPRtm (SEQ ID NO: 6) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWEDVPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLE PETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVCISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSK PSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQAFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDK KSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIRVLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHK IMENKMCDLTV Domain Source Residues of
IFNGR1-LEPRtm (SEQ ID NO: 6) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWEDVPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLE PETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVCISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSK PSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQAFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDK KSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIRVLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHK IMENKMCDLTV Domain Source Residues of
 6727-109858-02 Transmembrane LEPR 246-268 Intracellular LEPR 269-571
6727-109858-02 Transmembrane LEPR 246-268 Intracellular LEPR 269-571
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFILISSLAILLMVSLLLLSLWKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVAL Domain Source Residues of SEQ ID NO: 7
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFILISSLAILLMVSLLLLSLWKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVAL Domain Source Residues of SEQ ID NO: 7
 IFNGR1-IL3Ratm (SEQ ID NO: 9) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTSLLIALGTLLALVCVFVICRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKT Domain Source Residues of
IFNGR1-IL3Ratm (SEQ ID NO: 9) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTSLLIALGTLLALVCVFVICRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKT Domain Source Residues of
 6727-109858-02 IFNGR1-IL2Rbtm (SEQ ID NO: 10) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIPWLGHLLVGLSGAFGFIILVYLLINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSP GGLAPEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEG VAGAPTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPP TPGVPDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHL Domain Source Residues of SEQ ID NO: 10
6727-109858-02 IFNGR1-IL2Rbtm (SEQ ID NO: 10) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIPWLGHLLVGLSGAFGFIILVYLLINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSP GGLAPEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEG VAGAPTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPP TPGVPDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHL Domain Source Residues of SEQ ID NO: 10
 IFNGR1-CD28 (SEQ ID NO: 15) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS Domain Source Residues of
IFNGR1-CD28 (SEQ ID NO: 15) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS Domain Source Residues of
 6727-109858-02 IFNGR1-CD28_YMFM (SEQ ID NO: 16) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMFMTPRRPGPTRKHYQPYAPPRDFAAYRS Domain Source Residues of SEQ ID NO: 16
6727-109858-02 IFNGR1-CD28_YMFM (SEQ ID NO: 16) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMFMTPRRPGPTRKHYQPYAPPRDFAAYRS Domain Source Residues of SEQ ID NO: 16
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL Domain Source Residues of SEQ ID NO: 17
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL Domain Source Residues of SEQ ID NO: 17
 - Q : MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL Domain Source Residues of 8
- Q : MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL Domain Source Residues of 8
