摘要: 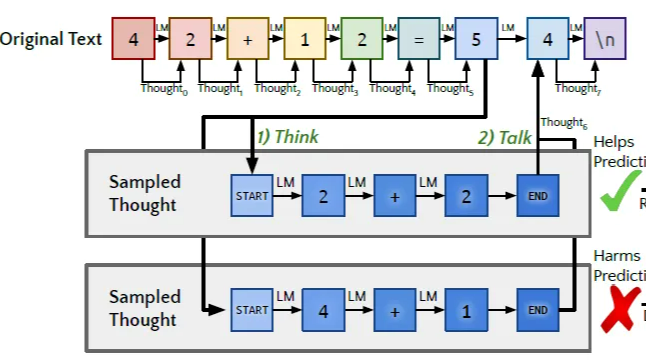 想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。 阅读全文
想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。 阅读全文
摘要:  这一章我们介绍GraphRAG范式,Graph RAG虽好但并非RAG的Silver Bullet,它有特定适合的问题和场景,更适合作为RAG中的一路召回,用来解决实体密集,依赖全局关系的信息召回。所以这一章我们来聊聊GraphRAG的实现和具体解决哪些问题。 阅读全文
这一章我们介绍GraphRAG范式,Graph RAG虽好但并非RAG的Silver Bullet,它有特定适合的问题和场景,更适合作为RAG中的一路召回,用来解决实体密集,依赖全局关系的信息召回。所以这一章我们来聊聊GraphRAG的实现和具体解决哪些问题。 阅读全文
摘要: 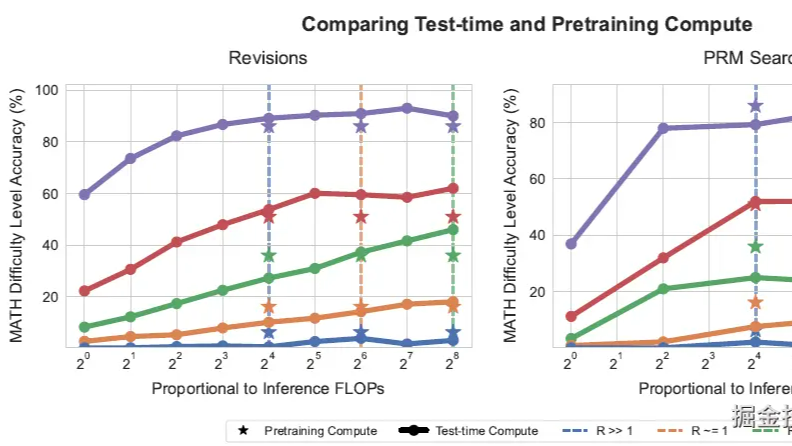 OpenAI的O-1出现前,其实就有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向Inference Scaling的转变,这一章我们挑3篇inference-scaling相关的论文来聊聊,前两篇分别从聚合策略和搜索策略来优化广度推理,最后一篇全面的分析了各类广度深度推理策略的最优使用方案。 阅读全文
OpenAI的O-1出现前,其实就有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向Inference Scaling的转变,这一章我们挑3篇inference-scaling相关的论文来聊聊,前两篇分别从聚合策略和搜索策略来优化广度推理,最后一篇全面的分析了各类广度深度推理策略的最优使用方案。 阅读全文
摘要:  RAG这一章我们集中看下精排的部分。粗排和精排的主要差异其实在于效率和效果的balance。粗排和精排的主要差异其实在于效率和效果的balance。粗排模型复杂度更低,需要承上启下,用较低复杂度的模型 阅读全文
RAG这一章我们集中看下精排的部分。粗排和精排的主要差异其实在于效率和效果的balance。粗排和精排的主要差异其实在于效率和效果的balance。粗排模型复杂度更低,需要承上启下,用较低复杂度的模型 阅读全文
