
上周分享了一篇《一个线程罢工的诡异事件》,最近也在公司内部分享了这个案例。
无独有偶,在内部分享的时候也有小伙伴问了之前分享时所提出的一类问题:
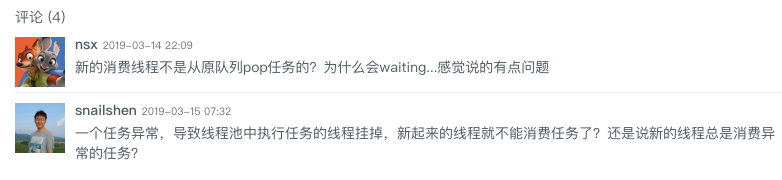
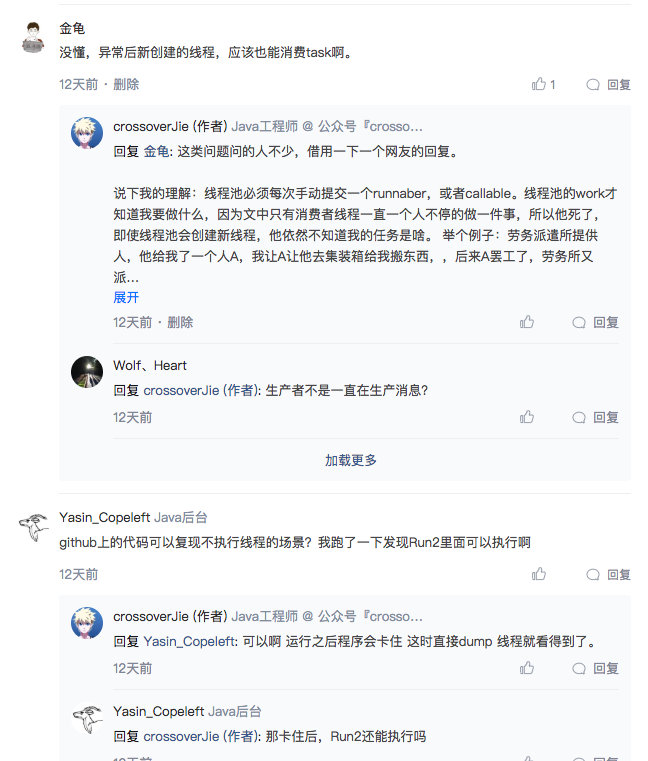
这其实是一类共性问题,我认为主要还是两个原因:
- 我自己确实也没讲清楚,之前画的那张图还需要再完善,有些误导。
- 第二还是大家对线程池的理解不够深刻,比如今天要探讨的内容。
首先还是来复习下线程池的基本原理。
我认为线程池它就是一个调度任务的工具。
众所周知在初始化线程池会给定线程池的大小,假设现在我们有 1000 个线程任务需要运行,而线程池的大小为 1020,在真正运行任务的过程中他肯定不会创建这1000个线程同时运行,而是充分利用线程池里这 1020 个线程来调度这1000个任务。
而这里的 10~20 个线程最后会由线程池封装为 ThreadPoolExecutor.Worker 对象,而这个 Worker 是实现了 Runnable 接口的,所以他自己本身就是一个线程。

这里我们来做一个模拟,创建了一个核心线程、最大线程数、阻塞队列都为2的线程池。
这里假设线程池已经完成了预热,也就是线程池内部已经创建好了两个线程 Worker。
当我们往一个线程池丢一个任务会发生什么事呢?
