This is the official code release for our CVPR21 paper on unsupervised detection and tracking. It produces results slightly better than reported in the paper.
[Paper] [Project Page]

We use ensemble agreement between 2d and 3d models, as well as motion cues, to unsupervisedly learn object detectors from scratch. Top: 3d detections. Middle: 2d segmentation. Bottom-left: unprojected 2d segmentation, in a bird's eye view. Bottom-right: 3d detections, in a bird's eye view.
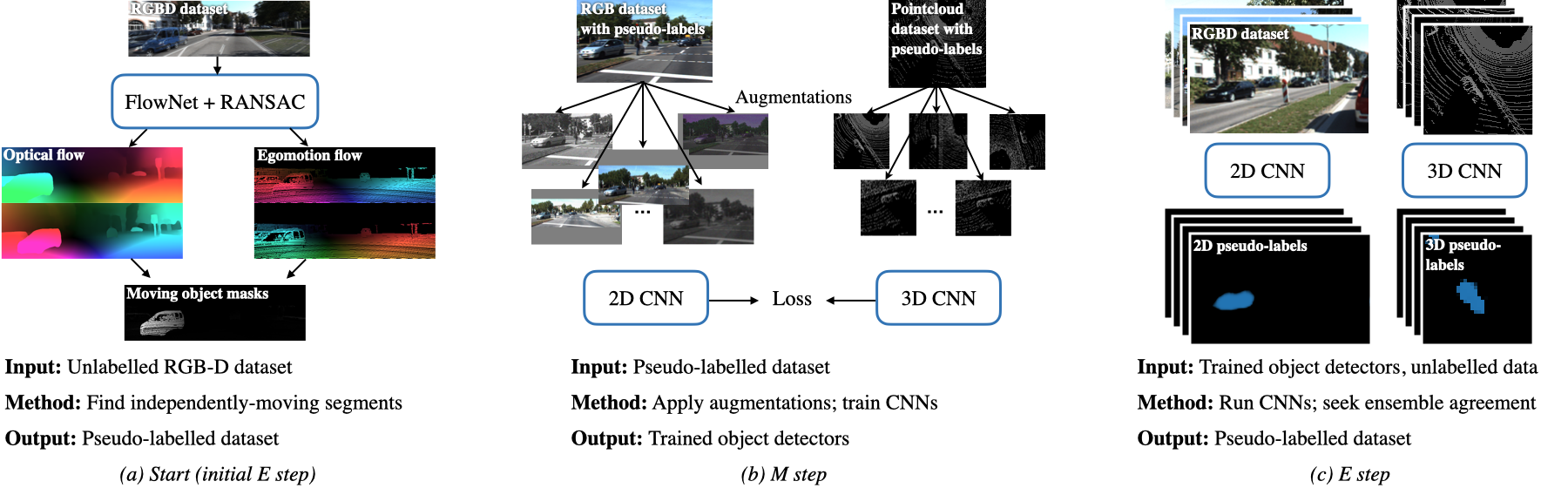
An EM approach to unsupervised tracking. We present an expectation-maximization (EM) method, which takes RGBD videos as input, and produces object detectors and trackers as output. (a) We begin with a handcrafted E step, which uses optical flow and egomotion to segment a small number of objects moving independently from the background. (b) Next, as an M step, we treat these segmented objects as pseudo-labels, and train 2D and 3D convolutional nets to detect these objects under heavy data augmentation. (c) We then use the learned detectors as an ensemble to re-label the data (E step), and loop.
pip install -r requirements.txt
Also, download a RAFT model, and put its path into tcr_kitti_discover.py and tcr_kitti_ensemble.py. In this repo, we use raft-sintel.pth. Code for running RAFT is already included in this repo (in nets/raftnet.py and nets/raft_core).
In this repo we focus on the KITTI dataset. We use sequences 0000-0009 for training, and sequences 0010-0011 for testing. If you are familiar with KITTI, you can swap out simplekittidataset.py with your own dataloader.
To use our dataloader, download kitti_prep.tar.gz (12g), untar it somewhere, and update the root_dir in simplekittidataset.py.
Our prepared npzs include (up to) 1000 2-frame snippets from each sequence. (Some sequences are less than 1000 frames long.) Each npz has the following data:
rgb_camXs # S,3,H,W = 2,3,256,832; uint8; image data from color camera 2
xyz_veloXs # S,V,3 = 2,130000,3; float32; velodyne pointcloud
cam_T_velos # S,4,4 = 2,4,4; float32; 4x4 that moves points from velodyne to camera
rect_T_cams # S,4,4 = 2,4,4; float32; 4x4 that moves points from camera to rectified
pix_T_rects # S,4,4 = 2,4,4; float32; 4x4 that moves points from rectified to pixels
boxlists # S,N,9 = 2,50,9; float32; 3d box info: cx,cy,cz,lx,ly,lz,rx,ry,rz
tidlists # S,N = 2,50; int32; unique ids
clslists # S,N = 2,50; int32; classes
scorelists # S,N = 2,50; float32; valid mask for boxes
We use S for sequence length, H,W are for image height and width, V is the maximum number of points in the velodyne pointcloud, and N is the maximum number of annotated objects.
In this data, and throughout the code, we use the following convention:
p_ais a point namedpliving inacoordinates.a_T_bis a transformation that takes points from coordinate systembto coordinate systema.
