
- The paper "K2: A Foundation Language Model for Geoscience Knowledge Understanding and Utilization" has been accepted by WSDM2024, in Mexico!
- Code and data for paper "K2: A Foundation Language Model for Geoscience Knowledge Understanding and Utilization"
- Demo: https://k2.acemap.info host by ourselves on a single GeForce RTX 3090 with intranet penetration (with only three threads, with max length as 512)
- A larger language model for Geoscience as a foundation model for academic copilot is geogalactica!
- The data pre-processing toolkits are open-sourced on sciparser!
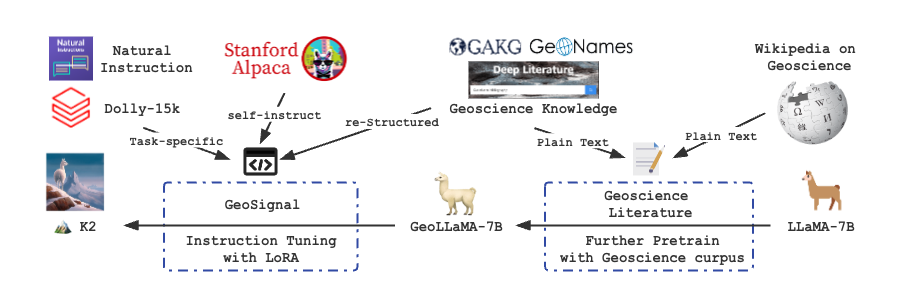
We introduce K2 (7B), an open-source language model trained by firstly further pretraining LLaMA on collected and cleaned geoscience literature, including geoscience open-access papers and Wikipedia pages, and secondly fine-tuning with knowledge-intensive instruction tuning data (GeoSignal). As for preliminary evaluation, we use GeoBench (consisting of NPEE and AP Test on Geology, Geography, and Environmental Science) as the benchmark. K2 outperforms the baselines on objectiv e and subjective tasks compared to several baseline models with similar parameters. In this repository, we will share the following code and data.
- We release K2 weights in two parts (one can add our delta to the original LLaMA weights and use
peft_modelwithtransformersto obtain the entire K2 model.)- Delta weights after further pretraining with the geoscience text corpus to comply with the LLaMA model license.
- Adapter model weights trained by PEFT (LoRA).
- We release the core data of GeoSignal that K2 used for the training.
- We release the GeoBench, the first-ever benchmark for the evaluation of the capability of LLMs in geoscience.
- We release the code of further pretrain and instruction tuning of K2.
The following is the overview of training K2:
1. Prepare the code and the environment
Clone our repository, create a Python environment, and activate it via the following command
git clone https://github.com/davendw49/k2.git
cd k2
conda env create -f k2.yaml
conda activate k22. Prepare the pretrained K2 (GeoLLaMA)
The current version of K2 is on Huggingface Model The previous version of K2 consists of two parts: a delta model (like Vicuna), an add-on weight towards LLaMA-7B, and an adapter model (trained via PEFT).
| Delta model | Adapter model | Full model |
|---|---|---|
| k2_fp_delta | k2_it_adapter | k2_v1 |
- Referring to the repo of Vicuna, we share the command of building up the pretrained weighted of K2
python -m apply_delta --base /path/to/weights/of/llama --target /path/to/weights/of/geollama/ --delta daven3/k2_fp_deltaComing soon...
3. Use K2
base_model = /path/to/k2
tokenizer = LlamaTokenizer.from_pretrained(base_model)
model = LlamaForCausalLM.from_pretrained(
base_model,
load_in_8bit=load_8bit,
device_map=device_map
torch_dtype=torch.float16
)
model.config.pad_token_id = tokenizer.pad_token_id = 0
model.config.bos_token_id = 1
model.config.eos_token_id = 2Or, alternatively,
base_model = /path/to/geollama
lora_weights = /path/to/adapter/model
tokenizer = LlamaTokenizer.from_pretrained(base_model)
model = LlamaForCausalLM.from_pretrained(
base_model,
load_in_8bit=load_8bit,
device_map=device_map
torch_dtype=torch.float16
)
model = PeftModel.from_pretrained(
model,
lora_weights,
torch_dtype=torch.float16,
device_map=device_map,
)
model.config.pad_token_id = tokenizer.pad_token_id = 0
model.config.bos_token_id = 1
model.config.eos_token_id = 2- More detail are in
./generation/
In this repo, we share the instruction data and benchmark data:
- GeoSignal:
./data/geosignal/ - GeoBench:
./data/geobench/
Our text corpus for further pretraining on LLaMA-7B consists of 3.9 billion tokens from geoscience papers published in selected high-quality journals in earth science and mainly collected by GAKG.