 IFNGR1-CD2 (SEQ ID NO: 19) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIYLIIGICGGGSLLMVFVALLVFYITKRKKQRSRRNDEELETRAHRVATEERGRKPHQIPASTPQNPATSQHPPP PPGHRSQAPSHRPPPPGHRVQHQPQKRPPAPSGTQVHQQKGPPLPRPRVQPKPPHGAAENSLSPSSN
6727-109858-02 Domain Source Residues of SEQ ID NO: 19
IFNGR1-CD2 (SEQ ID NO: 19) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIYLIIGICGGGSLLMVFVALLVFYITKRKKQRSRRNDEELETRAHRVATEERGRKPHQIPASTPQNPATSQHPPP PPGHRSQAPSHRPPPPGHRVQHQPQKRPPAPSGTQVHQQKGPPLPRPRVQPKPPHGAAENSLSPSSN
6727-109858-02 Domain Source Residues of SEQ ID NO: 19
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLLIVTIVATMLVLAVTVTSLCSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNEL LPNLEKEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNSLILILLEPIP QYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKLTEQAKK Domain Source Residues of SEQ ID NO: 20
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLLIVTIVATMLVLAVTVTSLCSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNEL LPNLEKEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNSLILILLEPIP QYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKLTEQAKK Domain Source Residues of SEQ ID NO: 20
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGALVSGMCCALFLLILLTGVLCHRFHGLWYMKMMWAWLQAKRKPRKAPSRNICYDAFVSYSERDAYWVENLMVQEL ENFNPPFKLCLHKRDFIPGKWIIDNIIDSIEKSHKTVFVLSENFVKSEWCKYELDFSHFRLFDENNDAAILILLEPIEKK AIPQRFCKLRKIMNTKTYLEWPMDEAQREGFWVNLRAAIKS Domain Source Residues of 1
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGALVSGMCCALFLLILLTGVLCHRFHGLWYMKMMWAWLQAKRKPRKAPSRNICYDAFVSYSERDAYWVENLMVQEL ENFNPPFKLCLHKRDFIPGKWIIDNIIDSIEKSHKTVFVLSENFVKSEWCKYELDFSHFRLFDENNDAAILILLEPIEKK AIPQRFCKLRKIMNTKTYLEWPMDEAQREGFWVNLRAAIKS Domain Source Residues of 1
 IFNGR1-TLR4 (SEQ ID NO: 22) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLC LHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELY RLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI Domain Source Residues of 2
IFNGR1-TLR4 (SEQ ID NO: 22) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGTIIGVSVLSVLVVSVVAVLVYKFYFHLMLLAGCIKYGRGENIYDAFVIYSSQDEDWVRNELVKNLEEGVPPFQLC LHYRDFIPGVAIAANIIHEGFHKSRKVIVVVSQHFIQSRWCIFEYEIAQTWQFLSSRAGIIFIVLQKVEKTLLRQQVELY RLLSRNTYLEWEDSVLGRHIFWRRLRKALLDGKSWNPEGTVGTGCNWQEATSI Domain Source Residues of 2
 6727-109858-02 Extracellular IFNGR1 1-245 Transmembrane TLR4 246-266
6727-109858-02 Extracellular IFNGR1 1-245 Transmembrane TLR4 246-266
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIVTIGATMLVLAVTVTSLCIYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSEHDSAWVKSELV PYLEKEDIQICLHERNFVPGKSIVENIINCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLEPIPQ NSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKS Domain Source Residues of SEQ ID NO: 23
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIVTIGATMLVLAVTVTSLCIYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSEHDSAWVKSELV PYLEKEDIQICLHERNFVPGKSIVENIINCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFHEGSNNLILILLEPIPQ NSIPNKYHKLKALMTQRTYLQWPKEKSKRGLFWANIRAAFNMKLTLVTENNDVKS Domain Source Residues of SEQ ID NO: 23
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIATGMVGALLLLLVVALGIGLFMRRRHIVRKRTLRRLLQERELVEPLTPSGEAPNQALLRILKETEFKKIKVLGS GAFGTVYKGLWIPEGEKVKIPVAIKELREATSPKANKEILDEAYVMASVDNPHVCRLLGICLTSTVQLITQLMPFGCLLD YVREHKDNIGSQYLLNWCVQIAKGMNYLEDRRLVHRDLAARNVLVKTPQHVKITDFGLAKLLGAEEKEYHAEGGKVPIKW MALESILHRIYTHQSDVWSYGVTVWELMTFGSKPYDGIPASEISSILEKGERLPQPPICTIDVYMIMVKCWMIDADSRPK FRELIIEFSKMARDPQRYLVIQGDERMHLPSPTDSNFYRALMDEEDMDDVVDADEYLIPQQGFFSSPSTSRTPLLSSLSA TSNNSTVACIDRNGLQSCPIKEDSFLQRYSSDPTGALTEDSIDDTFLPVPEYINQSVPKRPAGSVQNPVYHNQPLNPAPS RDPHYQDPHSTAVGNPEYLNTVQPTCVNSTFDSPAHWAQKGSHQISLDNPDYQQDFFPKEAKPNGIFKGSTAENAEYLRV APQSSEFIGA Domain Source Residues of SEQ