摘要:  常见的多智能体框架有协作模式,路由模式,复杂交互模式等等,这一章我们围绕智能体路由,也就是如何选择解决当前任务最合适的智能体展开,介绍基于领域,问题复杂度,和用户偏好进行智能体选择的几种方案 阅读全文
常见的多智能体框架有协作模式,路由模式,复杂交互模式等等,这一章我们围绕智能体路由,也就是如何选择解决当前任务最合适的智能体展开,介绍基于领域,问题复杂度,和用户偏好进行智能体选择的几种方案 阅读全文
摘要:  前置判断模型回答是否需要联网,之前介绍了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种基于微调,模型回答置信度和小模型代理回答的方案。 阅读全文
前置判断模型回答是否需要联网,之前介绍了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种基于微调,模型回答置信度和小模型代理回答的方案。 阅读全文
摘要:  这一章我们就重点关注描述性指令优化。我们先简单介绍下结构化Prompt编写,再聊聊从结构化多角度进行Prompt最优化迭代的算法方案UniPrompt 阅读全文
这一章我们就重点关注描述性指令优化。我们先简单介绍下结构化Prompt编写,再聊聊从结构化多角度进行Prompt最优化迭代的算法方案UniPrompt 阅读全文
摘要:  这一章我们会先梳理DSPy相关的几篇核心论文了解下框架背后的设计思想和原理,然后以FinEval的单选题作为任务,从简单指令,COT指令,到采样Few-shot和优化指令给出代码示例和效果评估。 阅读全文
这一章我们会先梳理DSPy相关的几篇核心论文了解下框架背后的设计思想和原理,然后以FinEval的单选题作为任务,从简单指令,COT指令,到采样Few-shot和优化指令给出代码示例和效果评估。 阅读全文
摘要: 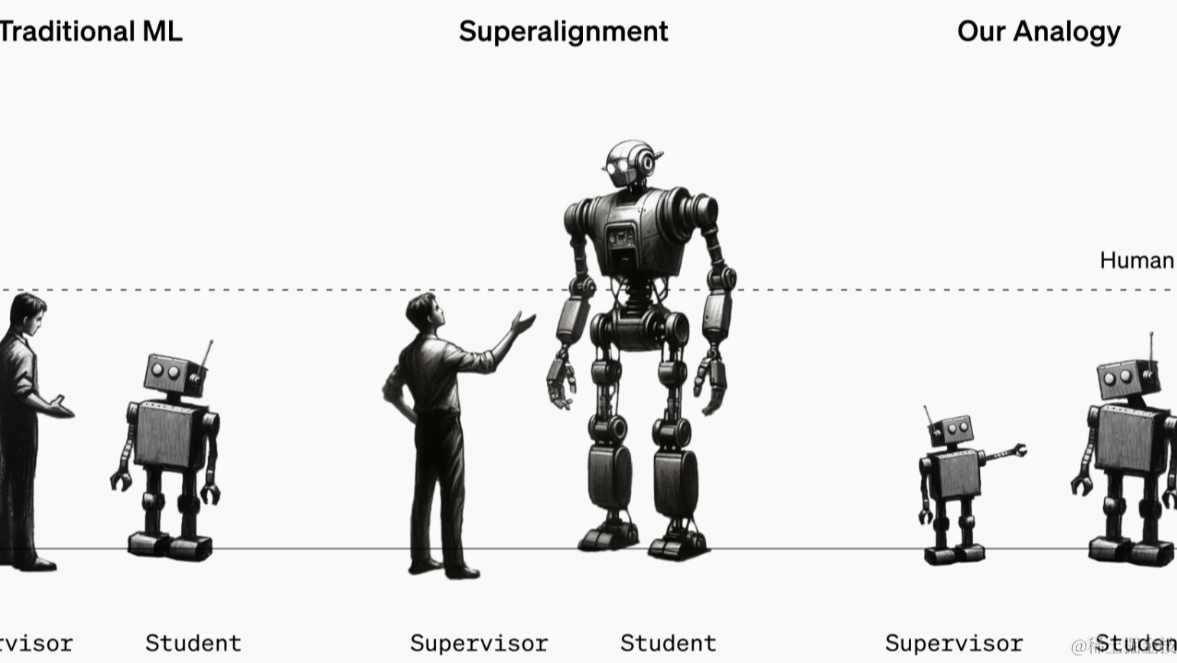 前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程 阅读全文
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程 阅读全文
摘要:  这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案 阅读全文
这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案 阅读全文