Delta Model on Hugging Face: daven3/k2_fp_delta
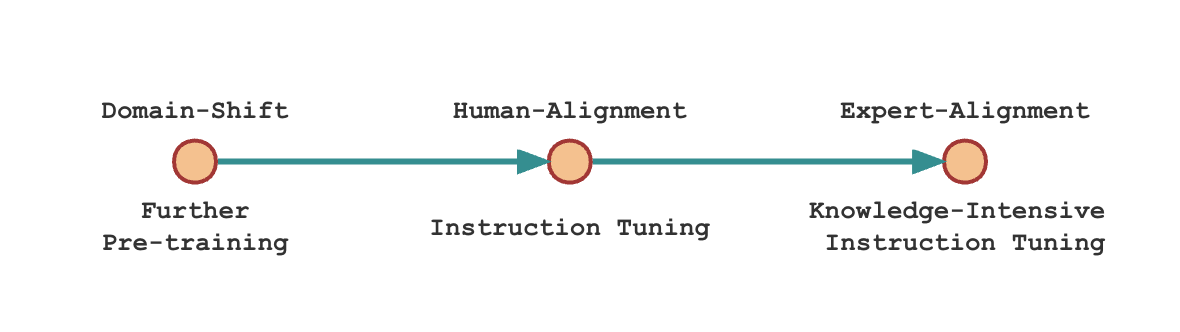
Scientific domain adaptation has two main steps during instruction tuning.
- Instruction tuning with general instruction-tuning data. Here we use Alpaca-GPT4.
- Instruction tuning with restructured domain knowledge, which we call expertise instruction tuning. For K2, we use knowledge-intensive instruction data, GeoSignal.
The following is the illustration of the training domain-specific language model recipe:
- Adapter Model on Hugging Face: daven3/k2_it_adapter
- Dataset on Hugging Face: geosignal
In GeoBench, we collect 183 multiple-choice questions in NPEE, and 1,395 in AP Test, for objective tasks. Meanwhile, we gather all 939 subjective questions in NPEE to be the subjective tasks set and use 50 to measure the baselines with human evaluation.
- Dataset on Hugging Face: geobench
The training script is run_clm.py
deepspeed --num_gpus=4 run_clm.py --deepspeed ds_config_zero.json >log 2>&1 &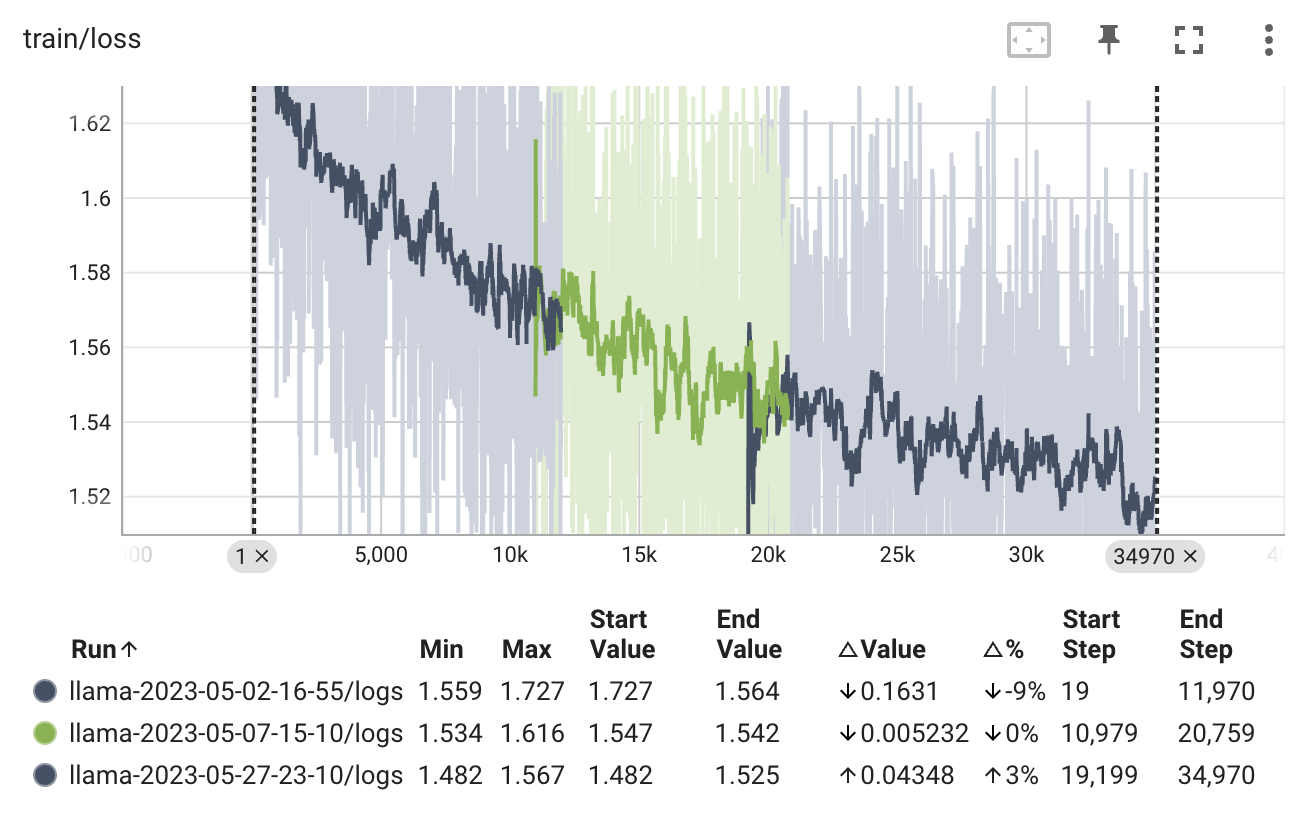
The parameters we use:
- Batch size per device: 2
- Global batch size: 128 (2*4gpu*16gradient accumulation steps)
- Number of trainable parameters: 6738415616 (7b)
- lr: 1e-5
- bf16: true
- tf32: true
- Warmup: 0.03/3 epoch (nearly 1000 steps)
- Zero_optimization_stage: 3
Tips: We can not resume smoothly from checkpoints for the limited computing power. Therefore, we did not load the optimizer state dict when resuming training. Even though there are two noticeable spikes in the diagram, the performance seems to stay at normal.
The training script is finetune.py
- For the first step: is alignment with human