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIATGMVGALLLLLVVALGIGLFMRRRHIVRKRTLRRLLQERELVEPLTPSGEAPNQALLRILKETEFKKIKVLGS GAFGTVYKGLWIPEGEKVKIPVAIKELREATSPKANKEILDEAYVMASVDNPHVCRLLGICLTSTVQLITQLMPFGCLLD YVREHKDNIGSQYLLNWCVQIAKGMNYLEDRRLVHRDLAARNVLVKTPQHVKITDFGLAKLLGAEEKEYHAEGGKVPIKW MALESILHRIYTHQSDVWSYGVTVWELMTFGSKPYDGIPASEISSILEKGERLPQPPICTIDVYMIMVKCWMIDADSRPK FRELIIEFSKMARDPQRYLVIQGDERMHLPSPTDSNFYRALMDEEDMDDVVDADEYLIPQQGFFSSPSTSRTPLLSSLSA TSNNSTVACIDRNGLQSCPIKEDSFLQRYSSDPTGALTEDSIDDTFLPVPEYINQSVPKRPAGSVQNPVYHNQPLNPAPS RDPHYQDPHSTAVGNPEYLNTVQPTCVNSTFDSPAHWAQKGSHQISLDNPDYQQDFFPKEAKPNGIFKGSTAENAEYLRV APQSSEFIGA Domain Source Residues of SEQ
 IFNGR1-IGF1R (SEQ ID NO: 25) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIIALPVAVLLIVGGLVIMLYVFHRKRNNSRLGNGVLYASVNPEYFSAADVYVPDEWEVAREKITMSRELGQGSF GMVYEGVAKGVVKDEPETRVAIKTVNEAASMRERIEFLNEASVMKEFNCHHVVRLLGVVSQGQPTLVIMELMTRGDLKSY LRSLRPEMENNPVLAPPSLSKMIQMAGEIADGMAYLNANKFVHRDLAARNCMVAEDFTVKIGDFGMTRDIYETDYYRKGG KGLLPVRWMSPESLKDGVFTTYSDVWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQ YNPKMRPSFLEIISSIKEEMEPGFREVSFYYSEENKLPEPEELDLEPENMESVPLDPSASSSSLPLPDRHSGHKAENGPG PGVLVLRASFDERQPYAHMNGGRKNERALPLPQSSTC
6727-109858-02 Domain Source Residues of SEQ ID NO: 25
IFNGR1-IGF1R (SEQ ID NO: 25) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGLIIALPVAVLLIVGGLVIMLYVFHRKRNNSRLGNGVLYASVNPEYFSAADVYVPDEWEVAREKITMSRELGQGSF GMVYEGVAKGVVKDEPETRVAIKTVNEAASMRERIEFLNEASVMKEFNCHHVVRLLGVVSQGQPTLVIMELMTRGDLKSY LRSLRPEMENNPVLAPPSLSKMIQMAGEIADGMAYLNANKFVHRDLAARNCMVAEDFTVKIGDFGMTRDIYETDYYRKGG KGLLPVRWMSPESLKDGVFTTYSDVWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQ YNPKMRPSFLEIISSIKEEMEPGFREVSFYYSEENKLPEPEELDLEPENMESVPLDPSASSSSLPLPDRHSGHKAENGPG PGVLVLRASFDERQPYAHMNGGRKNERALPLPQSSTC
6727-109858-02 Domain Source Residues of SEQ ID NO: 25
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPS LLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQPRAKRSGSGATN FSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQ VQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPE NIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIF RVGHLSNISCYETMADASTELQQISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAA LSPPKATVSDTCEEVEPSLLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLP LSYWQQP Domain Source Residues of SEQ ID NO: 31
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAALSPPKATVSDTCEEVEPS LLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLPLSYWQQPRAKRSGSGATN FSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQ VQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPE NIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIF RVGHLSNISCYETMADASTELQQISLVTALHLVLGLSAVLGLLLLRWQFPAHYRRLRHALWPSLPDLHRVLGQYLRDTAA LSPPKATVSDTCEEVEPSLLEILPKSSERTPLPLCSSQAQMDYRRLQPSCLGTMPLSVCPPMAESGSCCTTHIANHSYLP LSYWQQP Domain Source Residues of SEQ ID NO: 31
 6727-109858-02 Transmembrane-1 PRLR 246-269 Intracellular-1 PRLR 270-633
6727-109858-02 Transmembrane-1 PRLR 246-269 Intracellular-1 PRLR 270-633
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWEDVPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLE PETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVCISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSK PSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQAFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDK KSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIRVLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHK IMENKMCDLTVRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYN AEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGAL HSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNL KPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWED VPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLEPETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVC ISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSKPSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQ AFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDKKSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIR VLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHKIMENKMCDLTV Domain Source Residues of E ID N 3