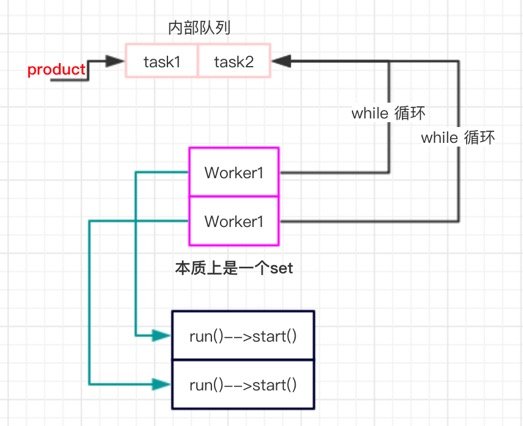
- 第一步是生产者,也就是任务提供者他执行了一个 execute() 方法,本质上就是往这个内部队列里放了一个任务。
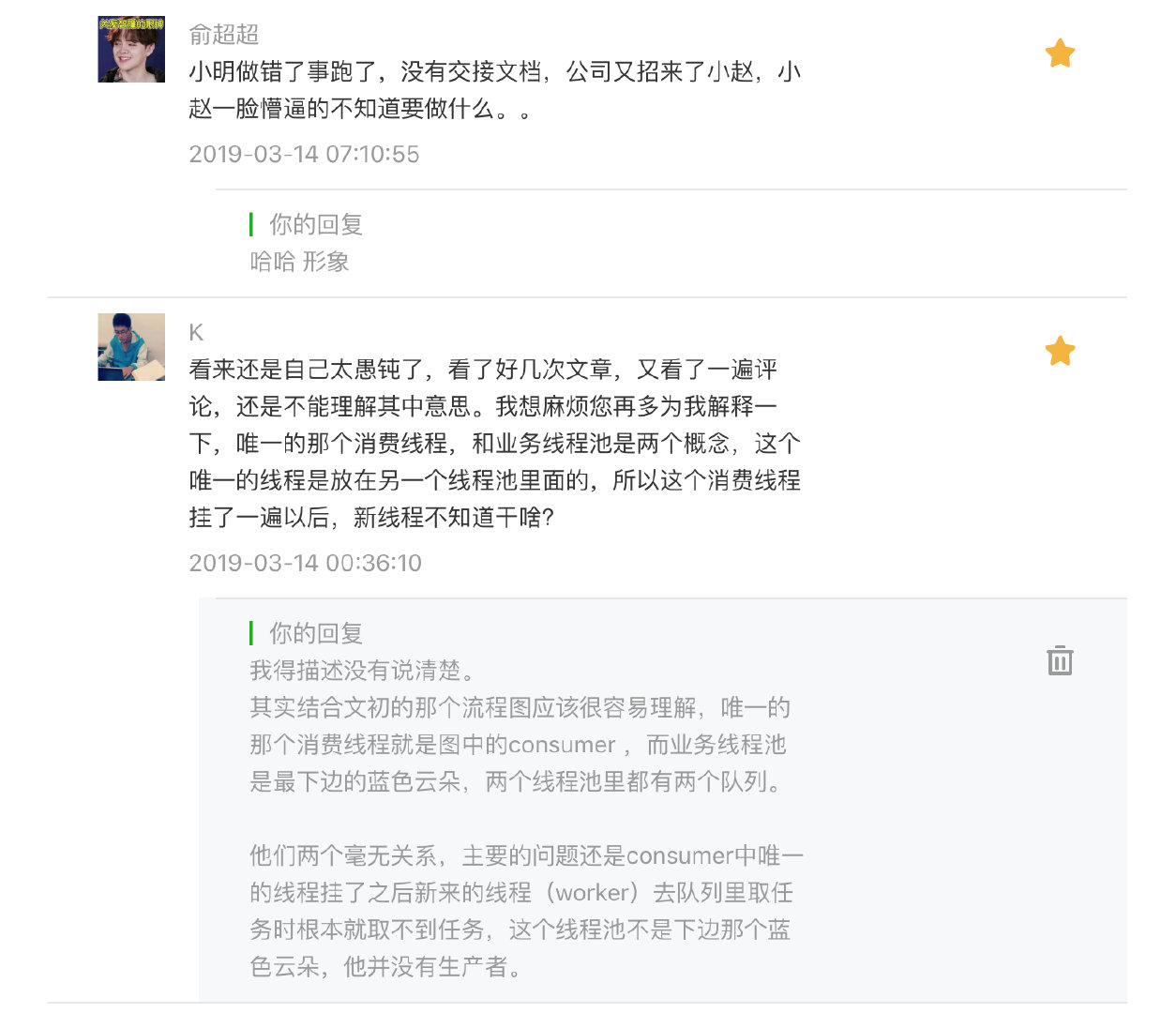
- 之前已经创建好了的 Worker 线程会执行一个
while循环 ---> 不停的从这个内部队列里获取任务。(这一步是竞争的关系,都会抢着从队列里获取任务,由这个队列内部实现了线程安全。) - 获取得到一个任务后,其实也就是拿到了一个