python finetune.py --base_model /path/to/checkpoint-30140 --data_path /path/to/alpaca.json --output_dir /path/to/stage/one/model/ --cuda_id 2 --lora_target_modules "q_proj" "k_proj" "v_proj"- For the second step: alignment with expert
python finetune.py --base_model /path/to/checkpoint-30140 --data_path /path/to/geosignal.json --output_dir /path/to/stage/two/model/ --cuda_id 2 --lora_target_modules "q_proj" "k_proj" "v_proj" --resume_from_checkpoint /path/to/stage/one/model/- batch_size: 128
- micro batch size: 4
- num epochs: 1
- learning rate: 3e-4
- cutoff len: 512
- val set size: 2000
- lora r: 8
- lora alpha: 16
- lora dropout: 0.05
- lora target modules: ["q_proj", "k_proj", "v_proj"]
| Case 1 | Case 2 | Case 3 |
|---|---|---|
 |
 |
 |
- Answer:
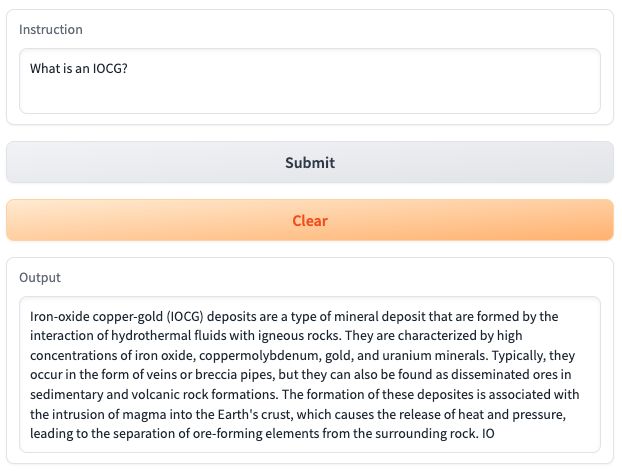
- Question: What is an IOCG?
- Answer: Iron-oxide copper-gold (IOCG) deposits are a type of mineral deposit that are formed by the interaction of hydrothermal fluids with igneous rocks. They are characterized by high concentrations of iron oxide, coppermolybdenum, gold, and uranium minerals. Typically, they occur in the form of veins or breccia pipes, but they can also be found as disseminated ores in sedimentary and volcanic rock formations. The formation of these deposites is associated with the intrusion of magma into the Earth's crust, which causes the release of heat and pressure, leading to the separation of ore-forming elements from the surrounding rock. IO
- Answer and Explain:
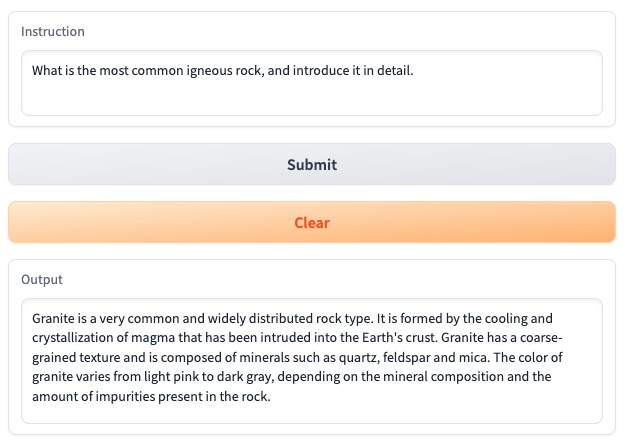
- Question: What is the most common igneous rock, and introduce it in detail.