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWEDVPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLE PETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVCISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSK PSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQAFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDK KSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIRVLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHK IMENKMCDLTVRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYN AEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGAL HSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNL KPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQAGLYVIVPVIISSSILLLGTLLISHQRMKKLFWED VPNPKNCSWAQGLNFQKPETFEHLFIKHTASVTCGPLLLEPETISEDISVDTSWKNKDEMMPTTVVSLLSTTDLEKGSVC ISDQFNSVNFSEAEGTEVTYEDESQRQPFVKYATLISNSKPSETGEEQGLINSSVTKCFSSKNSPLKDSFSNSSWEIEAQ AFFILSDQHPNIISPHLTFSEGLDELLKLEGNFPEENNDKKSIYYLGVTSIKKRESGVLLTDKSRVSCPFPAPCLFTDIR VLQDSCSHFVENNINLGTSSKKTFASYMPQFQTCSTQTHKIMENKMCDLTV Domain Source Residues of E ID N 3
 IFNGR1-2-INSRtm (SEQ ID NO: 36) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIIGPLIFVFLFSVVIGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQ GSFGMVYEGNARDIIKGEAETRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDL KSYLRSLRPEAENNPGRPPPTLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYR KGGKGLLPVRWMAPESLKDGVFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRM CWQFNPKMRPTFLEIVNLLKDDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGF
6727-109858-02 KRSYEEHIPYTHMNGGKKNGRILTLPRSNPSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAA PPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPS AGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEK GGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQIIIGPLIFVFLFSVV IGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQGSFGMVYEGNARDIIKGEAE TRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDLKSYLRSLRPEAENNPGRPPP TLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYRKGGKGLLPVRWMAPESLKDG VFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRMCWQFNPKMRPTFLEIVNLLK DDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGFKRSYEEHIPYTHMNGGKKNG RILTLPRSNPS Domain Source Residues of SEQ ID NO: 36
IFNGR1-2-INSRtm (SEQ ID NO: 36) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIIGPLIFVFLFSVVIGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQ GSFGMVYEGNARDIIKGEAETRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDL KSYLRSLRPEAENNPGRPPPTLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYR KGGKGLLPVRWMAPESLKDGVFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRM CWQFNPKMRPTFLEIVNLLKDDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGF
6727-109858-02 KRSYEEHIPYTHMNGGKKNGRILTLPRSNPSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAA PPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPS AGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEK GGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQIIIGPLIFVFLFSVV IGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSREKITLLRELGQGSFGMVYEGNARDIIKGEAE TRVAVKTVNESASLRERIEFLNEASVMKGFTCHHVVRLLGVVSKGQPTLVVMELMAHGDLKSYLRSLRPEAENNPGRPPP TLQEMIQMAAEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYRKGGKGLLPVRWMAPESLKDG VFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDNCPERVTDLMRMCWQFNPKMRPTFLEIVNLLK DDLHPSFPEVSFFHSEENKAPESEELEMEFEDMENVPLDRSSHCQREEAGGRDGGSSLGFKRSYEEHIPYTHMNGGKKNG RILTLPRSNPS Domain Source Residues of SEQ ID NO: 36