For example, p_a = a_T_b * p_b.
Download a pre-trained model here: model-000050000.pth (19.4mb).
This model is the result of 5 rounds of EM, trained in this repo. It outperforms the best model reported in the paper.
| mAP@IOU | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 |
|---|---|---|---|---|---|---|---|
| Paper | 0.40 | 0.38 | 0.35 | 0.33 | 0.31 | 0.23 | 0.06 |
| This repo | 0.58 | 0.58 | 0.54 | 0.48 | 0.42 | 0.29 | 0.10 |
| mAP@IOU | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 |
|---|---|---|---|---|---|---|---|
| Paper | 0.43 | 0.4 | 0.37 | 0.35 | 0.33 | 0.30 | 0.21 |
| This repo | 0.60 | 0.59 | 0.59 | 0.56 | 0.49 | 0.40 | 0.23 |
The method in this repo is slightly different and easier to "get working" than the method in the paper.
We improve the model in the following ways:
-
We use 2d BEV convs in the 3d CenterNet model, instead of 3d convs. This allows higher resolution and a deeper model.
-
We estimate 3d segmentation in addition to centerness, and use this in the ensemble. The connected components step depends on accurate shape estimation, so the 3d segmentation here makes more sense than the centerness heatmap, and leads to finding boxes that are much closer to ground truth. We implement this simply by adding new channels to the CenterNet.
-
We replace the additive ensemble with a multiplicative one. Previously, we added together all our signals (independent motion, 2d objectness, 3d objectness, occupancy), and tuned a threshold on this sum. Now, we multiply everything together: a region is only considered an object if (1) it is moving independently, and (2) the 2d segmentor fired, and (3) the 3d segmentor fired, and (4) it is occupied. This gives lower recall but higher precision, and it reduces drift.
-
We eliminate center-surround saliency scoring/thresholding (Equation 7 in the CVPR paper). Previously, center-surround saliency was critical for discarding pseudo-labels that cut an object in half. In the current version (thanks to the multiplicative ensemble and segmentation estimates), this happens less frequently, so we are able to remove this step. This is good news, because tuning the threshold on center-surround saliency was tricky in the original work. Note that a type of center-surround still exists, since we only take objects that are moving independently from their background.
Initial E step:
py tcr_kitti_discover.py --output_name="stage1"
This will output "stage1" npzs into tcr_pseudo/.
M step:
py tcr_kitti_train_2d.py --input_name="stage1" --max_iters=10000
py tcr_kitti_train_3d.py --input_name="stage1" --max_iters=10000
This will train 2d and 3d models on those pseudo-labels, and save checkpoints into checkpoints/. The 3d model will also occasionally evaluate itself against ground truth.
E step:
py tcr_kitti_ensemble.py \
--init_dir_2d=your_2d_model_folder \
--init_dir_3d=your_3d_model_folder \
--log_freq=1 \
--shuffle=False \
--export_npzs=True \
--output_name="stage2" \
--exp_name="go" \
--skip_to=0 \
--max_iters=3837
This will use the 2d and 3d models along with motion cues to output "stage2" npzs into tcr_pseudo/:
Then repeat the M and E steps, updating the input/output names as the stages progress. We find it is helpful in later stages to train for longer (e.g., 20k or 50k iterations, instead of 10k.)
py tcr_kitti_eval.py --init_dir_3d=your_3d_model_folder
This will print out some information while it runs, like this:
...
eval_08_1e-3_kitti3d_s5ti_go50k_17:43:11_16:46:20; step 000511/665; rtime 0.01; itime 1.38; map@0.1 0.45; map@0.3 0.42; map@0.5 0.25; map@0.7 0.08
eval_08_1e-3_kitti3d_s5ti_go50k_17:43:11_16:46:20; step 000512/665; rtime 0.00; itime 1.38; map@0.1 0.44; map@0.3 0.42; map@0.5 0.25; map@0.7 0.08
eval_08_1e-3_kitti3d_s5ti_go50k_17:43:11_16:46:20; step 000513/665; rtime 0.00; itime 1.30; map@0.1 0.44; map@0.3 0.42; map@0.5 0.25; map@0.7 0.08
...
It will end by printing out a summary like this (for the provided checkpoint):
----------
BEV accuracy summary:
map@iou=0.1: 0.58
map@iou=0.2: 0.58
map@iou=0.3: 0.54
map@iou=0.4: 0.48
map@iou=0.5: 0.42
map@iou=0.6: 0.29
map@iou=0.7: 0.10
----------
perspective accuracy summary:
map@iou=0.1: 0.60
map@iou=0.2: 0.59
map@iou=0.3: 0.59
map@iou=0.4: 0.56
map@iou=0.5: 0.49
map@iou=0.6: 0.40
map@iou=0.7: 0.23
----------
If you use this code for your research, please cite:
Track, Check, Repeat: An EM Approach to Unsupervised Tracking. Adam W. Harley, Yiming Zuo, Jing Wen, Shubhankar Potdar, Ritwick Chaudhry, Katerina Fragkiadaki. In CVPR 2021.
Bibtex:
@inproceedings{harley2021track,
title={Track, check, repeat: An EM approach to unsupervised tracking},
author={Harley, Adam W and Zuo, Yiming and Wen, Jing and Mangal, Ayush and Potdar, Shubhankar and Chaudhry, Ritwick and Fragkiadaki, Katerina},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2021}
}