- Answer: Granite is a very common and widely distributed rock type. It is formed by the cooling and crystallization of magma that has been intruded into the Earth's crust. Granite has a coarse-grained texture and is composed of minerals such as quartz, feldspar and mica. The color of granite varies from light pink to dark gray, depending on the mineral composition and the amount of impurities present in the rock.
- Answer with comparison:
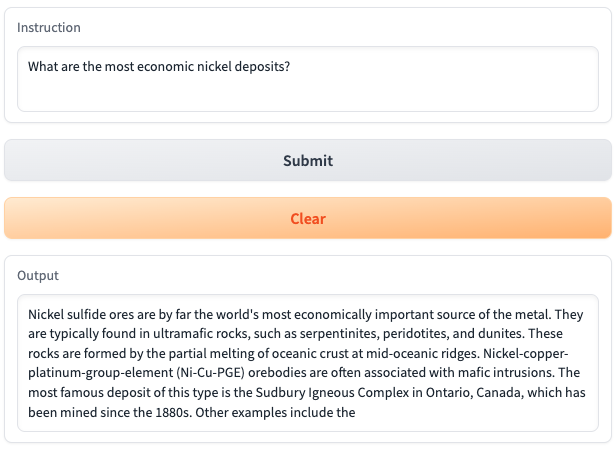
- Question: What are the most economic nickel deposits?
- Answer: Nickel sulfide ores are by far the world's most economically important source of the metal. They are typically found in ultramafic rocks, such as serpentinites, peridotites, and dunites. These rocks are formed by the partial melting of oceanic crust at mid-oceanic ridges. Nickel-copper-platinum-group-element (Ni-Cu-PGE) orebodies are often associated with mafic intrusions. The most famous deposit of this type is the Sudbury Igneous Complex in Ontario, Canada, which has been mined since the 1880s. Other examples include the
We share the original evaluation code in evaluation folder, and we will release Geo-Eval in the near future with more evaluation methods.
K2 is originally from the name of the second-highest mountain in the world, and we believe that in the future, larger and more powerful geoscience language models will be created. What is more, to train a model to shift to a discipline with a significant domain barrier, we have encountered many difficulties (collecting corpus, clean academic data, computing power, ...), which shares with the fact that climbing K2 is no less challenging than Mount Everest 🏔️.
This project was founded by Acemap at Shanghai Jiao Tong University, including Cheng Deng, Tianhang Zhang, Zhongmou He, Qiyuan Chen, Yuanyuan Shi, Le Zhou, supervised by Weinan Zhang, Luoyi Fu, Zhouhan Lin, Junxian He, and Xinbing Wang. The whole project is supported by Chenghu Zhou and the Institute of Geographical Science, Natural Resources Research, Chinese Academy of Sciences.
K2 has referred to the following open-source projects. We want to express our gratitude and respect to the researchers of the projects.
- Facebook LLaMA: https://github.com/facebookresearch/llama
- Stanford Alpaca: https://github.com/tatsu-lab/stanford_alpaca
- alpaca-lora by @tloen: https://github.com/tloen/alpaca-lora
- alpaca-gp4 by Chansung Park: tloen/alpaca-lora#340
K2 is under the support of Chenghu Zhou and the Institute of Geographical Science, Natural Resources Research, Chinese Academy of Sciences.
We would also like to express our appreciation for the effort of data processing from Yutong Xu and Beiya Dai.
K2 is a research preview intended for non-commercial use only, subject to the model License of LLaMA and the Terms of Use of the data generated by OpenAI. Please contact us if you find any potential violations. The code is released under the Apache License 2.0. The data GeoSignal and GeoBench is updating occasionally, if you want to subscribe the data, you can emaill us davendw@sjtu.edu.cn.
Citation ArXiv
If you use the code or data of K2, please declare the reference with the following:
@misc{deng2023learning,
title={K2: A Foundation Language Model for Geoscience Knowledge Understanding and Utilization},
author={Cheng Deng and Tianhang Zhang and Zhongmou He and Yi Xu and Qiyuan Chen and Yuanyuan Shi and Luoyi Fu and Weinan Zhang and Xinbing Wang and Chenghu Zhou and Zhouhan Lin and Junxian He},
year={2023},
eprint={2306.05064},
archivePrefix={arXiv},
primaryClass={cs.CL}
}