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRAKRSGS GATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRP VVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTV GPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNK SNIFRVGHLSNISCYETMADASTELQQFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKH YQPYAPPRDFAAYRS Domain Source Residues of SEQ ID NO: 42
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRAKRSGS GATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRP VVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTV GPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNK SNIFRVGHLSNISCYETMADASTELQQFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKH YQPYAPPRDFAAYRS Domain Source Residues of SEQ ID NO: 42
 6727-109858-02 Transmembrane-1 IGF1R 246-266 Intracellular-1 IGF1R 267-677
6727-109858-02 Transmembrane-1 IGF1R 246-266 Intracellular-1 IGF1R 267-677
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIRFCGIYGYRLRRKWEEKIPNPSKSHLFQNGSAELWPPGSMSAFTSGSPPHQGPW GSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQPPSPQPGPPAASHTPEKQASSFDFNGPYL GPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAMGPGQAVEVERRPSQGAAGSPSLESGGGP APPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGASSVSLVPSLGLPSDQTPSLCPGLASGPPG APGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPTSPQPEGLLVLQQVGDYCFLPGLGPGPLS LRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLPPWEVNKPGEVCRAKRSGSGATNFSLLKQ AGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYT DSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTP GEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLS NISCYETMADASTELQQVILISVGTFSLLSVLAGACFFKRFLRIQRLFPPVPQIKDKLNDNHEVEDEIIWEEFTPEEGKG YREEVLTVKEIT Domain Source Residues of SE ID NO 52
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIRFCGIYGYRLRRKWEEKIPNPSKSHLFQNGSAELWPPGSMSAFTSGSPPHQGPW GSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQPPSPQPGPPAASHTPEKQASSFDFNGPYL GPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAMGPGQAVEVERRPSQGAAGSPSLESGGGP APPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGASSVSLVPSLGLPSDQTPSLCPGLASGPPG APGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPTSPQPEGLLVLQQVGDYCFLPGLGPGPLS LRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLPPWEVNKPGEVCRAKRSGSGATNFSLLKQ AGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYT DSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTP GEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLS NISCYETMADASTELQQVILISVGTFSLLSVLAGACFFKRFLRIQRLFPPVPQIKDKLNDNHEVEDEIIWEEFTPEEGKG YREEVLTVKEIT Domain Source Residues of SE ID NO 52
 IFNGR1tm-IL3RA_IFNGR2tm-CSF2RB (SEQ ID NO: 55) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKTR AKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVAL SNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQH YRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQA QLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFRFCGIYGYRLRRKWEEKIPNPSKSHL FQNGSAELWPPGSMSAFTSGSPPHQGPWGSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQP
6727-109858-02 PSPQPGPPAASHTPEKQASSFDFNGPYLGPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAM GPGQAVEVERRPSQGAAGSPSLESGGGPAPPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGAS SVSLVPSLGLPSDQTPSLCPGLASGPPGAPGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPT SPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLP PWEVNKPGEVC Domain Source Residues of SEQ ID NO: 55