Runnable对象(也就是execute(Runnable task)这里所提交的任务),接着执行这个Runnable的 run() 方法,而不是 start(),这点需要注意后文分析原因。
结合源码来看:
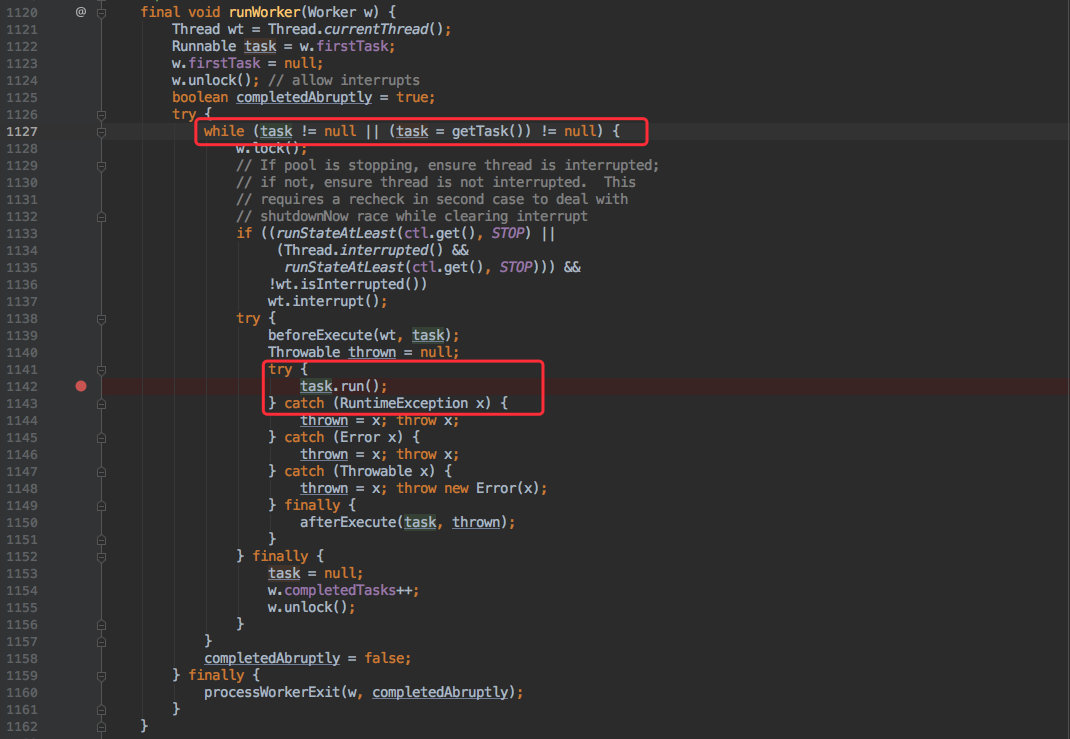
从图中其实就对应了刚才提到的二三两步:
while循环,从getTask()方法中一直不停的获取任务。- 拿到任务后,执行它的 run() 方法。
这样一个线程就调度完毕,然后再次进入循环从队列里取任务并不断的进行调度。
接下来回顾一下我们上一篇文章所提到的,导致一个线程没有运行的根本原因是:
在单个线程的线程池中一但抛出了未被捕获的异常时,线程池会回收当前的线程并创建一个新的
Worker; 它也会一直不断的从队列里获取任务来执行,但由于这是一个消费线程,根本没有生产者往里边丢任务,所以它会一直 waiting 在从队列里获取任务处,所以也就造成了线上的队列没有消费,业务线程池没有执行的问题。
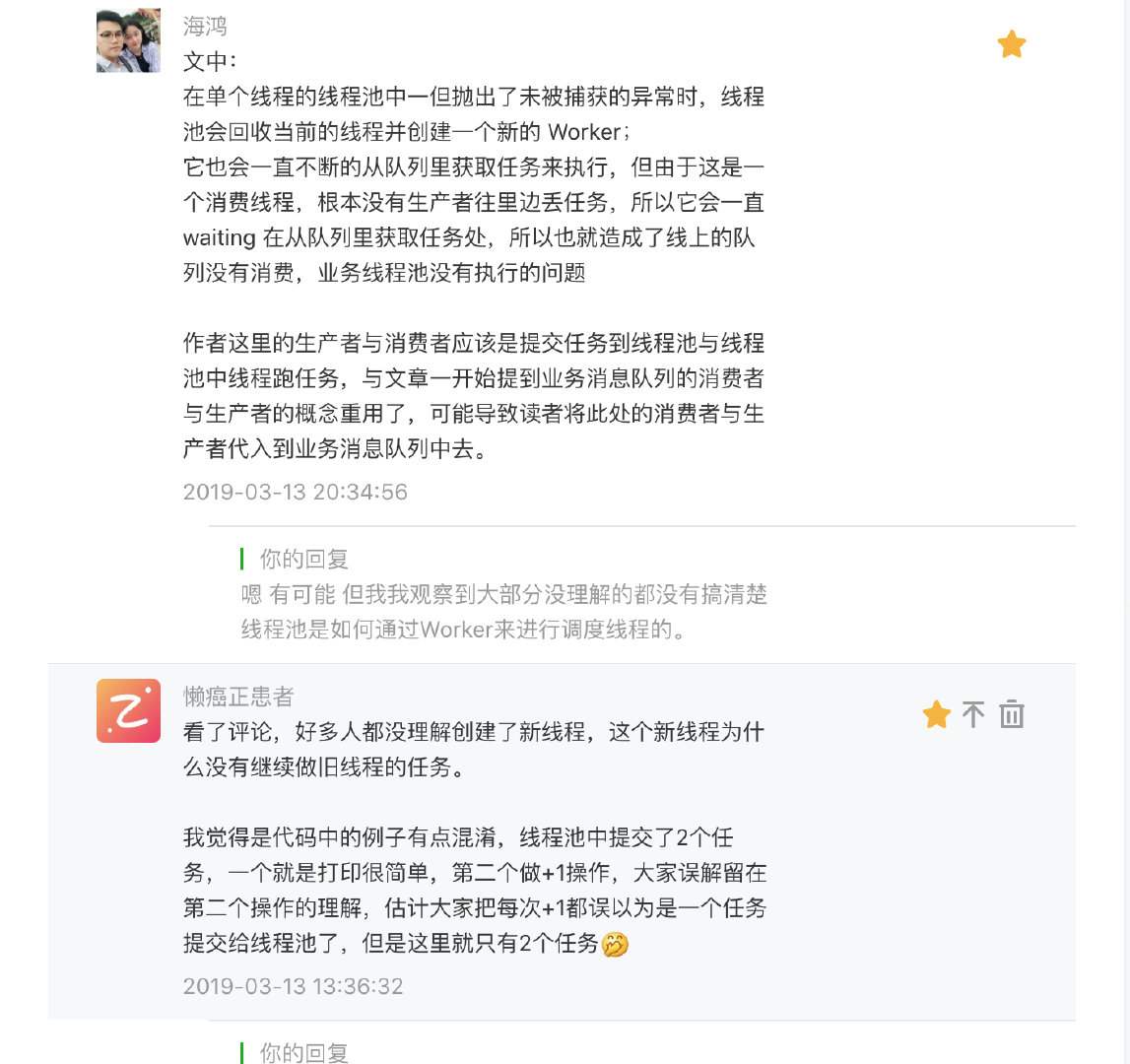
结合之前的那张图来看:
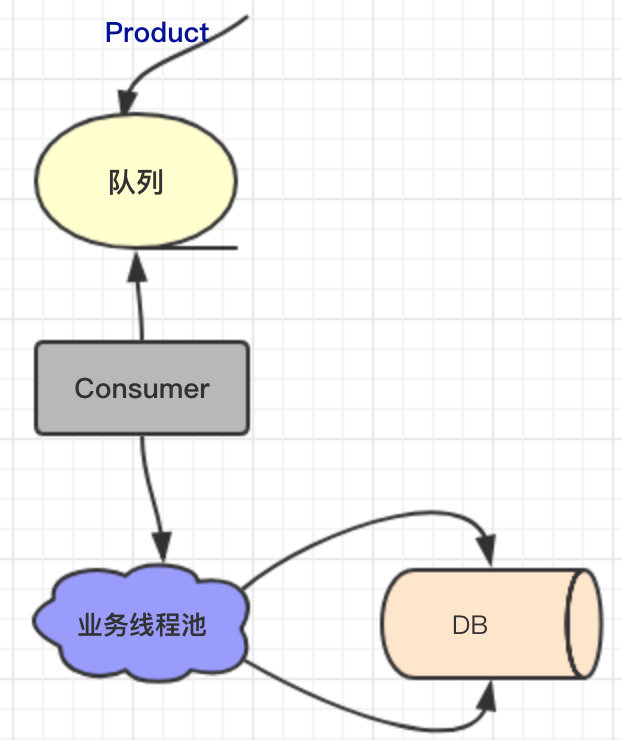
这里大家问的最多的一个点是,为什么会没有是根本没有生产者往里边丢任务,图中不是明明画的有一个 product 嘛?
这里确实是有些不太清楚,再次强调一次:
图中的 product 是往内部队列里写消息的生产者,并不是往这个 Consumer 所在的线程池中写任务的生产者。
因为即便 Consumer 是一个单线程的线程池,它依然具有一个常规线程池所具备的所有条件:
- Worker 调度线程,也就是线程池运行的线程;虽然只有一个。
- 内部的阻塞队列;虽然长度只有1。
再次结合图来看:
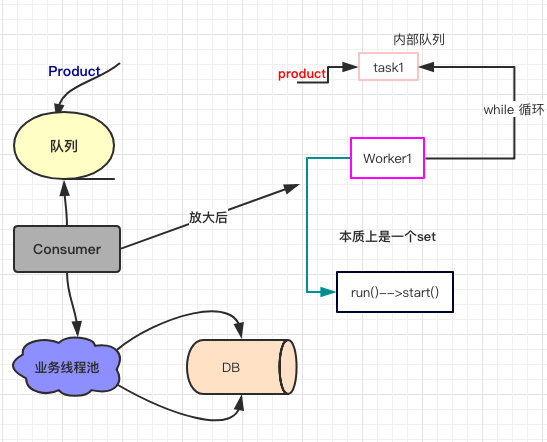
所以之前提到的【没有生产者往里边丢任务】是指右图放大后的那一块,也就是内部队列并没有其他线程往里边丢任务执行 execute() 方法。
而一旦发生未捕获的异常后,Worker1 被回收,顺带的它所调度的线程 task1(这个task1 也就是在执行一个 while 循环消费左图中的那个队列) 也会被回收掉。
新创建的 Worker2 会取代 Worker1 继续执行 while 循环从内部队列里获取任务,但此时这个队列就一直会是空的,所以也就是处于 Waiting 状态。
我觉得这波解释应该还是讲清楚了,欢迎还没搞明白的朋友留言讨论。
问题搞清楚后来想想为什么线程池在调度的时候执行的是 Runnable 的 run() 方法,而不是 start() 方法呢?
我相信大部分没有看过源码的同学心中第一个印象就应该是执行的 start() 方法;
因为不管是学校老师,还是网上大牛讲的都是只有执行了 start() 方法后操作系统才会给我们创建一个独立的线程来运行,而 run() 方法只是一个普通的方法调用。
而在线程池这个场景中却恰好就是要利用它只是一个普通方法调用。
回到我在文初中所提到的:我认为线程池它就是一个调度任务的工具。
假设这里是调用的 Runnable 的 start 方法,那会发生什么事情。
如果我们往一个核心、最大线程数为 2 的线程池里丢了 1000 个任务,那么它会额外的创建 1000 个线程,同时每个任务都是异步执行的,一下子就执行完毕了。
从而没法做到由这两个 Worker 线程来调度这 1000 个任务,而只有当做一个同步阻塞的 run() 方法调用时才能满足这个要求。
这事也让我发现一个奇特的现象:就是网上几乎没人讲过为什么在线程池里是 run 而不是 start,不知道是大家都觉得这是基操还是没人仔细考虑过。
针对之前线上事故的总结上次已经写得差不多了,感兴趣的可以翻回去看看。
这次呢可能更多是我自己的总结,比如写一篇技术博客时如果大部分人对某一个知识点讨论的比较热烈时,那一定是作者要么讲错了,要么没讲清楚。
这点确实是要把自己作为一个读者的角度来看,不然很容易出现之前的一些误解。
在这之外呢,我觉得对于线程池把这两篇都看完同时也理解后对于大家理解线程池,利用线程池完成工作也是有很大好处的。
如果有在面试中加分的记得回来点赞、分享啊。
你的点赞与分享是对我最大的支持