IFNGR1tm-IL3RA_IFNGR2tm-CSF2RB (SEQ ID NO: 55) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIRRYLVMQRLFPRIPHMKDPIGDSFQNDKLVVWEAGKAGLEECLVTEVQVVQKTR AKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVAL SNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQH YRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQA QLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFRFCGIYGYRLRRKWEEKIPNPSKSHL FQNGSAELWPPGSMSAFTSGSPPHQGPWGSRFPELEGVFPVGFGDSEVSPLTIEDPKHVCDPPSGPDTTPAASDLPTEQP
6727-109858-02 PSPQPGPPAASHTPEKQASSFDFNGPYLGPPHSRSLPDILGQPEPPQEGGSQKSPPPGSLEYLCLPAGGQVQLVPLAQAM GPGQAVEVERRPSQGAAGSPSLESGGGPAPPALGPRVGGQDQKDSPVAIPMSSGDTEDPGVASGYVSSADLVFTPNSGAS SVSLVPSLGLPSDQTPSLCPGLASGPPGAPGPVKSGFEGYVELPPIEGRSPRSPRNNPVPPEAKSPVLNPGERPADVSPT SPQPEGLLVLQQVGDYCFLPGLGPGPLSLRSKPSSPGPGPEIKNLDQAFQVKKPPGQAVPQVPVIQLFKALKQQDYLSLP PWEVNKPGEVC Domain Source Residues of SEQ ID NO: 55
 _ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVALRAKRSGSGATNFSLL KQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFK YTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEV TPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGH LSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFL DCQIHRVDDIQARDEVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSS SRSLDCRESGKNGPHVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQ Domain Source Residues of 6
_ MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFIKLWRVKKFLIPSVPDPKSIFPGLFEIHQGNFQEWITDTQNVAHLHKMAGAEQES GPEEPLVVQLAKTEAESPRMLDPQTEEKEASGGSLQLPHQPLQGGDVVTIGGFTFVMNDRSYVALRAKRSGSGATNFSLL KQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFK YTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEV TPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGH LSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFL DCQIHRVDDIQARDEVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSS SRSLDCRESGKNGPHVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQ Domain Source Residues of 6
 IFNGR1tm-IL2RB_IFNGR2tm-IL2RG (SEQ ID NO: 57) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSPGGLA PEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEGVAGA
6727-109858-02 PTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPPTPGV PDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHLRAKRSGSGA TNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVV YQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGP PENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSN IFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGL AESLQPDYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 57
IFNGR1tm-IL2RB_IFNGR2tm-IL2RG (SEQ ID NO: 57) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFINCRNTGPWLKKVLKCNTPDPSKFFSQLSSEHGGDVQKWLSSPFPSSSFSPGGLA PEISPLEVLERDKVTQLLLQQDKVPEPASLSSNHSLTSCFTNQGYFFFHLPDALEIEACQVYFTYDPYSEEDPDEGVAGA
6727-109858-02 PTGSSPQPLQPLSGEDDAYCTFPSRDDLLLFSPSLLGGPSPPSTAPGGSGAGEERMPPSLQERVPRDWDPQPLGPPTPGV PDLVDFQPPPELVLREAGEEVPDAGPREGVSFPWSRPPGQGEFRALNARLPLNTDAYLSLQELQGQDPTHLRAKRSGSGA TNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVV YQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGP PENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSN IFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGL AESLQPDYSERLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 57
 IFNGR1tm-IL7RA_IFNGR2tm-IL2RG (SEQ ID NO: 59) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN
6727-109858-02 SSIKGSLWIPVVAALLLFLVLSLVFIKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFLDCQIHRVDDIQARD EVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSSSRSLDCRESGKNGP HVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQRAKRSGSGATNFSLLKQAG DVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDS KWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGE GSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNI SCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSE RLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 59
IFNGR1tm-IL7RA_IFNGR2tm-IL2RG (SEQ ID NO: 59) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN
6727-109858-02 SSIKGSLWIPVVAALLLFLVLSLVFIKKRIKPIVWPSLPDHKKTLEHLCKKPRKNLNVSFNPESFLDCQIHRVDDIQARD EVEGFLQDTFPQQLEESEKQRLGGDVQSPNCPSEDVVITPESFGRDSSLTCLAGNVSACDAPILSSSRSLDCRESGKNGP HVYQDLLLSLGTTNSTLPPPFSLQSGILTLNPVAQGQPILTSLGSNQEEAYVTMSSFYQNQRAKRSGSGATNFSLLKQAG DVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDS KWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGE GSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNI SCYETMADASTELQQVILISVGTFSLLSVLAGACFFERTMPRIPTLKNLEDLVTEYHGNFSAWSGVSKGLAESLQPDYSE RLCLVSEIPPKGGALGEGPGASPCNQHSPYWAPPCYTLKPET Domain Source Residues of SEQ ID NO: 59
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLGILSFLGLVAGALALGLWLRLRRGGKDGSPKPGFLASVIPVDRRPGAPNLRAKRSGSGATNFSLLKQAGDVEE NPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFT ADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLI IRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYE TMADASTELQQAIVVPVCLAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNF TDVSVVEIEANDKKPFPEDLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYR HQVPSVQVFSRSESTQPLLDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRL KQQISDHISQSCGSGQMKMFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of SEQ ID NO: 63
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLGILSFLGLVAGALALGLWLRLRRGGKDGSPKPGFLASVIPVDRRPGAPNLRAKRSGSGATNFSLLKQAGDVEE NPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFT ADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLI IRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYE TMADASTELQQAIVVPVCLAFLLTTLLGVLFCFNKRDLIKKHIWPNVPDPSKSHIAQWSPHTPPRHNFNSKDQMYSDGNF TDVSVVEIEANDKKPFPEDLKSLDLFKKEKINTEGHSSGIGGSSCMSSSRPSISSSDENESSQNTSSTVQYSTVVHSGYR HQVPSVQVFSRSESTQPLLDSEERPEDLQLVDHVDGGDGILPRQQYFKQNCSQHESSPDISHFERSKQVSSVNEEDFVRL KQQISDHISQSCGSGQMKMFQEVSAADAFGPGTEGQVERFETVGMEAATDEGMPKSYLPQTVRQGGYMPQ Domain Source Residues of SEQ ID NO: 63
 6727-109858-02 Extracellular-2 IFNGR2 547-793 Transmembrane-2 GP130 794-815
6727-109858-02 Extracellular-2 IFNGR2 547-793 Transmembrane-2 GP130 794-815
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGVIIFFAFVLLLSGALAYCLALQLYVRRRKKLPSVLLFKKPSPFIFISQRPSPETQDTIHPLDEEAFLKVSPELKN LDLHGSTDSGFGSTKPSLQTEEPQFLLPDPHPQADRTLGNREPPVLGDSCSSGSSNSTDSGICLQEPSLSPSTGPTWEQQ VGSNSRGQDDSGIDLVQNSEGRAGDTQGGSALGHHSPPEPEVPGEEDPAAVAFQGYLRQTRCAEEKATKTGCLEEESPLT DGLGPKFGRCLVDEAGLHPPALAKGYLKQDPLEMTLASSGAPTGQWNQPTEEWSLLALSSCSDLGISDWSFAHDLAPLGC VAAPGGLLGSFNSDLVTLPLISSLQSSERAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPD PLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGF PMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGI QQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQWMVAVILMASVFMVCLAL LGCFALLWCVYKKTKYAFSPRNSLPQHLKEFLGHPHHNTLLFFSFPLSDENDVFDKLSVIAEDSESGKQNPGDSCSLGTP PGQGPQS Domain Source Residues of SEQ ID NO: 65
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGVIIFFAFVLLLSGALAYCLALQLYVRRRKKLPSVLLFKKPSPFIFISQRPSPETQDTIHPLDEEAFLKVSPELKN LDLHGSTDSGFGSTKPSLQTEEPQFLLPDPHPQADRTLGNREPPVLGDSCSSGSSNSTDSGICLQEPSLSPSTGPTWEQQ VGSNSRGQDDSGIDLVQNSEGRAGDTQGGSALGHHSPPEPEVPGEEDPAAVAFQGYLRQTRCAEEKATKTGCLEEESPLT DGLGPKFGRCLVDEAGLHPPALAKGYLKQDPLEMTLASSGAPTGQWNQPTEEWSLLALSSCSDLGISDWSFAHDLAPLGC VAAPGGLLGSFNSDLVTLPLISSLQSSERAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPD PLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGF PMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGI QQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQWMVAVILMASVFMVCLAL LGCFALLWCVYKKTKYAFSPRNSLPQHLKEFLGHPHHNTLLFFSFPLSDENDVFDKLSVIAEDSESGKQNPGDSCSLGTP PGQGPQS Domain Source Residues of SEQ ID NO: 65
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIFWYVLPVSITVFLFSVMGYSIYRYIHVGKEKHPANLILIYGNEFDKRFFVPAEKIVINFITLNISDDSKISHQ DMSLLGKSSDVSSLNDPQPSGNLRPPQEEEEVKHLGYASHLMEIFCDSEENTEGTSLTQQESLSRTIPPDKTVIEYEYDV RTTDICAGPEEQELSLQEEVSTQGTLLESQAALAVLGPQTLQYSYTPQLQDLDPLAQEHTDSEEGPEEEPSTTLVDWDPQ TGRLCIPSLSSFDQDSEGCEPSEGDGLGEEGLLSRLYEEPAPDRPPGENETYLMQFMEEWGLYVQMENRAKRSGSGATNF SLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQV QFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPEN IEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFR VGHLSNISCYETMADASTELQQVLALFAFVGFMLILVVVPLFVWKMGRLLQYSCCPVVVLPDTLKITNSPQKLISCRREE VDACATAVMSPEELLRAWIS Domain Source Residues of SEQ ID NO: 67
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGIIFWYVLPVSITVFLFSVMGYSIYRYIHVGKEKHPANLILIYGNEFDKRFFVPAEKIVINFITLNISDDSKISHQ DMSLLGKSSDVSSLNDPQPSGNLRPPQEEEEVKHLGYASHLMEIFCDSEENTEGTSLTQQESLSRTIPPDKTVIEYEYDV RTTDICAGPEEQELSLQEEVSTQGTLLESQAALAVLGPQTLQYSYTPQLQDLDPLAQEHTDSEEGPEEEPSTTLVDWDPQ TGRLCIPSLSSFDQDSEGCEPSEGDGLGEEGLLSRLYEEPAPDRPPGENETYLMQFMEEWGLYVQMENRAKRSGSGATNF SLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAEQVLSWEPVALSNSTRPVVYQV QFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHSAWVTMPWFQHYRNVTVGPPEN IEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKPSRVYCLQVQAQLLWNKSNIFR VGHLSNISCYETMADASTELQQVLALFAFVGFMLILVVVPLFVWKMGRLLQYSCCPVVVLPDTLKITNSPQKLISCRREE VDACATAVMSPEELLRAWIS Domain Source Residues of SEQ ID NO: 67
 IFNGR1-2RB-S5_IFNGR2 (SEQ ID NO: 68) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDAYLSLDVLVDLLVDDSGKESLIGYR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of 8
IFNGR1-2RB-S5_IFNGR2 (SEQ ID NO: 68) MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDAYLSLDVLVDLLVDDSGKESLIGYR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of 8
 6727-109858-02 Transmembrane-1 IFNGR1 246-266 Intracellular-1 IFNGR1-2RB-S5 267-489
6727-109858-02 Transmembrane-1 IFNGR1 246-266 Intracellular-1 IFNGR1-2RB-S5 267-489
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDAYLSLDVLVDLLVDDSGKESLIGFR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 69
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDAYLSLDVLVDLLVDDSGKESLIGFR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 69
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPMDNAYFCEAVLVDLLVDDSGKEQEDIYI TTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 71
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPMDNAYFCEAVLVDLLVDDSGKEQEDIYI TTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 71
 MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDTYLVLDVLVDLLVDDSGKESLIGYR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 73
MALLFLLPLVMQGVSRAEMGTADLGPSSVPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINI SHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVD YDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFN SSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEV VCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSR NCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSDTYLVLDVLVDLLVDDSGKESLIGYR PTEDSKEFSRAKRSGSGATNFSLLKQAGDVEENPGPMRPTLLWSLLLLLGVFAAAAAAPPDPLSQLPAPQHPKIRLYNAE QVLSWEPVALSNSTRPVVYQVQFKYTDSKWFTADIMSIGVNCTQITATECDFTAASPSAGFPMDFNVTLRLRAELGALHS AWVTMPWFQHYRNVTVGPPENIEVTPGEGSLIIRFSSPFDIADTSTAFFCYYVHYWEKGGIQQVKGPFRSNSISLDNLKP SRVYCLQVQAQLLWNKSNIFRVGHLSNISCYETMADASTELQQVILISVGTFSLLSVLAGACFFLVLKYRGLIKYWFHTP PSIPLQIEEYLKDPTQPILEALDKDSSPKDDVWDSVSIISFPEKEQEDVLQTL Domain Source Residues of SEQ ID NO: 73